Hot Chips 31 Live Blogs: Habana's Approach to AI Scaling
by Dr. Ian Cutress on August 19, 2019 9:15 PM EST- Posted in
- Artificial Intelligence
- Hot Chips
- Live Blog
- Habana


09:21PM EDT - The final talk today at Hot Chips is from Habana, who is discussing its approach to how to scale AI compute.
09:21PM EDT - Goya and Gaudi
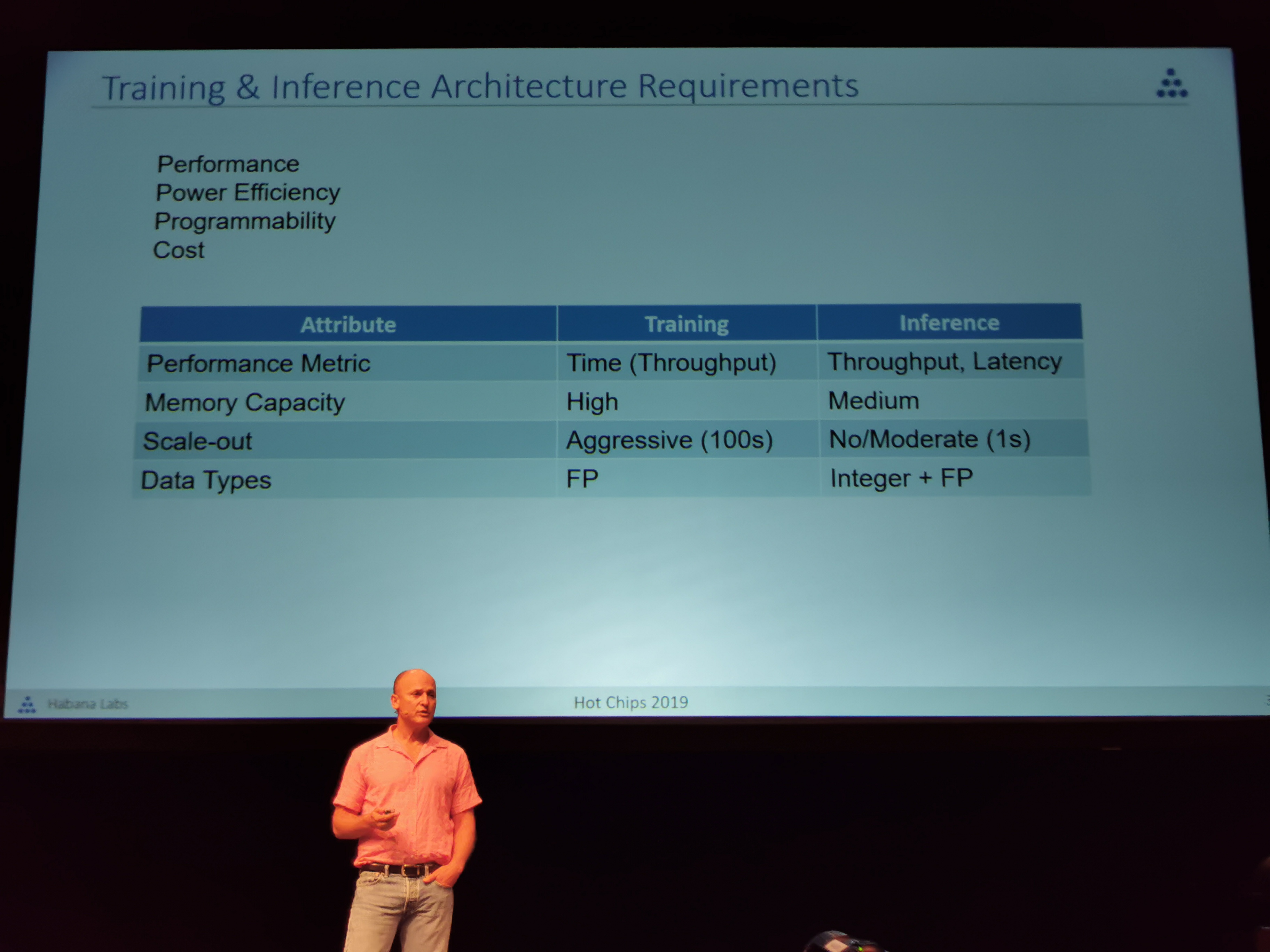
09:22PM EDT - Recapping Training vs Inference requirements
09:24PM EDT - Goya processor architecure

09:24PM EDT - 3 engines, RPC, GEMM, and DMA. Work Concurrently with shared SRAM
09:24PM EDT - TPC is VLIW SIMD core, C-programmable
09:24PM EDT - PCIe Gen 4.0 x16
09:24PM EDT - Two DDR4-2666 channels, built on TSMC 16
09:25PM EDT - Supports UINT8 to FP32
09:25PM EDT - Dedicated HW and TPC ISA for special function acceneration
09:25PM EDT - Have to adjust quantization to mix accuracy vs power

09:26PM EDT - PCIe card - Software stack is more important.
09:26PM EDT - Habana is a software company that just happens to do hardware
09:27PM EDT - Graph compiler with built-in quantization engine
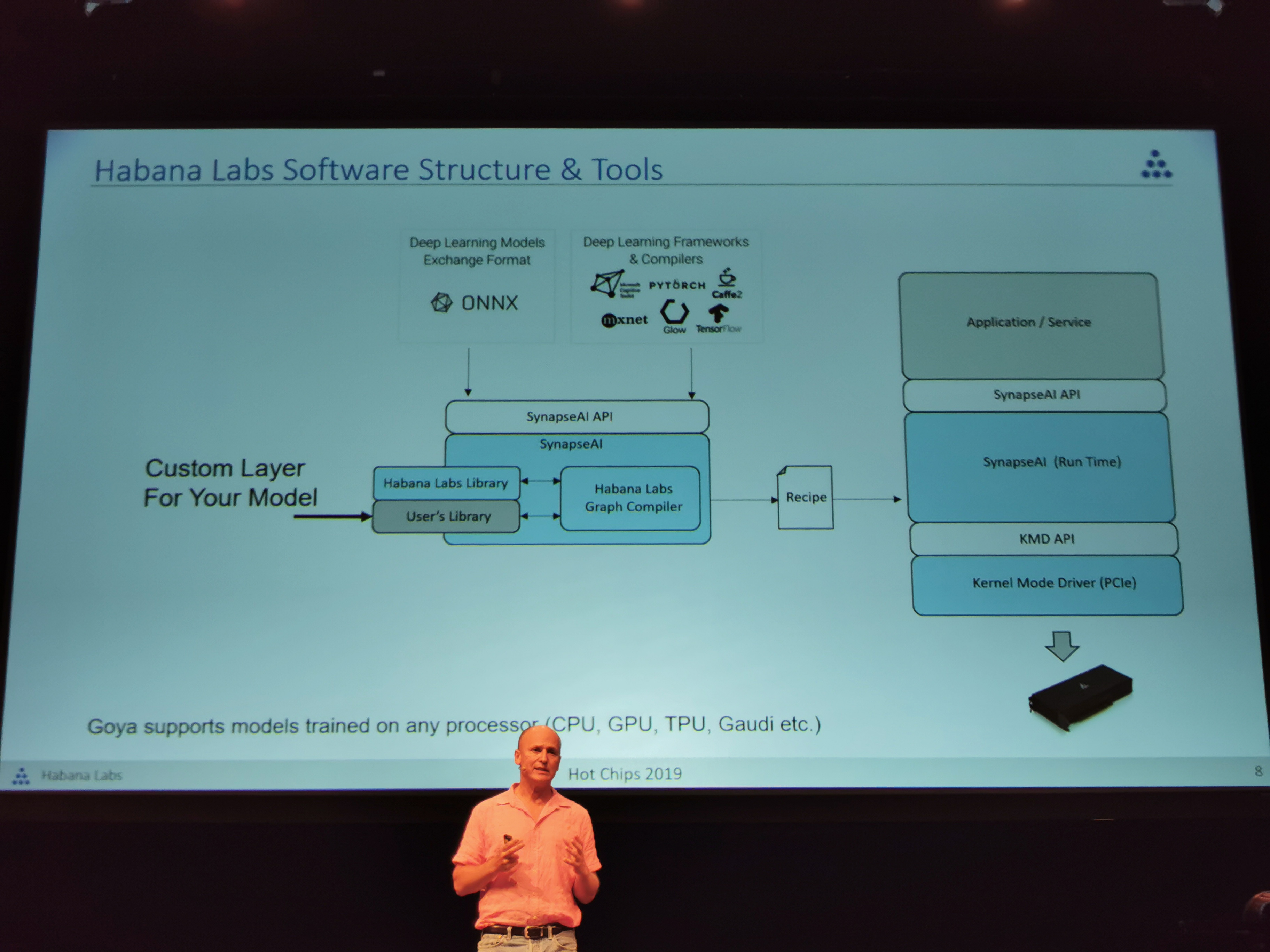
09:27PM EDT - Multiple recipes can be loaded for the hardware
09:28PM EDT - Goya supports models trained on any processor: CPU, GPU, TPU, Gaudi etc
09:28PM EDT - Users can create custom layers and kernels
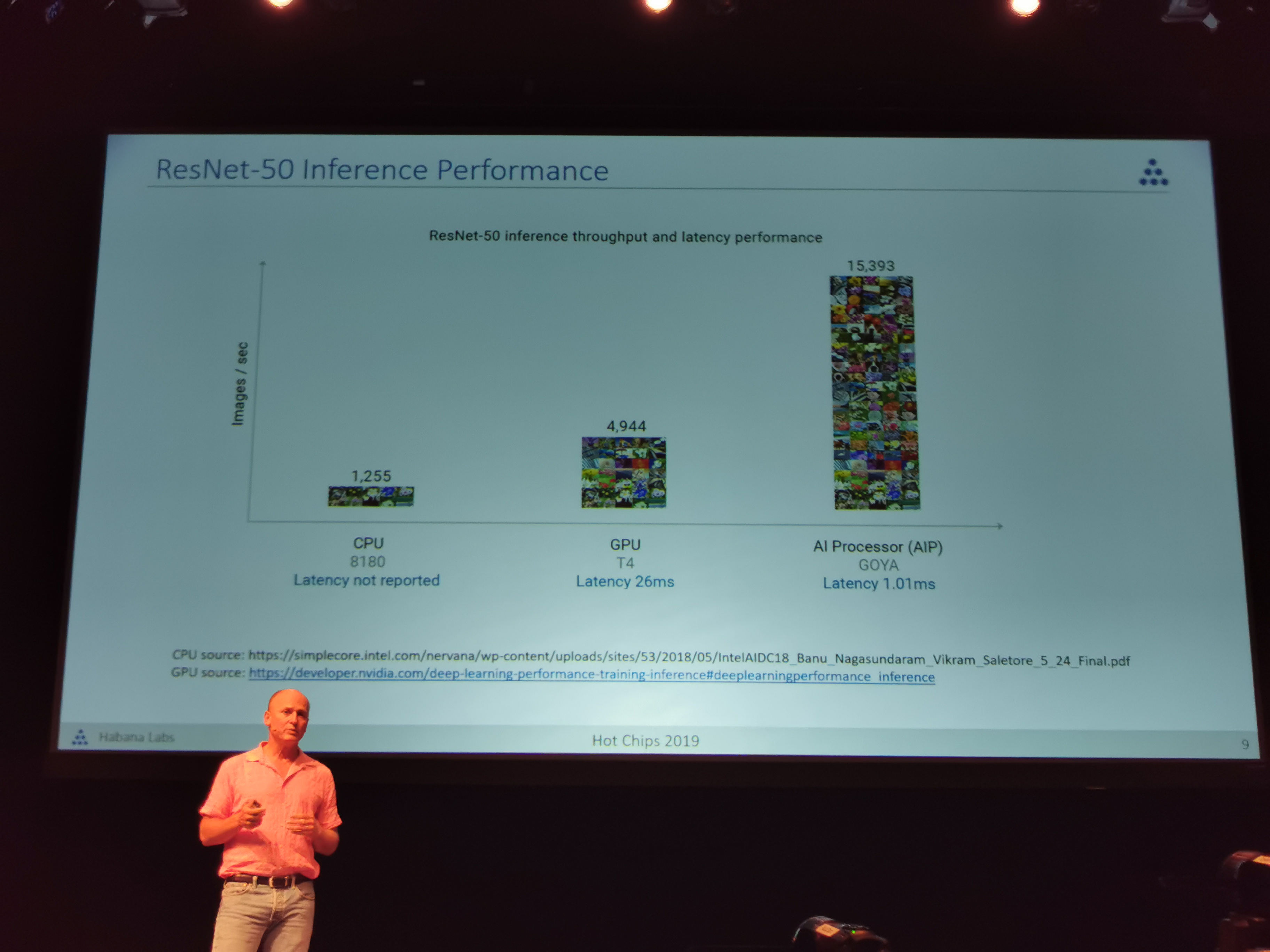
09:29PM EDT - Still market leader since benchmarks made 11 months ago vs common CPU/GPU

09:29PM EDT - New for today, natural language benchmark results
09:30PM EDT - Support BERT architecture on Goya
09:30PM EDT - GEMMs and TPCs are fully utilized
09:30PM EDT - Chip was designed long before BERT was invested
09:30PM EDT - invented
09:30PM EDT - High degree of accuracy when quantized
09:30PM EDT - Software managed SRAM

09:31PM EDT - Now Gaudi, the training processor

09:31PM EDT - Performance at Scale, high throughput at low batch size, high power efficiency
09:32PM EDT - Enable native ethernet scale out - on chip RDMA over Converged Ethernet
09:32PM EDT - Open Compute Project Accelerator Module: OAM = (OCP)AM
09:32PM EDT - Framework and ML compiler support, rich TPC Kernet Library
09:32PM EDT - Architecture looks similar to Goya

09:33PM EDT - Networking has changed, memory has changed
09:33PM EDT - PCIe 4.0 x16, 4x8GB HBM
09:33PM EDT - 10x 100 GbE, or 20x50 GbE
09:33PM EDT - Supports UINT8 to FP32 and BF16
09:34PM EDT - SW supports profiling tools
09:34PM EDT - Only AI Training chip with RoCE v2
09:35PM EDT - NVIDIA was first to showcase RoCE v2 for AI, but they haven't implemented it yet
09:36PM EDT - NVIDIA GPU is much more complex with RoCE v2 support via Mellanox
09:36PM EDT - Gaudi integrates both
09:36PM EDT - Supports Lossless and Lossy fabrics
09:36PM EDT - Advanced congestion controls




09:37PM EDT - Customers can buy OAM cards or an 8 card Server
09:38PM EDT - Server box has no CPU, up to customer to config to needed. Uses mini-SAS HD
09:38PM EDT - Ethernet connectivity for point-to-point links with non-blocking full mesh
09:38PM EDT - 3 ports per card for scale up

09:39PM EDT - Can choose ratio of CPUs to Gaudi cards

09:39PM EDT - Gaudi vs DGX
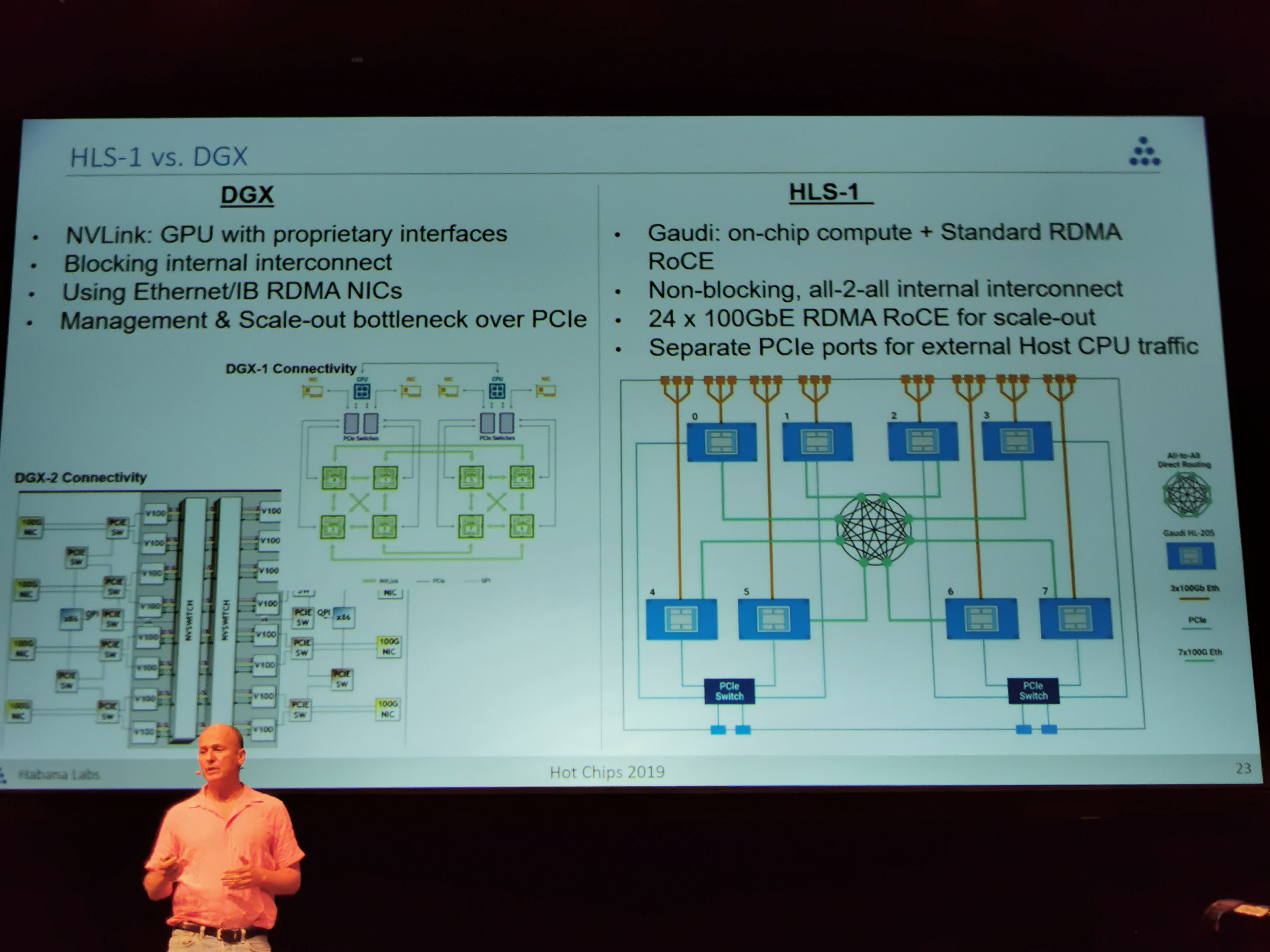
09:40PM EDT - Unlike DGX, do not force user to separate PCIe between management and scaleout. Gaudi offers separate PCIe ports
09:41PM EDT - PCIe card dual slot also available

09:41PM EDT - HL-200
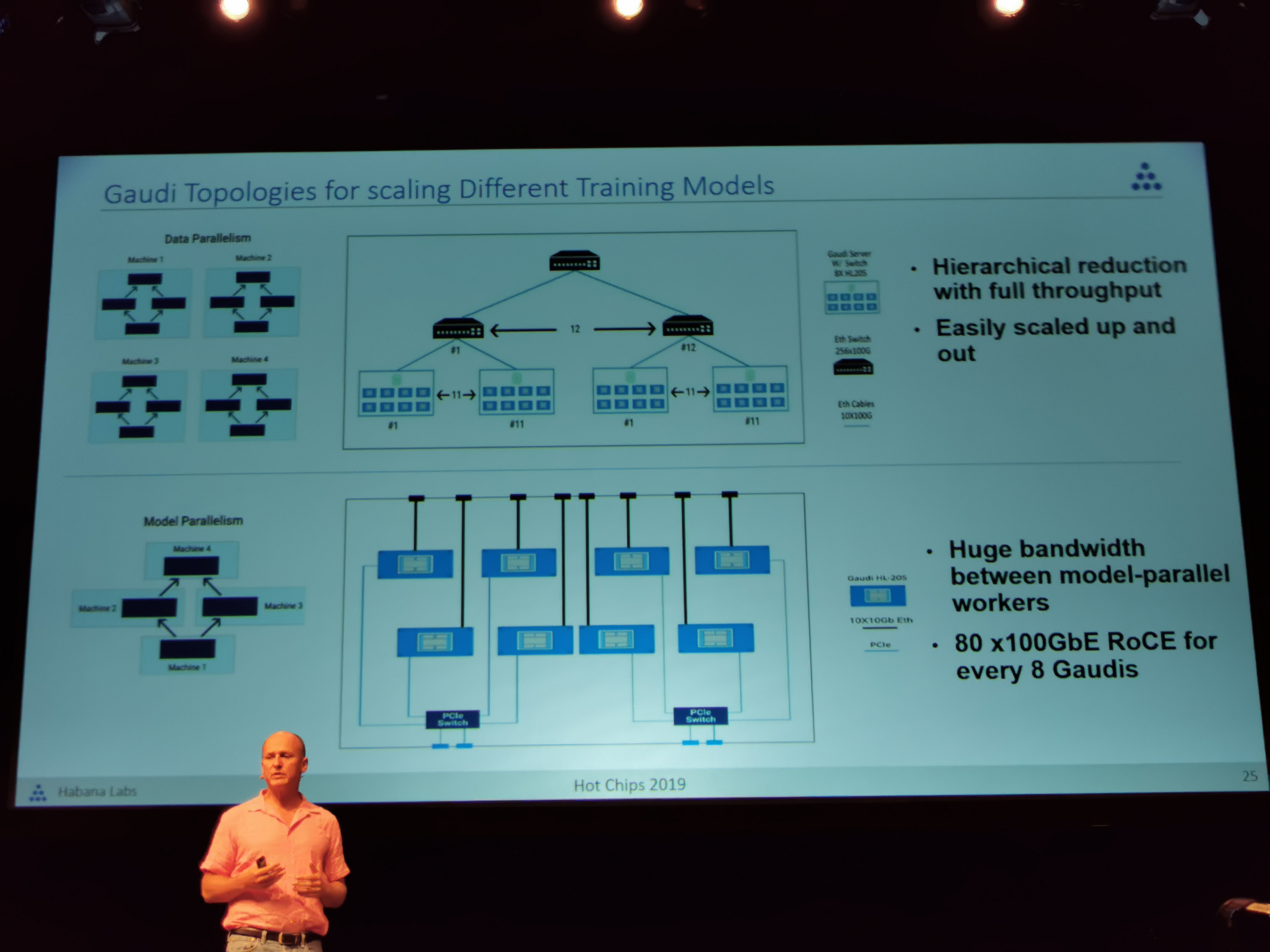
09:41PM EDT - Data parallel possible, model parallel possible
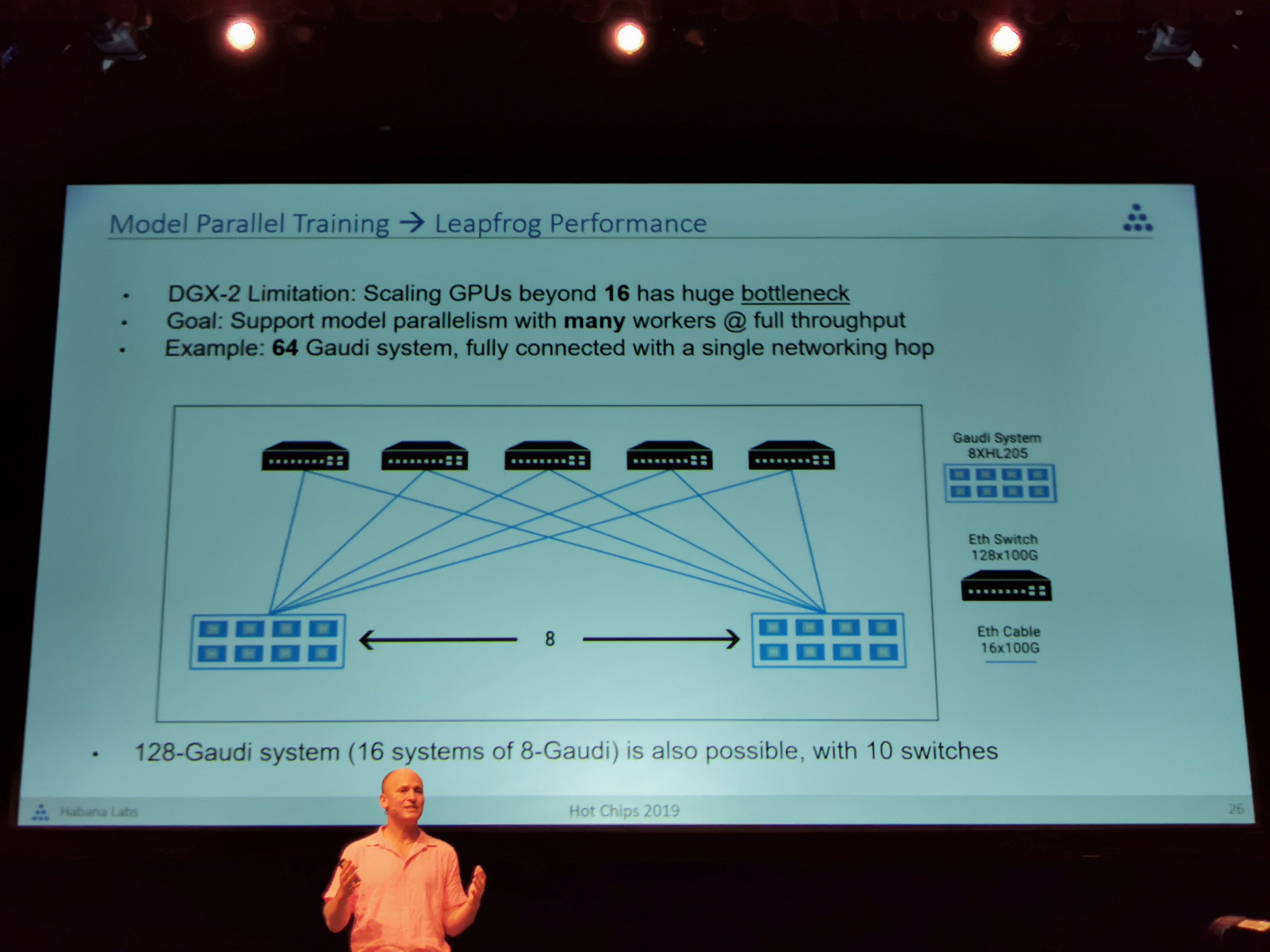
09:44PM EDT - Can leapfrog performance over DGX-2 due to better connectivity. Can connect 64 gaudi chips with non-blocking throughput
09:45PM EDT - Q&A time
09:46PM EDT - Q: What type of quantization requires a processor? There is no quantization processor. There's a software engine that takes an FP32 model and can quantize to data types that are more efficient and gives the feedback on the accuracy
09:47PM EDT - Q: Can you comment on interconnectivity of GEMM? A: It's one functional unit.
09:48PM EDT - Q: What is the minimum viable for an IoT gateway? A: You can use a single card. You can put a gaudi in a single PCIe slot.
09:48PM EDT - That's a wrap for today. More talks tomorrow!








17 Comments
View All Comments
Billy T. Casey - Tuesday, August 20, 2019 - link
This article was written by a real https://www.proessaywriting.com/buy-custom-essay-o...thinking writer. I agree many of the with the solid points made by the writer. I’ll be back.
ParsonJ - Wednesday, June 10, 2020 - link
Thanks Ian! I appreciate for this post. By the way, this writing service https://www.do-my-assignment.com/essay-help-austra... is a great place for essay help. So u can use it if u want.GraceJordan - Friday, August 14, 2020 - link
My friends told me about the website https://qweetly.com. I’ve found there a lot of samples of various academic papers. It helped me to write my own assignments.ethancarter - Thursday, September 10, 2020 - link
It is misleadingly simple to assemble a proof of idea for AI and show all its astonishing accomplishments at https://www.ukessaywriters.co.uk. In any case, executing and scaling AI in operational cycles all through an undertaking is an entire diverse ball game. We should see what scaling AI implies precisely.AmandaBrooks - Sunday, September 20, 2020 - link
Wanna chill out instead of writing papers? Visit https://writepaperfor.me/ and ask for their professional assistance.MonicaSavage - Thursday, September 24, 2020 - link
Searching for https://topessayservices.com/essayup-review/? Follow the link to know what students say about this writing service on Reddit and what papers expect from its writers.Allan Conley - Wednesday, October 14, 2020 - link
I am very happy to read this post...Information sharing with excellent points.. thanks for giving us go through details.Fantastic perfect. I appreciate this post. https://thebuyly.com/led-torchiere-floor-lamp/Oliver6 - Friday, October 23, 2020 - link
I felt very happy while reading this site. This was a really very informative site for me. I really liked it. https://getcheeply.com/ashley-jade-stern-net-worth... This was really a informative post. Thanks a lot!Eva975 - Thursday, December 31, 2020 - link
This must be a very informative meeting. I'm sure I would learn lots of new things there. It's a shame I couldn't visit. I hope I will be able to make it next year. Until that time I need to get and be sure of reliable support on https://specialessays.com/buy-a-response-reaction-...Sylvia99 - Friday, January 15, 2021 - link
There is nothing more exciting and embarrassing for a student than college freshmen traditions. Check out some of the most common ones to be ready for everything. https://collegehomeworktips.com/college-freshmen-t...