Intel at Hot Chips 2018: Showing the Ankle of Cascade Lake
by Ian Cutress on August 19, 2018 7:30 PM EST- Posted in
- CPUs
- Intel
- Spectre
- AVX-512
- Meltdown
- Cascade Lake
- Optane DIMMs
- VNNI
Purley Mark Two: Cascade Lake-SP
On the processor front, the on-paper hardware specifications of Cascade Lake Xeons offer no surprises, mainly because the stock design is identical to Skylake Xeons. Users will be offered up to 28 cores with hyperthreading, the same levels of cache, the same UPI connectivity, the same number of PCIe lanes, the same number of channels of memory, and the same maximum supported frequency of memory.

Questions still to be answered will be if the XCC/HCC/LCC silicon dies, from which the processor stack will come, will be the same. There is also no information about memory capacity limitations.
What Intel is saying on this slide however is in the second bullet point:
- Process tuning, frequency push, targeted performance improvements
We believe this is a tie-in to Intel improving its 14nm process further, tuning it for voltage and frequency, or a better binning. At this point Intel has not stated if Cascade Lake is using the ‘14++’ process node, to use Intel’s own naming scheme, although we expect it to be the case. We suspect that Intel might drop the +++ naming scheme altogether, if this isn’t disclosed closer to the time. However a drive to 10% better frequency at the same voltage would be warmly welcomed.
Where some of the performance will come from is in the new deep learning instructions, as well as the support for Optane DIMMs.
AVX-512 VNNI Instructions for Deep Learning
The world of AVX-512 instruction support is completely confusing. Different processors and different families support various sets of instructions, and it is hard to keep track of them all, let alone code for them. Luckily for Intel (and others), companies that invest into deep learning tend to focus on one particular set of microarchitectures for their work. As a result, Intel has been working with software developers to optimize code paths for Xeon Scalable systems. In fact, Intel is claiming to have already secured a 5.4x increase in inference throughput on Caffe / ResNet50 since the launch of Skylake – partially though code and parallelism optimizations, but partially though reduced precision and multiple concurrent instances also.
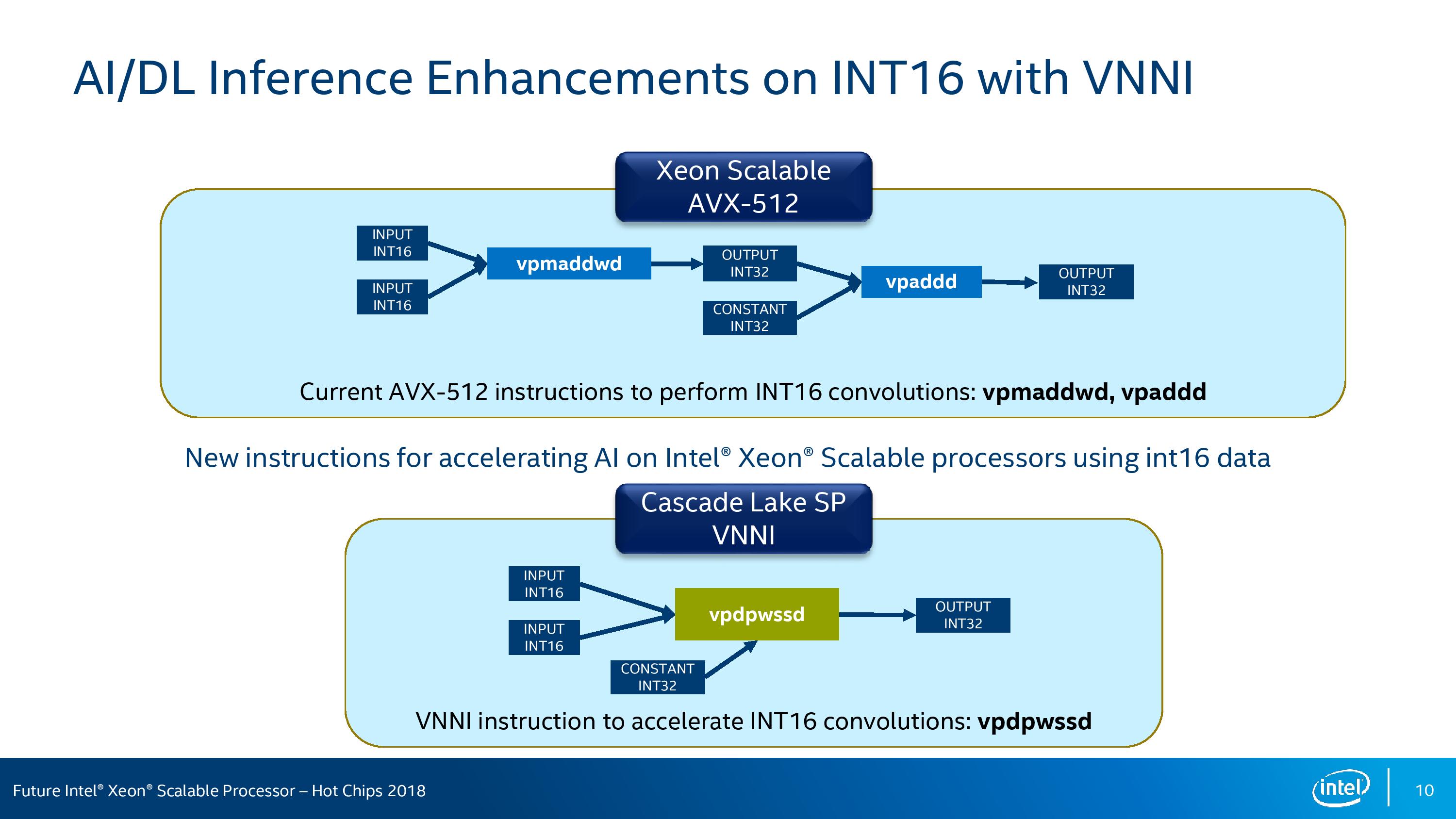
With VNNI, or Vector Neural Network Instructions, Intel expects to double its neural network performance with Cascade Lake. Behind VNNI are two key instructions that can optimized and decoded, reducing work:

Both instructions aim to reduce the number of required manipulations within inner convulsion loops for neural networks.
VPDPWSSD, the INT16 version of the two instructions, fuses two INT16 instructions and uses a third INT32 constant to replace PMADDWD and VPADD math that current AVX-512 would use:
VPDPBUSD does a similar thing, but takes it one stage back, using INT8 inputs to reduce a three-instruction path into a one-instruction implementation:
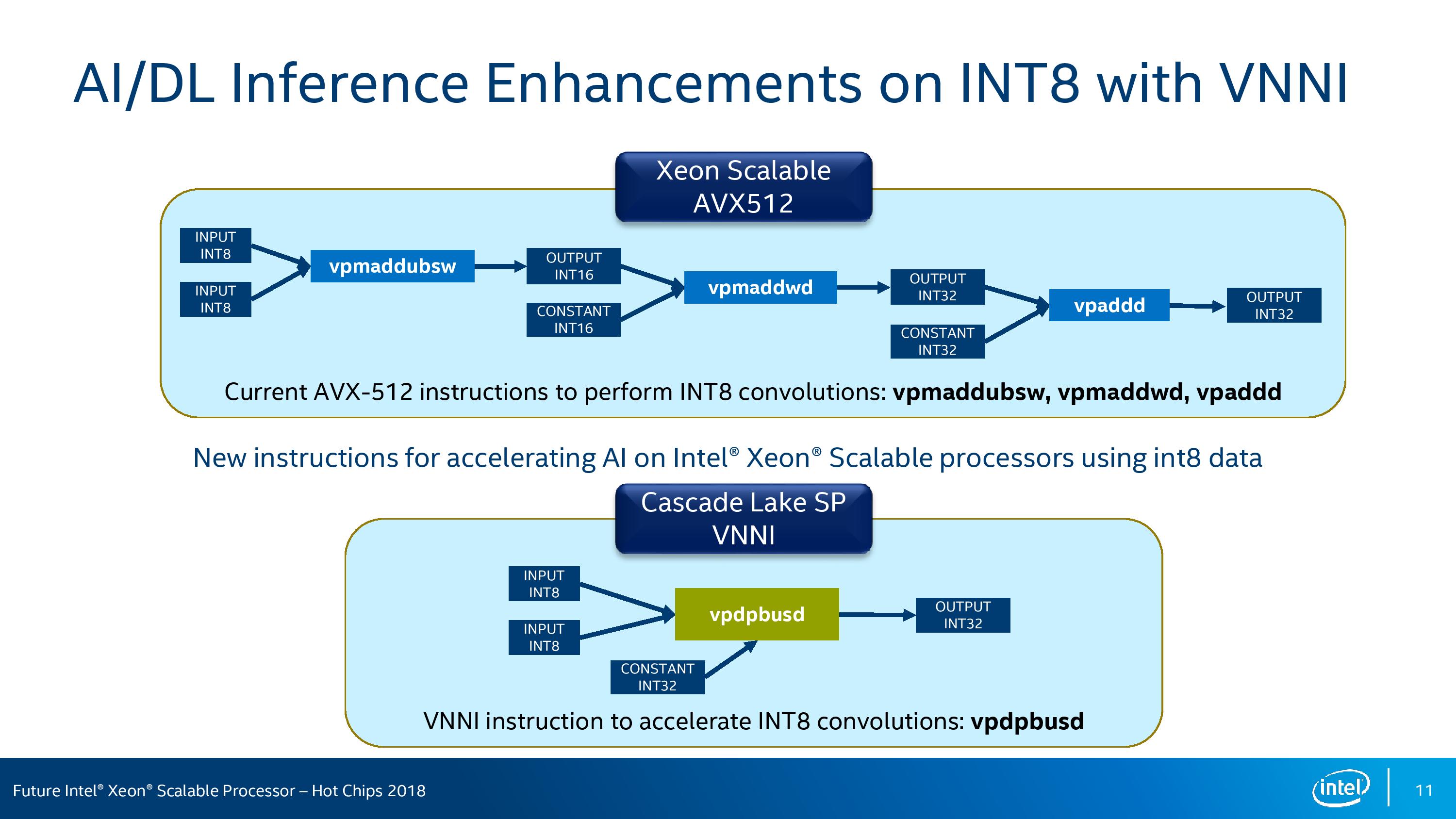
The key part from Intel here is that with the right data-set, these two instructions will improve the number of elements processed per cycle by 2x and 3x respectively.
Framework and Library for these new instructions will be part of Caffe, mxnet, TensorFlow, and Intel’s MKL-DNN.








31 Comments
View All Comments
SarahKerrigan - Sunday, August 19, 2018 - link
Thanks for posting this! Any chance we'll see uploads of the presentations for Tachyum, Xavier, Power9 SU, or SX-Aurora?Ian Cutress - Sunday, August 19, 2018 - link
Live Blogs for sure, more in depth analysis will depend on time. Hopefully write another one up tonight.Yojimbo - Sunday, August 19, 2018 - link
I'd like to hear about the SX-Aurora.HStewart - Monday, August 20, 2018 - link
What does these have to do with Intel presentation - or you just curious about presentations of event in generalSarahKerrigan - Tuesday, August 21, 2018 - link
This was the first Hot Chips presentation posted. I wished to ask about whether it would be joined by others. Calm down - not everything is about Intel...HStewart - Tuesday, August 21, 2018 - link
No that not what I mean, It just seems like when Intel is brought up - every one try to discuss other things like AMD and ARM.. people should say in focus."This was the first Hot Chips presentation posted."
That is incorrect - actually the one about Google Pixel was the first one.
https://www.anandtech.com/show/13241/hot-chips-201...
SarahKerrigan - Tuesday, August 21, 2018 - link
"Intel at Hot Chips 2018: Showing the Ankle of Cascade Lakeby Ian Cutress on August 19, 2018 7:30 PM EST"
"Hot Chips 2018: The Google Pixel Visual Core Live Blog (10am PT, 5pm UTC)
by Ian Cutress on August 20, 2018 12:45 PM EST"
So... yeah, no. This was posted Sunday night. The PVC presentation wasn't until Monday morning. Unless you think Ian has a time machine, you're demonstrably and provably wrong.
grahad - Saturday, August 25, 2018 - link
It's HStewart. If you're not praising Intel in Intel articles he'll go after your jugular (and miss).TetrisChili - Sunday, August 19, 2018 - link
Regarding the "money hand gesture" in the caption of the Intel tweet on the last page, do an image search for "Korean finger heart" to see what they're actually doing. :DAlistair - Sunday, August 19, 2018 - link
Yeah it's kind of crazy every Korean person I know doing that now. It's a thing. In TV shows also.