Western Digital Reveals SweRV RISC-V Core, Cache Coherency over Ethernet Initiative
by Anton Shilov on December 5, 2018 12:00 PM EST- Posted in
- Storage
- CPUs
- SSDs
- Western Digital
- RISC-V

Western Digital this week made three important announcements concerning its RISC-V-based processor initiative launched last year. The company introduced its own SweRV general-purpose core, its OmniXtend cache coherency over Ethernet technology, and the open-sourced SweRV Instruction Set Simulator (ISS). Western Digital expects that the hardware and software will be used for various solutions aimed at Big Data and Fast Data applications, including flash controllers and SSDs.
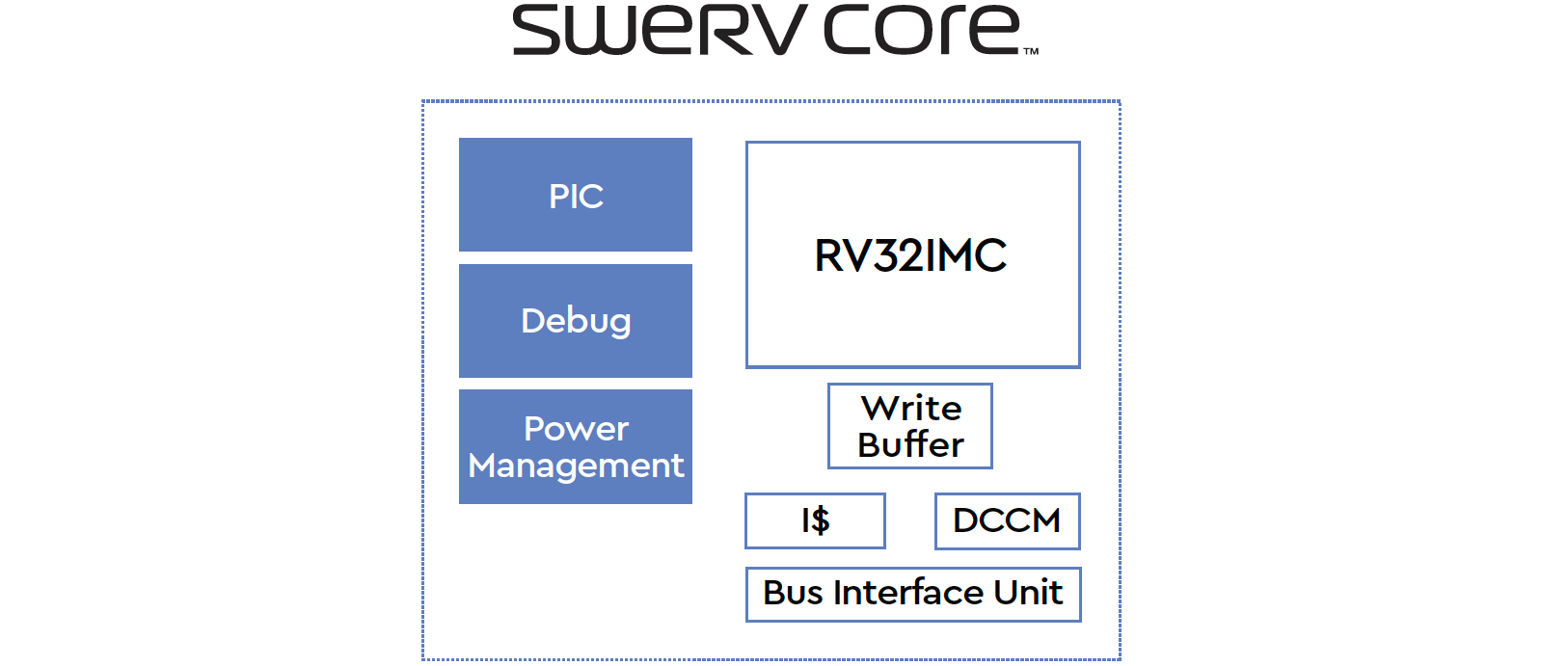
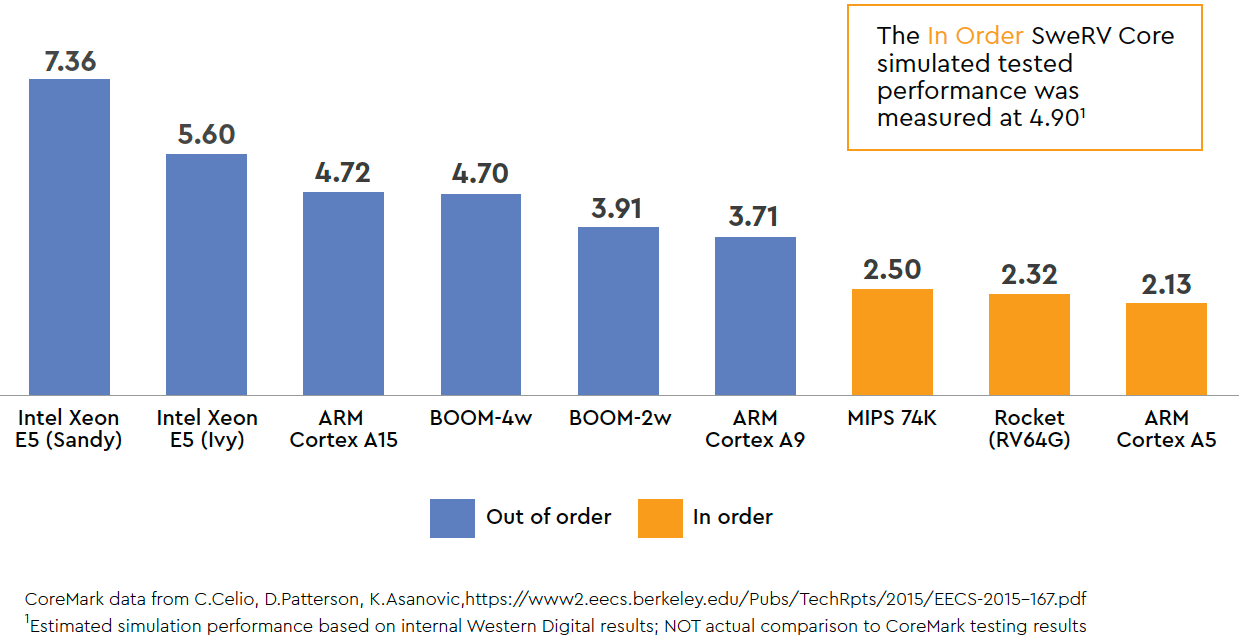
Western Digital’s RISC-V SweRV core is a 32-bit in-order core featuring a 2-way superscalar design and a nine-stage pipeline. When implemented using a 28 nm process technology, the core runs at up to 1.8 GHz. As for simulated performance, the SweRV core delivers 4.9 CoreMark/MHz, which is a bit higher when compared to ARM’s Cortex-A15. Western Digital will use its RISC-V cores for its own embedded designs, such as flash controllers and SSDs. The company will also make it available as an open-source product to third parties starting from Q1 2019. The company hopes that by enabling third-parties to use the core it will help to drive adoption of the RISC-V architecture by harware and software developers eventually.
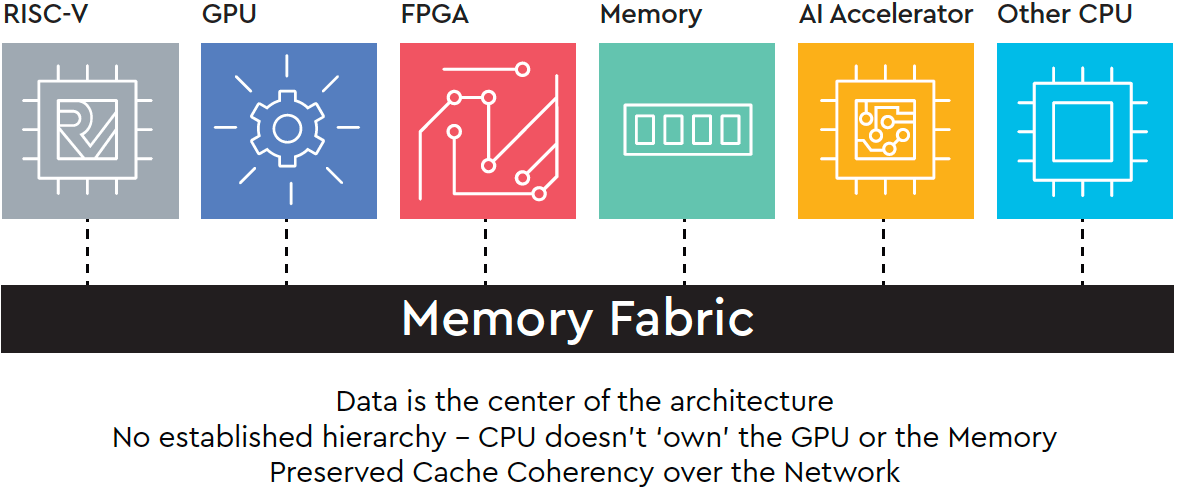
Along with its own CPU core, Western Digital is also rolling out its OmniXtend cache coherent memory technology, which enables cache coherence over Ethernet .Co-developed with SiFive, the company expects its OmniXtend tech to be used for attaching persistent memory to processors, but it says that this memory-centric architecture could be used for other components, including CPUs, GPUs, FPGAs, and machine learning accelerators.
Western Digital does not disclose maximum bandwidth its OmniXtend can provide but since we are dealing with Ethernet fabrics, it should not be slower than various versions of Ethernet in general. While the OmniXtend is open and available to various parties, it of course remains to be seen whether developers of the aforementioned components (accelerators, processors, etc.) actually decide to use the OmniXtend.
Finally, Western Digital also rolled outs its open-sourced SweRV Instruction Set Simulator (ISS). The program enables software designers to simulate execution of their code on the SweRV cores, simplifying development of programs, which is greatly important to drive adoption of RISC-V.
Related Reading:
- Western Digital to Use RISC-V for Controllers, Processors, Purpose-Built Platforms
- SiFive Unveils Freedom Platforms for RISC-V-Based Semi-Custom Chips
Source: Western Digital








11 Comments
View All Comments
Dolda2000 - Wednesday, December 5, 2018 - link
Great to see RISC-V getting some practical adoption. It's a surprising configuration, though; with cache-coherent interconnects, it's surprising they haven't included the A extension for atomic operations, and since it appears to be aimed at large systems handling a lot of data, one would have thought a 64-bit implementation would be more suitable.Any word on how they can achieve such apparently outstanding performance with an in-order design?
Wilco1 - Wednesday, December 5, 2018 - link
Apparently is the right word. Cortex-M7 (2-way in-order) does 5.05 Coremark/MHz, and Cortex-A15 achieves 5.6 using an old compiler. It's easy to win if you handicap your competition in your comparisons!peevee - Wednesday, December 5, 2018 - link
"simulated".Now, speculative OoO is not such a big deal over 2-way superscalar if you keep your pipeline short and memory latencies low. If your internal loop is not too tight, speculative OoO is almost useless, even worse than useless in power-limited applications. And a small core can have L1 and L2 caches physically closer to register file, having lower latencies.
name99 - Wednesday, December 5, 2018 - link
More precisely the primary value of OoO is dealing with unpredictable memory latency. Instruction latency can be handled via compiler scheduling. Predictable memory latency can be handled via prefetching (SW or automatic).Which means that if your benchmark is not memory intensive (runs out of L1 cache) it won't demonstrate much of the value of OoO.
Now, is this benchmark an accurate reflection of the work WD needs this controller to perform? ie, is the business of controlling a storage device a task that runs primarily out of L1 cache?
Well, who knows? Seems unlikely, but then, why does WD even feel the need to boast about the speed of their controller? I mean, who cares --- people are going to benchmark the disk, not pondering how they can measure the speed of the controller.
kfishy - Wednesday, December 5, 2018 - link
I think WD is trying to position itself for in-memory processing/computing as new memory technologies and topologies start to emerge from the pipelines, eg 3D Xpoint for which its biggest problem is that its strengths are ill suited for current computer architectures.prisonerX - Wednesday, December 5, 2018 - link
The architecture has a clean design which likely lends itself to a clean and efficient implementation. It's had the benefit of a thorough analysis of preceding architectures and their mistakes. They may also have benefitted from existing research and designs around this architecture.If this is the case then it bodes well for open architectures.
linuxgeex - Thursday, December 6, 2018 - link
I believe this is the case, but then why haven't OpenRISC, or even ARM, slaughtered Intel yet?Oh yeah... Intel can afford to hire the best design talent away from just about every other core development project.
Unfortunately an open architecture doesn't get billions of design dollars because nobody with the money to pay the designers for all that hard work can guarantee that they will be able to capitalise on the results of that work.
Yet.
The same was true of the Linux Kernel. Now there are at least tens of millions annually going into Linux. It's only taken near 30 years to get there.
prisonerX - Thursday, December 6, 2018 - link
Could be that Krste Asanovic and his team are just smarter. Certainly seems that way. Throwing money at something, even over time, doesn't always produce optimum results.Wilco1 - Thursday, December 6, 2018 - link
Or it could be mostly marketing hype. It's just another variant of the 33 year old MIPS architecture. And reducing branch and load/store immediate ranges compared with MIPS doesn't seem like a smart move given applications are a lot larger and more complex than 3 decades ago...blu42 - Friday, December 7, 2018 - link
That's a good point, actually. Arm spent quite an effort with immediates in armv8, and from my limited observations, it's paying off.