The ARM Diaries, Part 2: Understanding the Cortex A12
by Anand Lal Shimpi on July 17, 2013 12:30 PM EST- Posted in
- CPUs
- Arm
- SoCs
- Cortex A12
Back End Improvements
The front end of the Cortex A12 is a bit more efficient than the Cortex A9, but the bulk of the performance gains really come from improvements to the execution side of the core. Similar to the Cortex A15, ARM introduced multiple independent issue queues ahead of the functional units. It’s important to get nomenclature right here. Instructions are decoded into micro-ops, renamed instructions are dispatched into the issue queues and then micro-ops are issued from the issue queues when their operands are available. Everything up to the issue queue is handled in order, while issuing can be handled out of order in the Cortex A12 (in most cases, more on this later).
Whereas the Cortex A9 had a single issue queue ahead of all functional units, the Cortex A12 moves to three independent issue queues. The A9’s issue queue could hold 4 decoded instructions, while each issue queue in Cortex A12 is larger than that. The move to larger independent issue queues alone should help with increasing IPC.
The three issue queues are as follows: one for integer, one for FP/NEON and one for loads and stores. ARM provided bits and pieces of an architectural block diagram for the Cortex A12. I reconstructed one as best as I could below. The blue blocks indicate in-order components of the design, while the pink/salmon blocks are out-of-order. You can toggle between the A12 and A9 diagrams to see how things have changed.
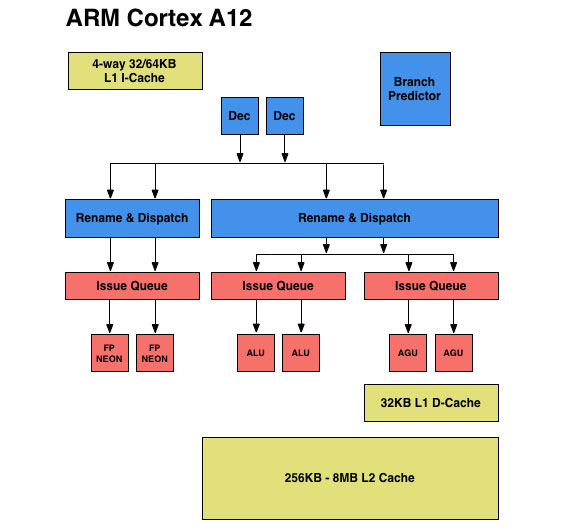
Cortex A12 retains the two integer pipelines of the Cortex A9, but adds support for integer divides (like the A7 and A15, other A-series architectures generally lacked support for hardware int divides). The rest of the integer execution capabilities are unchanged.
The FP/NEON units are vastly improved on the Cortex A12. When the Cortex A9 was first introduced, NEON code was rarely used which even lead NVIDIA to dropping NEON support altogether in Tegra 2. Times quickly changed as NEON code is widely used in Android and mobile applications.
The Cortex A12 design retains separate physical register files for integer and FP operations, but the RFs are larger than in Cortex A9.
Although Cortex A9 was considered an out-of-order microarchitecture, all FP and NEON instructions were executed in-order. With Cortex A12, ARM moves to a fully out-of-order architecture, at least as far as non-memory-ops are concerned. The FP/NEON issue queue now dual-issues into two FP/NEON pipes, both of which operate fully out-of-order. The FP/NEON pipes are also more tightly coupled, allowing for quicker data movement between FP and Integer units.
The improvements to the FP/NEON side are expected to show up quite nicely in benchmarks. ARM shared performance data using an FFMPEG workload on simulated Cortex A9 and Cortex A12 designs at the same frequency with the same number of cores (1):
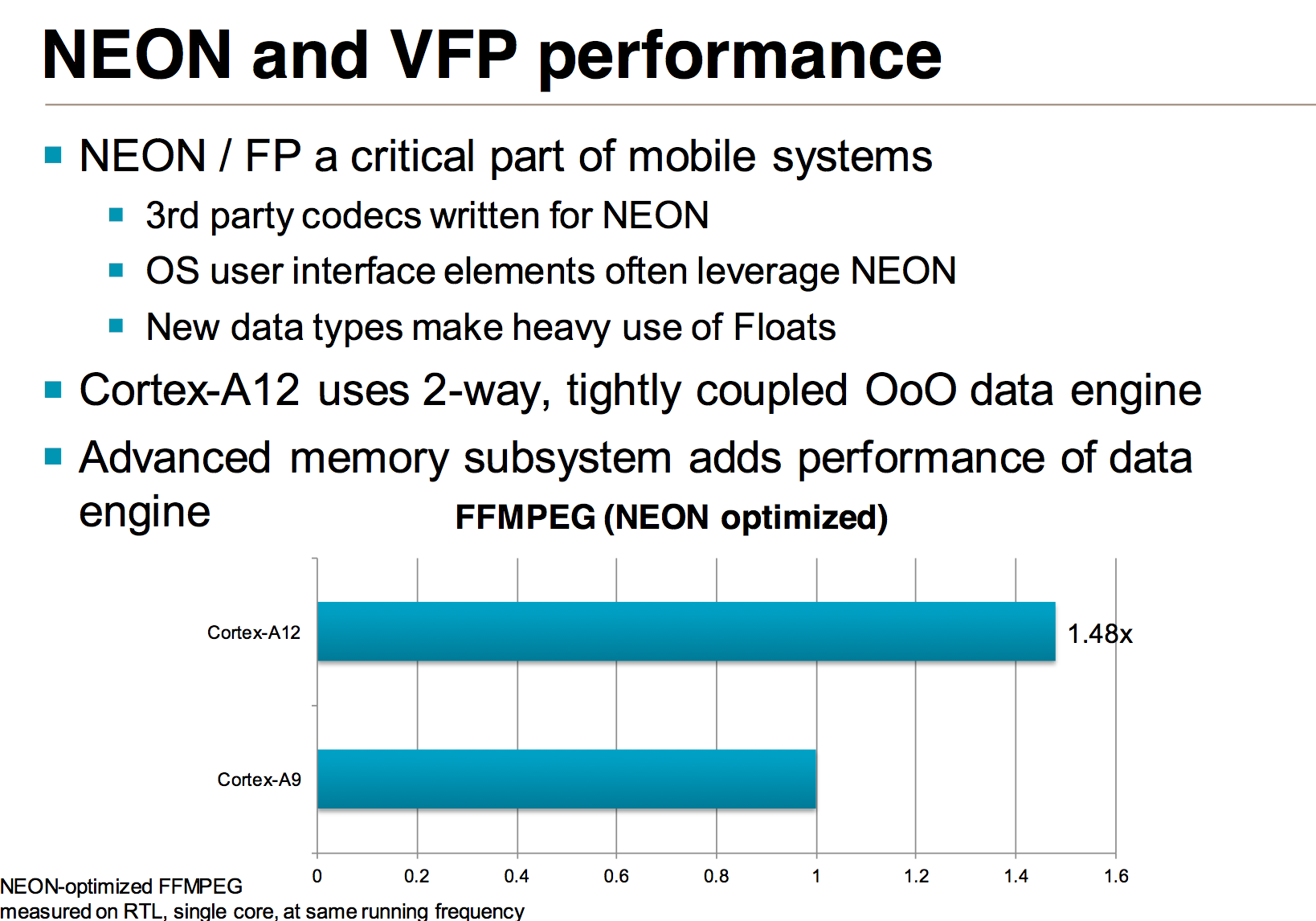
A 48% increase in NEON performance isn’t unexpected at all given the magnitude of improvements to this part of the execution engine.
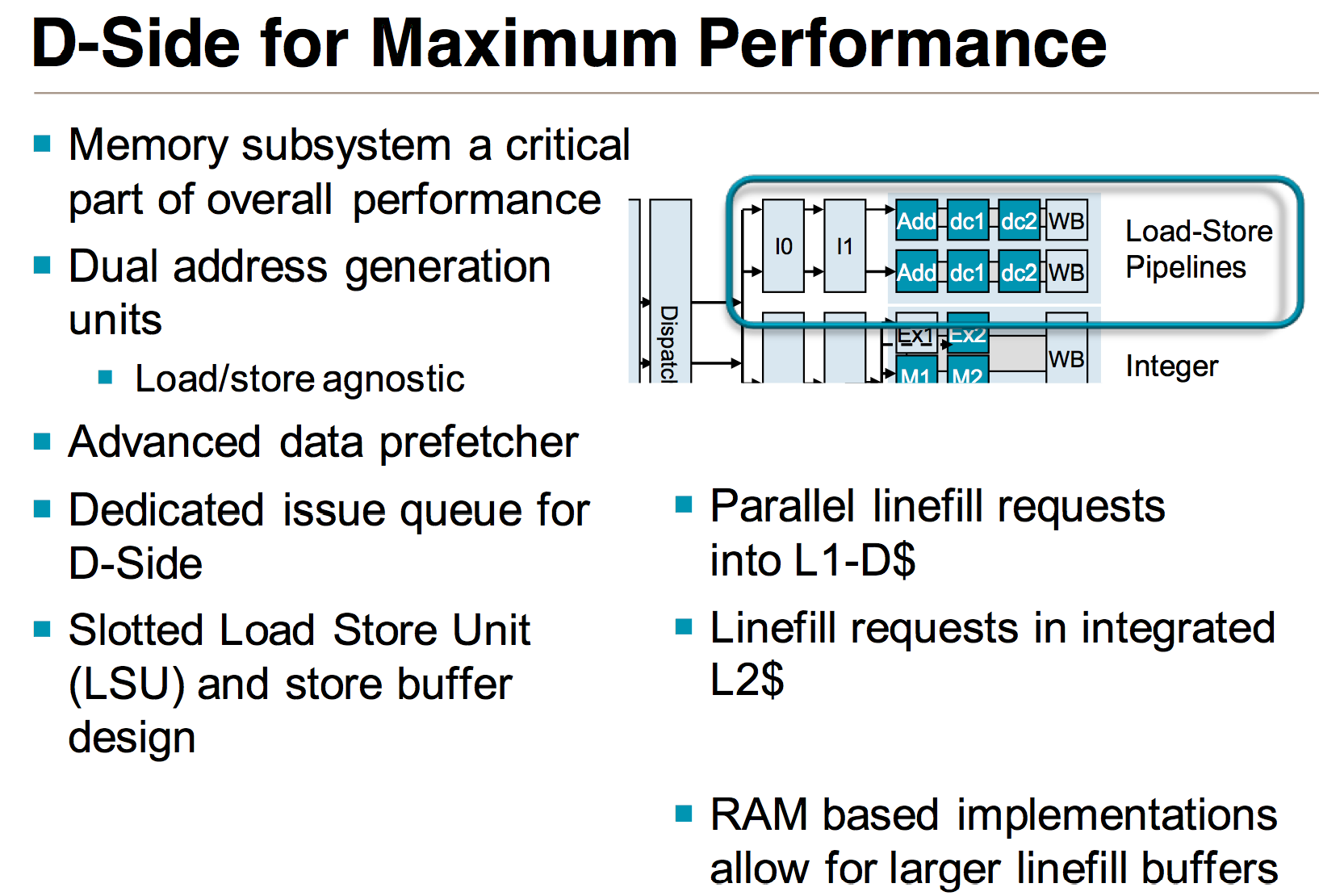
The final issue queue feeds the two load-store pipelines with two AGUs, once again a doubling from what was present in the Cortex A9 design. Each pipeline is equally capable (load/store agnostic) and mostly out-of-order (limits on what you can re-order if there are address dependencies between loads). By comparison, the load/store pipe in Cortex A9 was fully in-order.








65 Comments
View All Comments
JDG1980 - Wednesday, July 17, 2013 - link
So, roughly speaking, how does ARM IPC compare to x86? Obviously it's not going to be as high as on modern big-core desktop x86 parts like SB/IB/Haswell, but how does it compare to Atom (both the current generation and the new one in the pipeline) and Bobcat/Kabini?nathanddrews - Wednesday, July 17, 2013 - link
I think that was covered before:http://www.anandtech.com/show/6936/intels-silvermo...
coder543 - Wednesday, July 17, 2013 - link
The performance expectations (which relate to IPC) were misguided though. Intel's compiler was, essentially, cheating by skipping entire sections of the benchmark. http://www.androidauthority.com/analyst-says-intel...DanNeely - Wednesday, July 17, 2013 - link
If I'm interpreting the labels on that graph correctly ("K900 at 1.0"); they've under clocked the atom by 50% (from 2ghz to 1ghz) from what it normally operates at; which would flip the results back to Intel winning the majority of the tests.Krysto - Wednesday, July 17, 2013 - link
No, that's actually the *real* clock speed of Atom, which Intel misleadingly calls a "2 Ghz" core. The 2 Ghz speed is the turbo-boost speed, just like for laptops Haswell will really be clocked at 1.3 Ghz (same performance level as 1.5 Ghz IVB), and it goes up to 2.3 Ghz, or whatever, with Turbo-Boost.The problem is that I think benchmarks do use the Turbo-Boost speed fully, which means Atom will do very well in benchmarks, while that may not be the case in real day to day life, where the phone might never activate the Turbo-Boost speed, and just use the slower "real clock speed" all the time.
name99 - Wednesday, July 17, 2013 - link
The fact of Turbo-Boost is a problem for lazy benchmarking, it is NOT a problem for Intel.Why do you want a high speed core in your phone? There is a population that wants to run aggressive games, or transcode video or whatever, and these people care about sustained performance. But they're in the dramatic minority. For most users, the value of a high speed core is that it makes the phone more zippy, meaning that operations are fast when they need to be fast, after which the phone can go back to sleeping. The user-level "speed" of a phone is measured by how fast it draws a (single) PDF page, or renders a (single) complex web page, or launches an app, not by how it performs over any task that takes longer than a second. In such a world, if Turbo-Boost allows the app to sprint for a second, then go back to low-power mode, the user is very happy with that behavior.
The only "problem" with this strategy, for Intel, is that it is obvious and will be copied by everyone. Intel is there first and most aggressively for historical and process reasons, but there's no reason they will remain the only player.
(It's also quite likely that competitors will adopt the ideas of Turbo-Boost, just never call it that. After all the problem to be solved for phones is different from the REAL Turbo-Boost problem. Turbo-Boost comes from a world where you run the chip as hot as it can go --- till it just about to overheat. If an ARM core has no danger of actually overheating, then the design space is different. Now it's simply "we'll rate the core for 2GHz, but at that speed it uses up 10 nJ/op, so as far as possible we'll try to run it a 1GHz (using up 2 nJ/op) or better yet 100MHz (using up 10 pJ/op) [all numbers made up, but you get the point].)
Wilco1 - Wednesday, July 17, 2013 - link
All CPUs typically run at a far lower frequency than the maximum - I'm sure nobody believes eg. Krait 800 runs all 4 cores at 2.3GHz all the time. So if you call a specific frequency the "base" then anything faster than that is automatically a turbo boost. In that sense Intel's turbo boost is largely marketing, a way to claim a low TDP by setting the base frequency arbitrarily low, and allowing to go well over that TDP for a certain amount of time at a much higher boost frequency.inighthawki - Wednesday, July 17, 2013 - link
My 3.5/3.9GHz advertised i7 4770K runs at 800Mhz at idle :)TomWomack - Thursday, July 18, 2013 - link
My desktop Haswell with Intel's retail cooler runs all four cores 24/7 turbo-boosted - I'm not quite sure what to, it reports 3401MHz in Linux but that's because /proc/cpuinfo asks ACPI which isn't fully compatible with turbo-boost. The machine draws 100W from the mains while doing so, which (given that it idles at 28W) is entirely consistent with the 84W TDP.And, indeed, it runs at 800MHz at idle; and I suspect often slower than that, but /proc/cpuinfo doesn't report C-states
RicDavis - Friday, July 19, 2013 - link
Intel's turbostat has proven very useful for getting good reporting of CPU clock speeds under Linux. with the -v option it also displays the maximum speeds that CPU will run at as the no of active cores varies. Recommended. i7z is another option, but I've seen it do a bad job of showing which cores are active when hyperthreading is enabled.