Hot Chips 2020 Live Blog: Alibaba's Hanguang 800 NPU (5:00pm PT)
by Dr. Ian Cutress on August 18, 2020 7:55 PM EST- Posted in
- AI
- Live Blog
- NPU
- Alibaba
- Hot Chips 32
- Hanguang 800


07:58PM EDT - Former Huawei GPU architect

07:59PM EDT - Development in early 2018
08:00PM EDT - Lots of business on inferencing
08:00PM EDT - achieve high-throughput, low latency, high power efficiency design
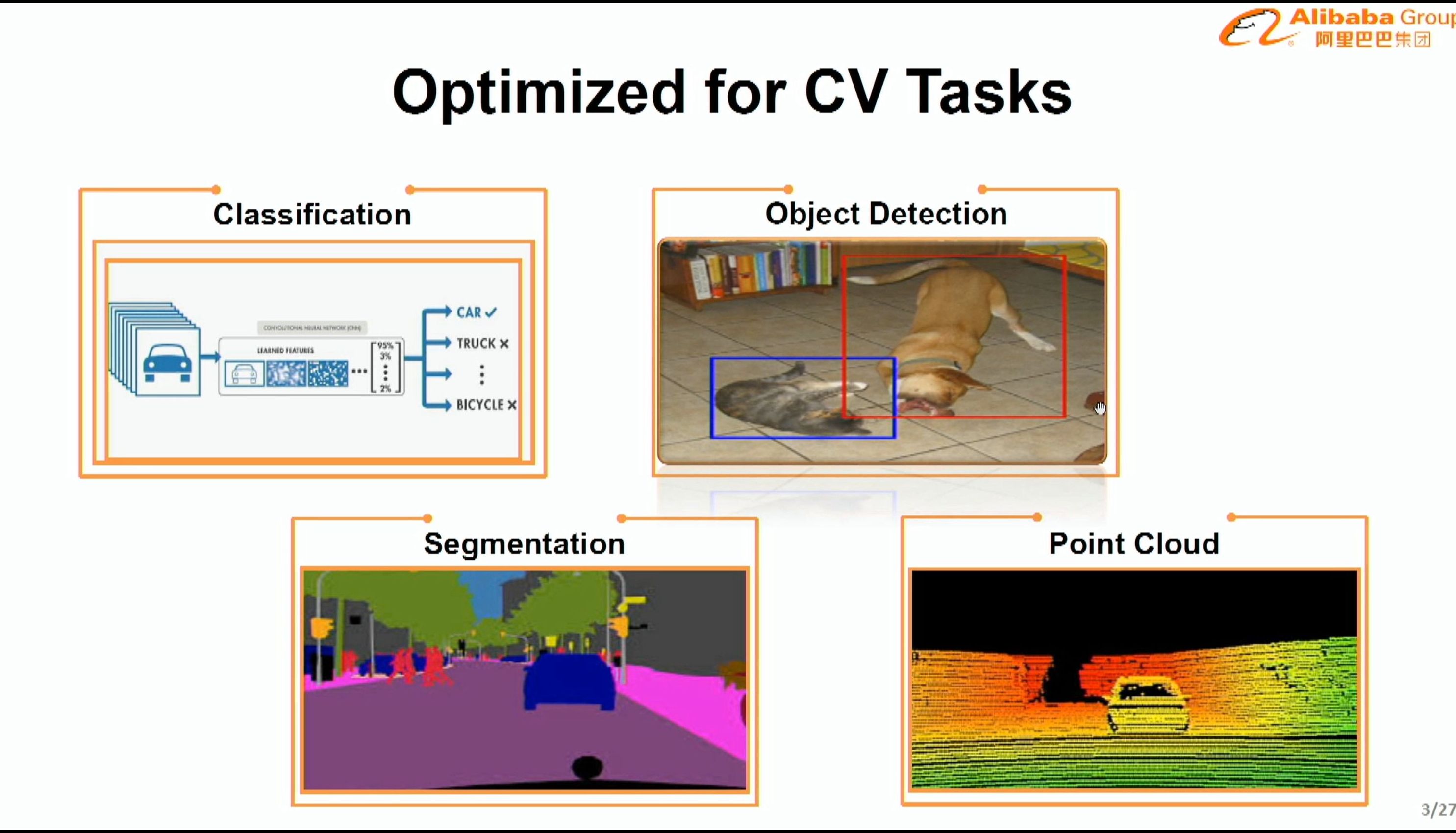
08:00PM EDT - Lots of Alibaba workloads are convolution-related
08:00PM EDT - Optimization for GEMM as well
08:00PM EDT - Flexible to support future activation functions
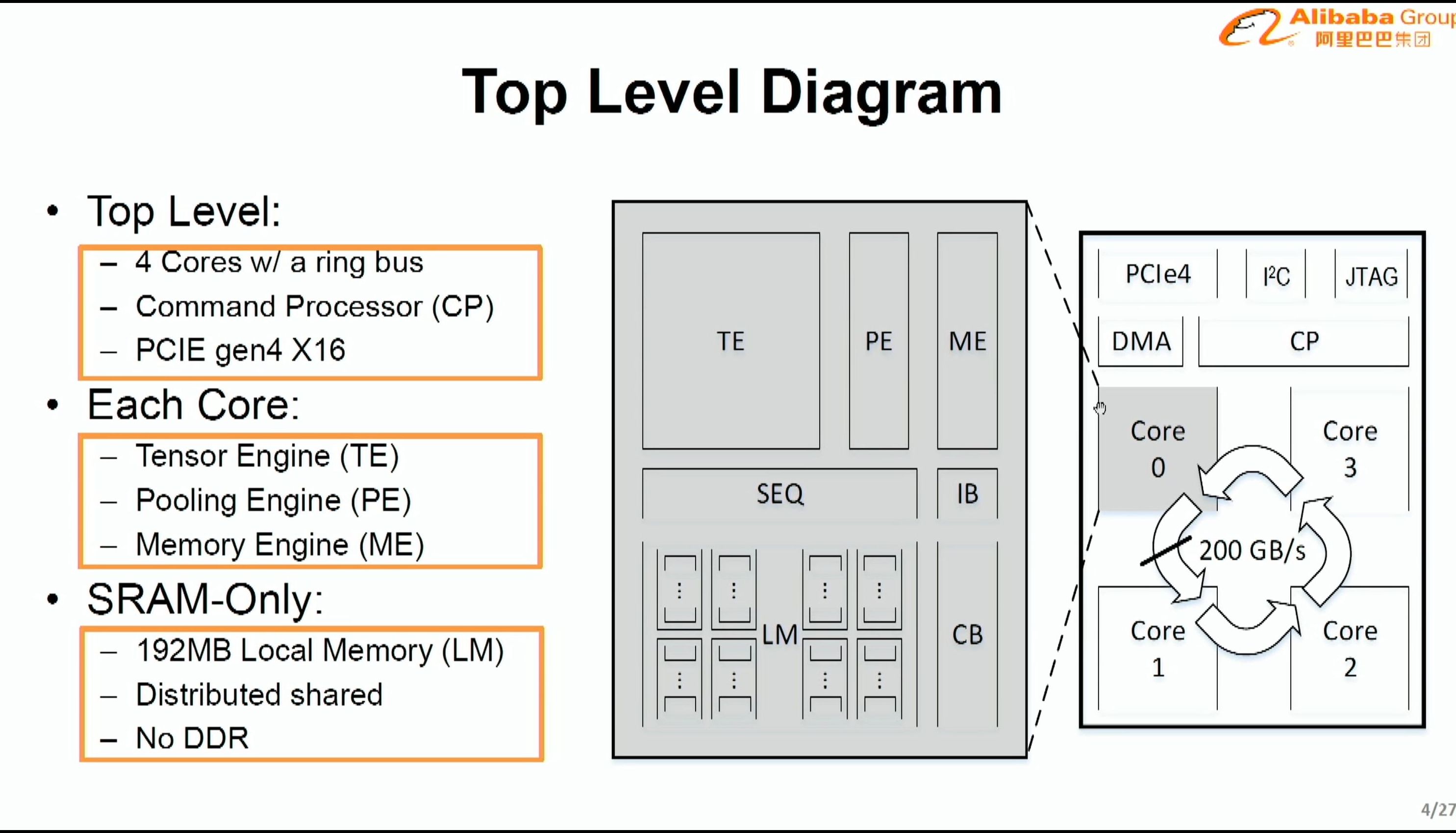
08:01PM EDT - 4 cores with ring bus
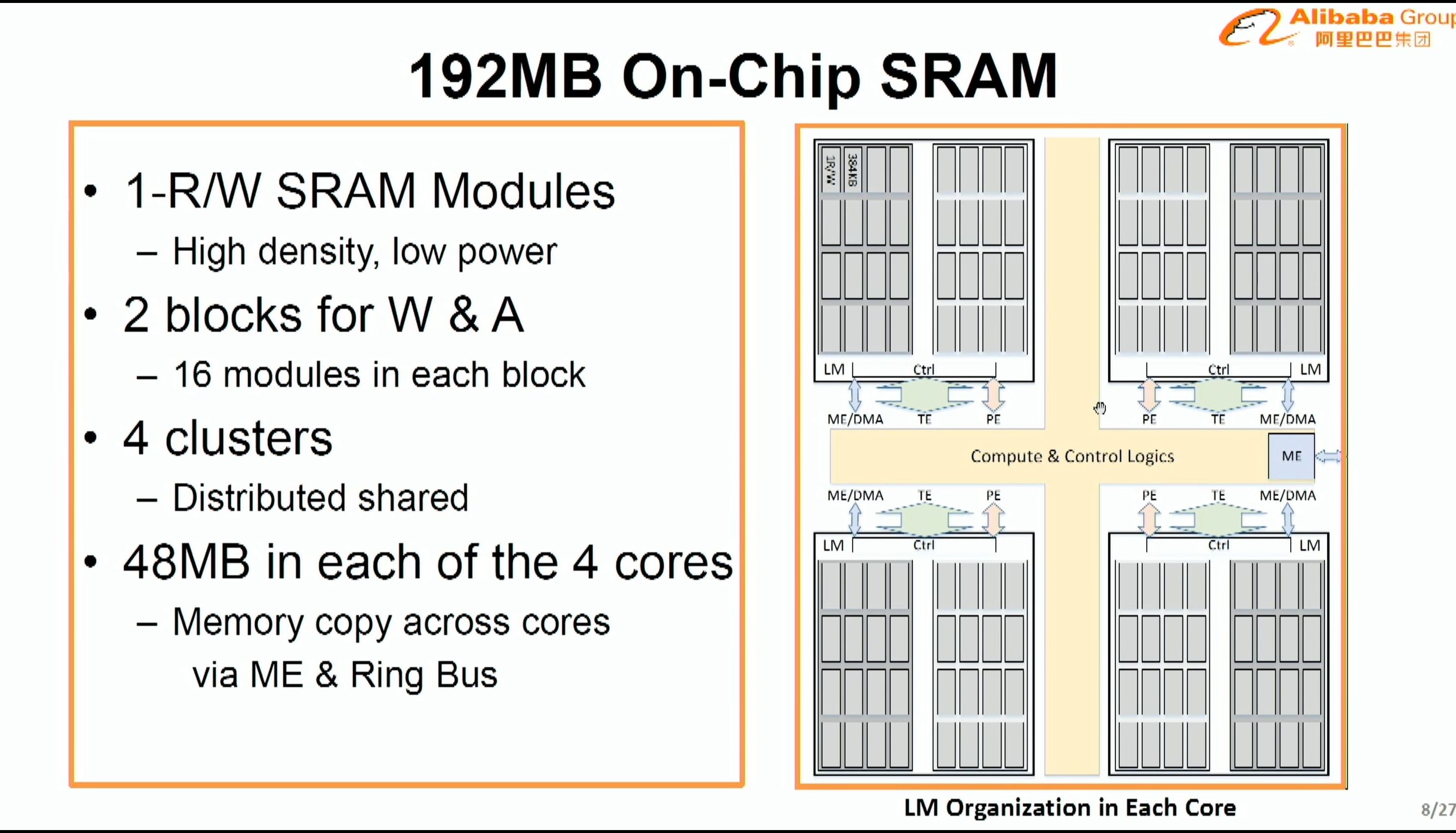
08:01PM EDT - 192 MB local memory, distributed shared, no DDR
08:01PM EDT - Command processor above all four cores
08:01PM EDT - PCIe 4.0 x16
08:02PM EDT - Each core has three engines: Tensor, Pooling, Memory
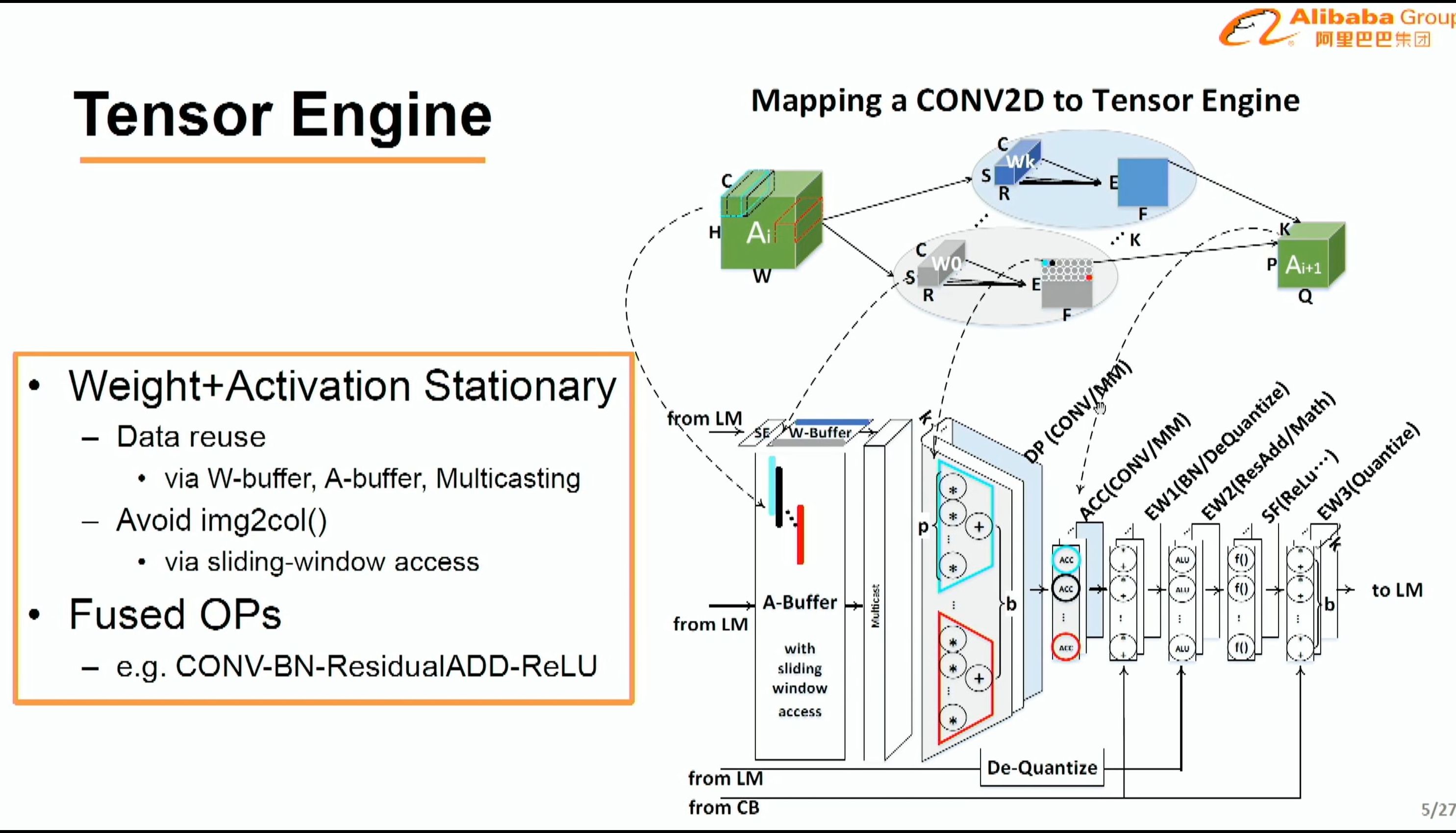
08:02PM EDT - This is the tensor engine throughput
08:02PM EDT - data reuse and fused ops
08:02PM EDT - minimize data movement
08:03PM EDT - Use sliding window to minimize access
08:04PM EDT - Convert data to FP and push down the pipe
08:04PM EDT - on EW2 stage
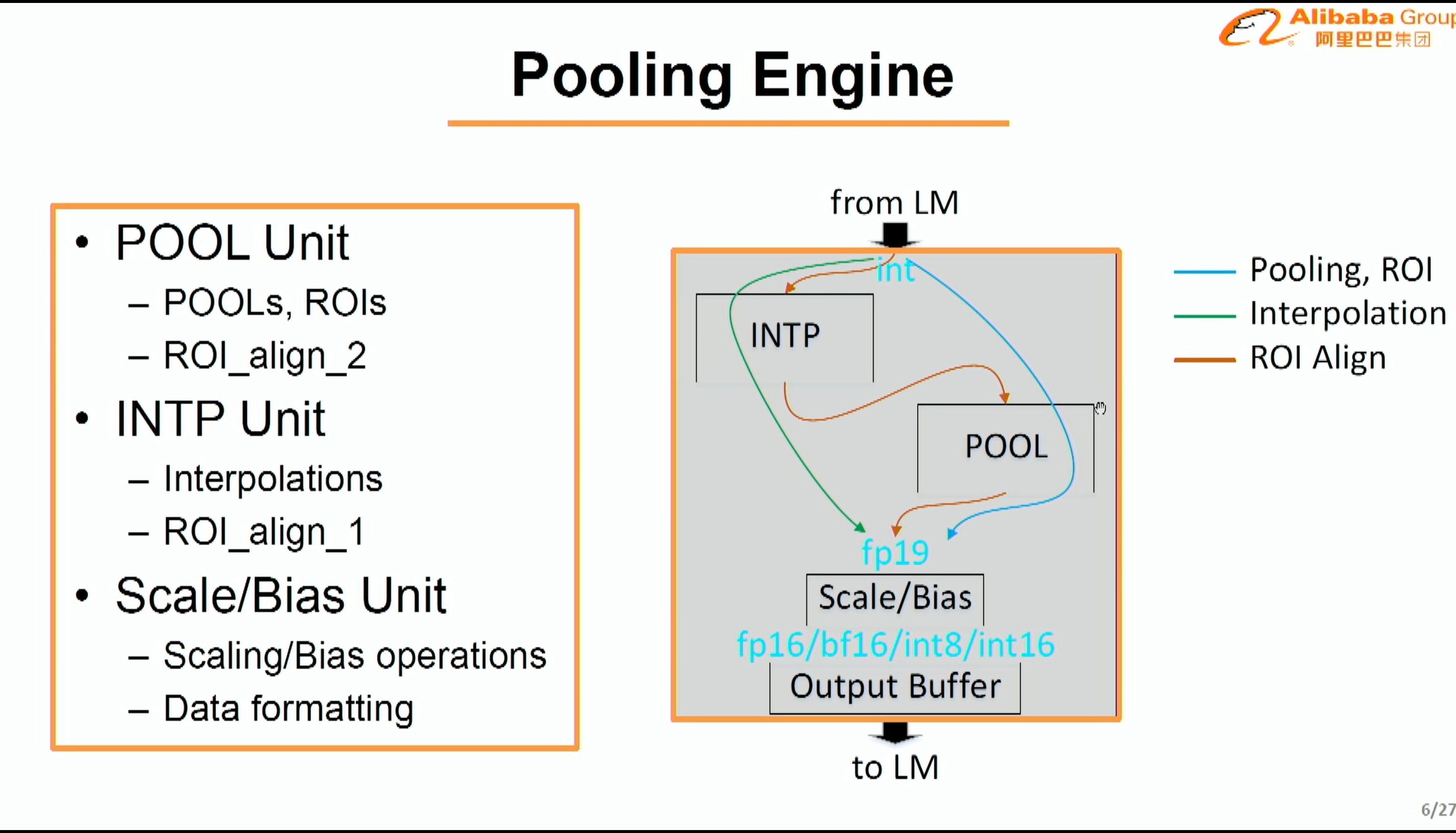
08:05PM EDT - fp19 support
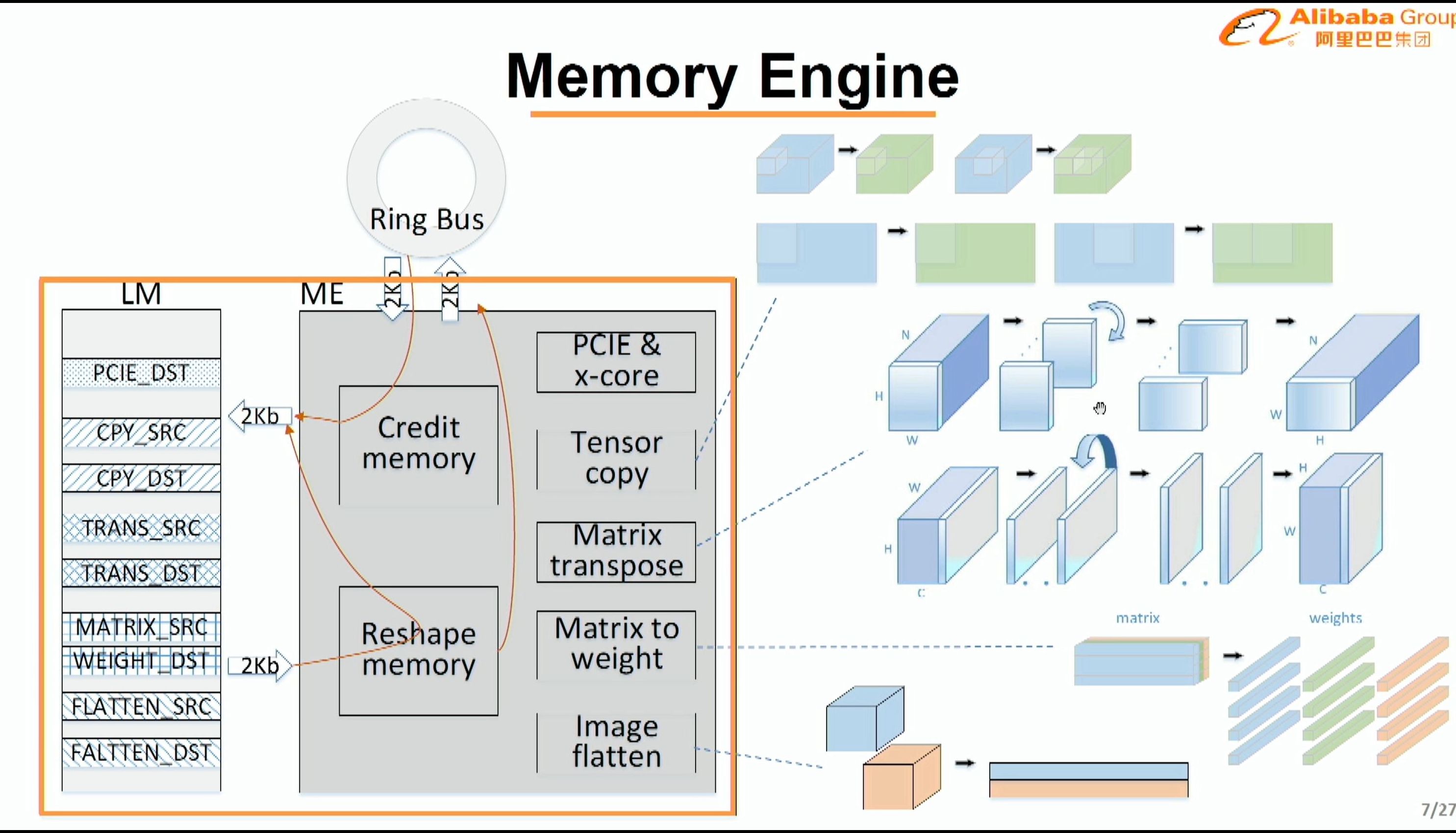
08:05PM EDT - memory engine can adjust arrangement of data
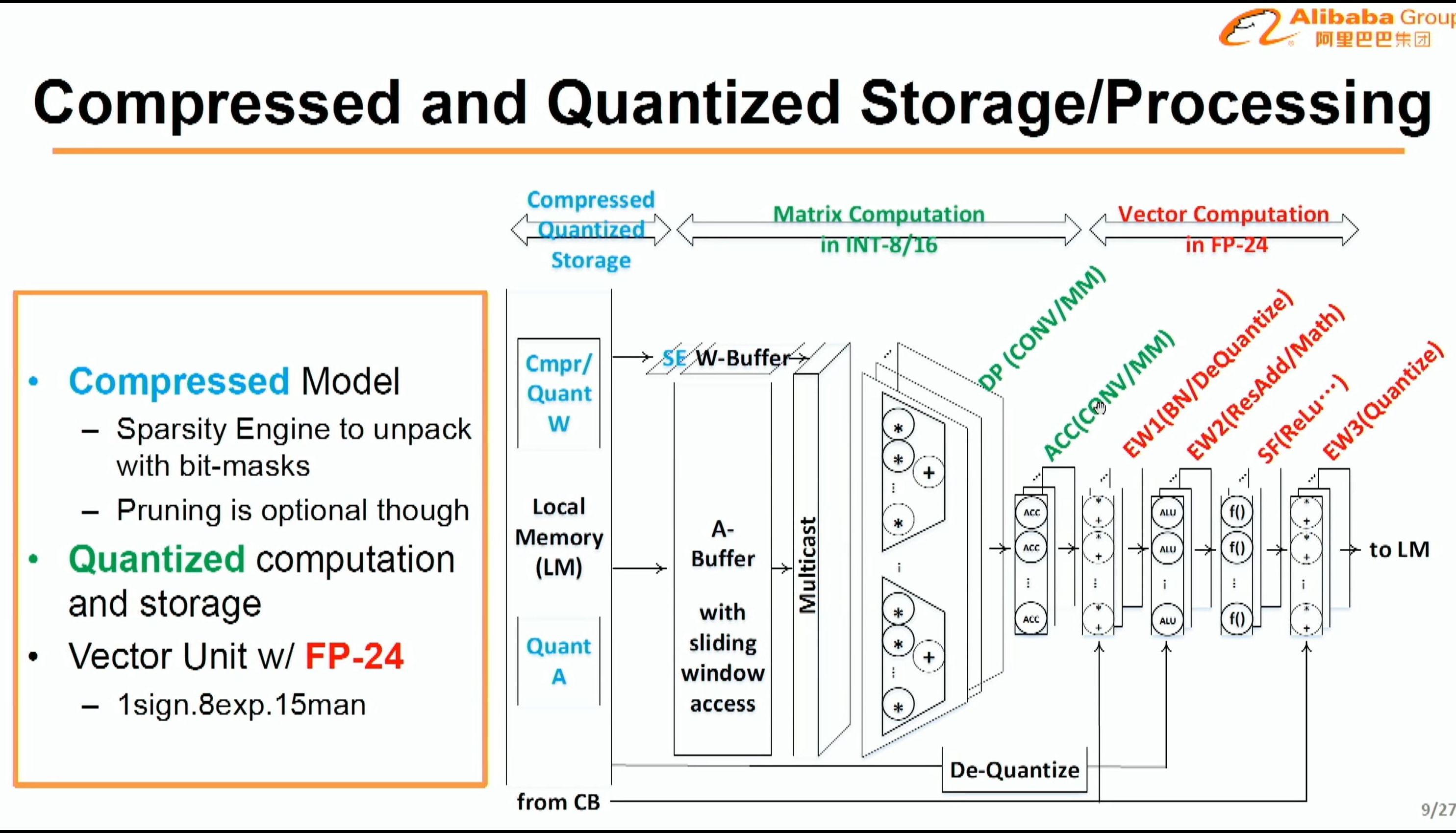
08:06PM EDT - Support for compressed models for sparse data
08:06PM EDT - Pruning is optional
08:06PM EDT - Quantized to INT16/INT8
08:06PM EDT - FP24 vector unit
08:07PM EDT - Way buffer
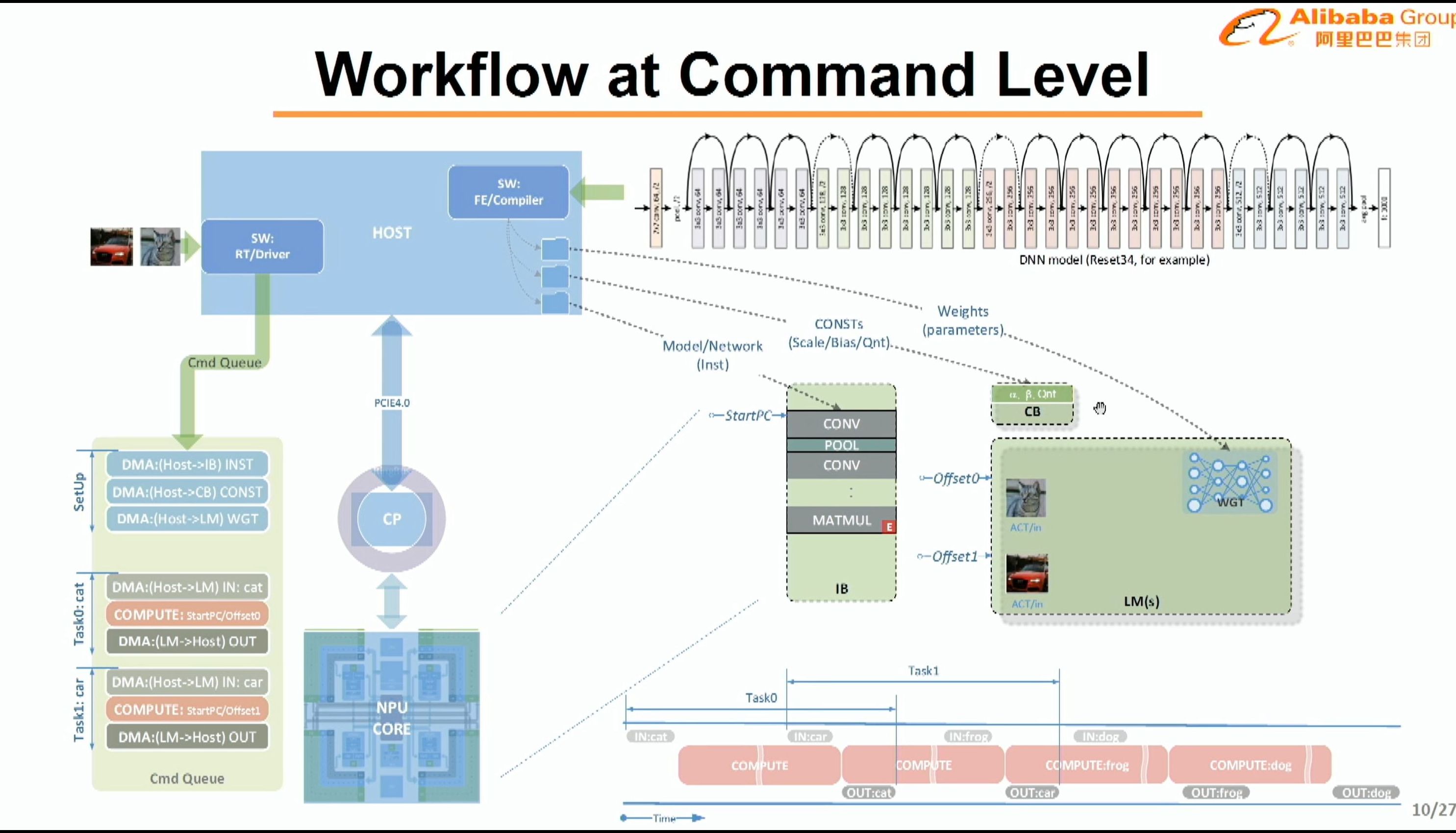
08:08PM EDT - This is a typical workflow
08:09PM EDT - Host CPU communicates to CP
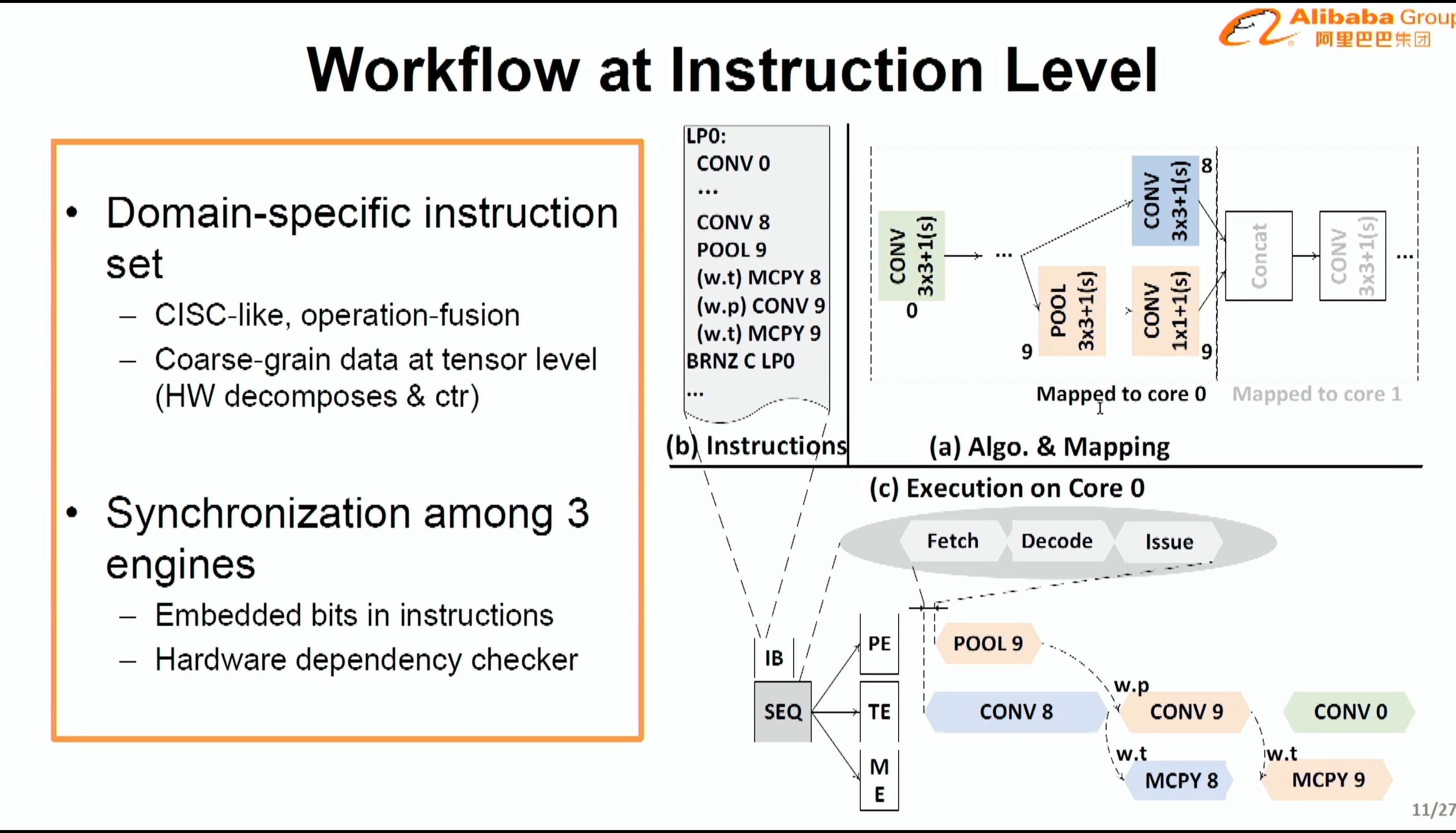
08:09PM EDT - Domain specific instruction set
08:09PM EDT - operation fusion
08:09PM EDT - CISC-like
08:10PM EDT - 3-engine sync
08:10PM EDT - two syncs - at compiler or at hardware
08:11PM EDT - Scalable task mapping
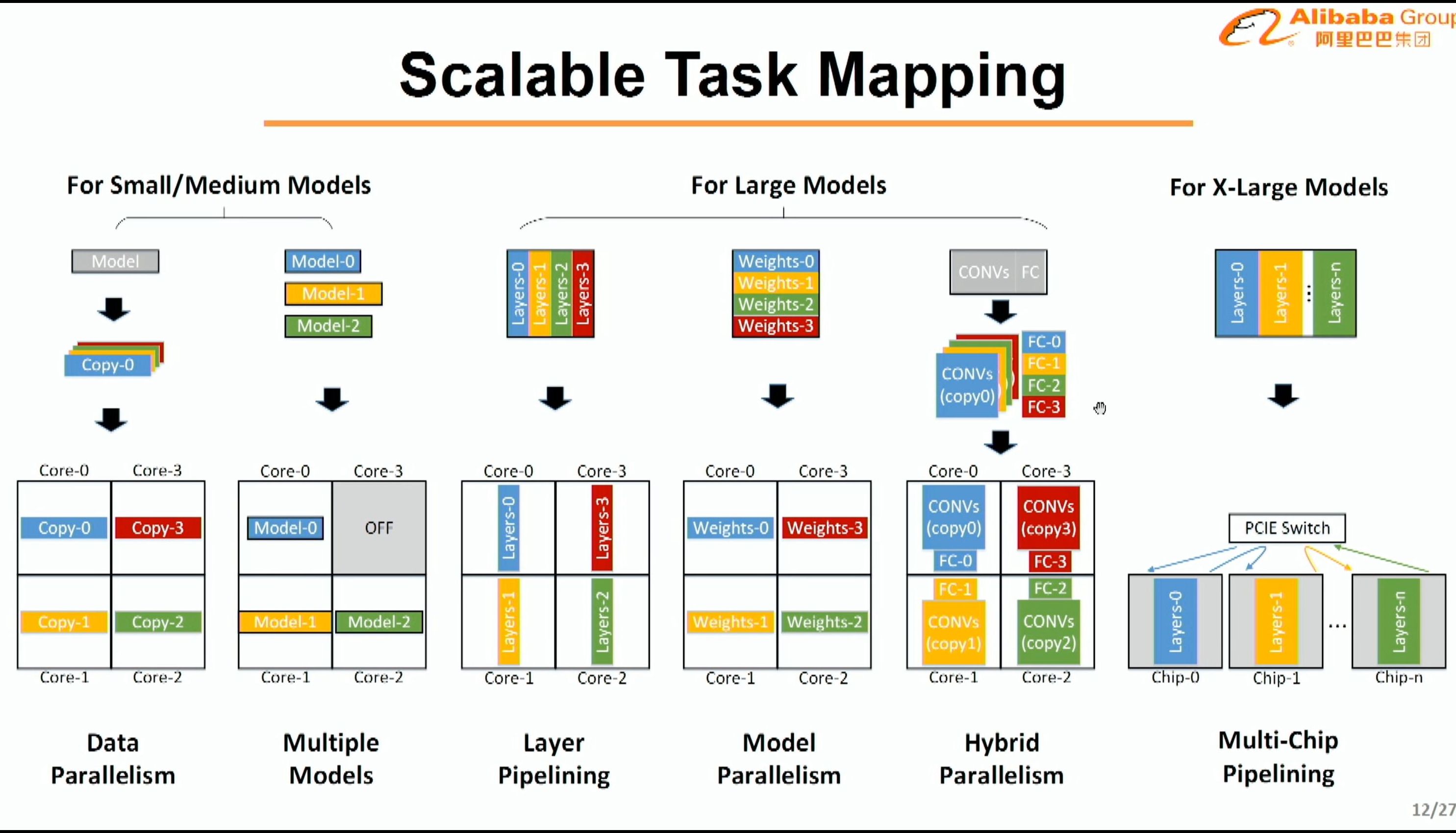
08:12PM EDT - Use PCIe switch for multi-chip pipelining
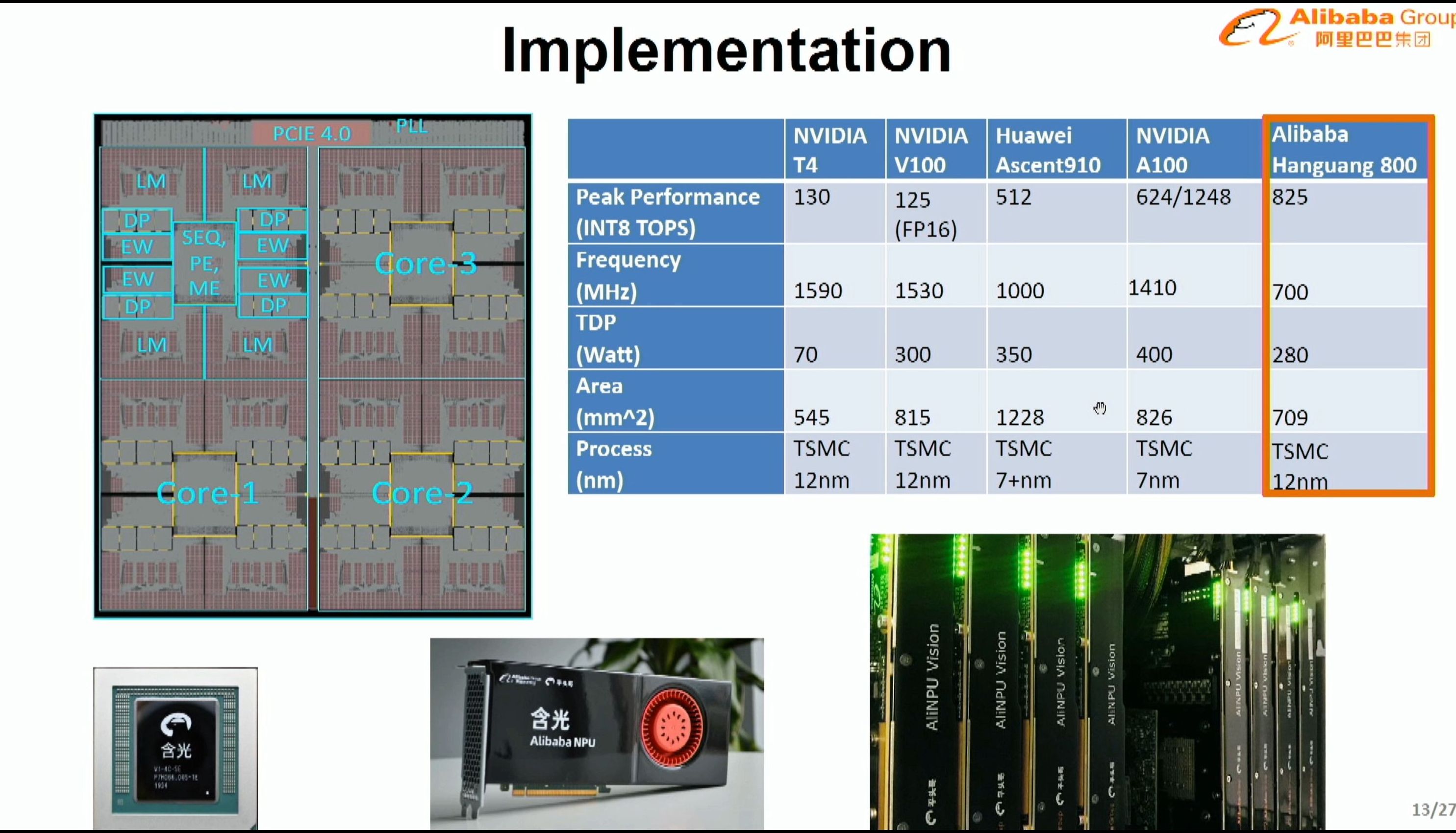
08:12PM EDT - 825 TOPs INT8 at 280W
08:12PM EDT - 700 MHz
08:12PM EDT - 709 mm2
08:12PM EDT - TSMC 12nm
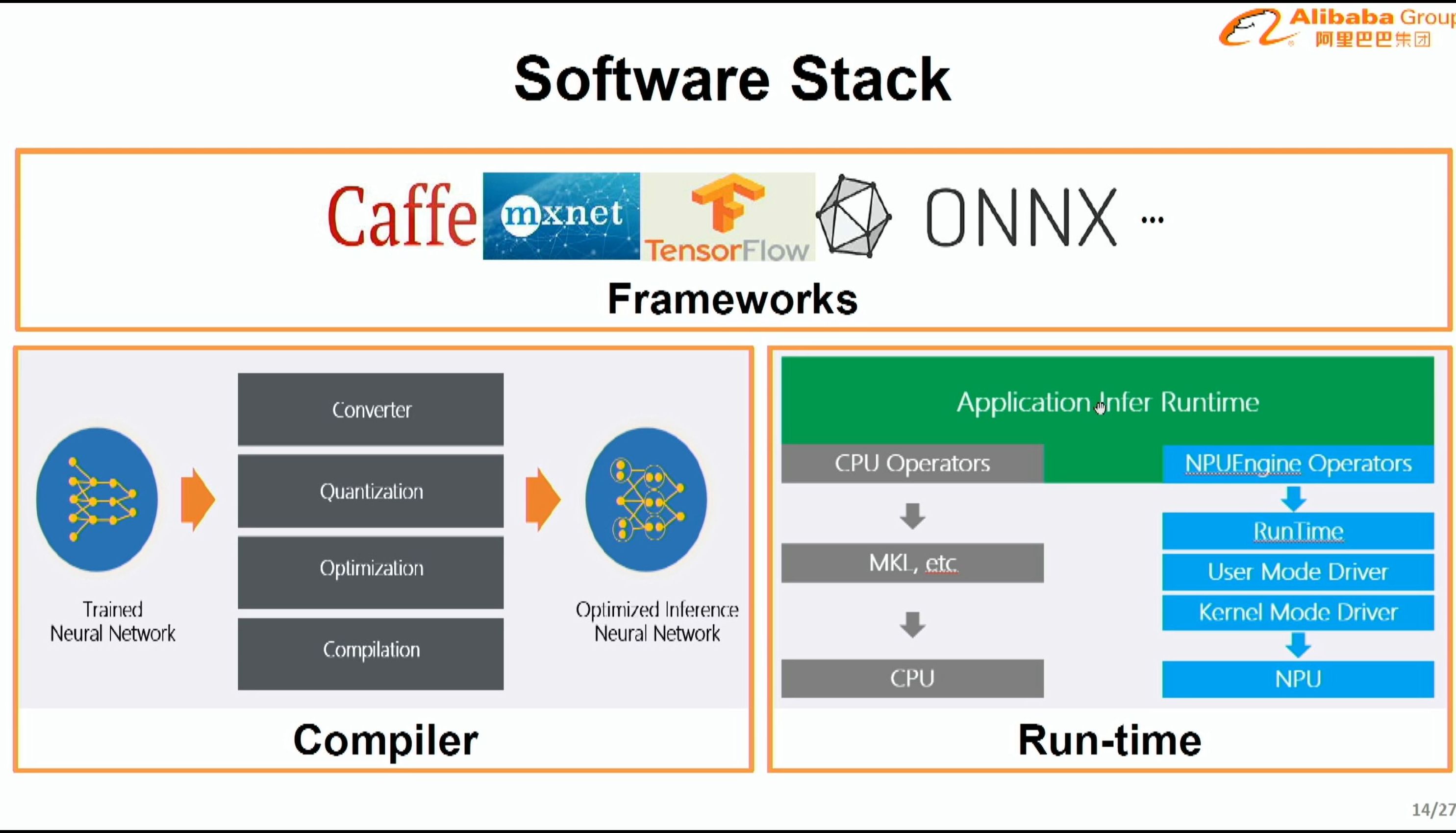
08:12PM EDT - Support most major frameworks

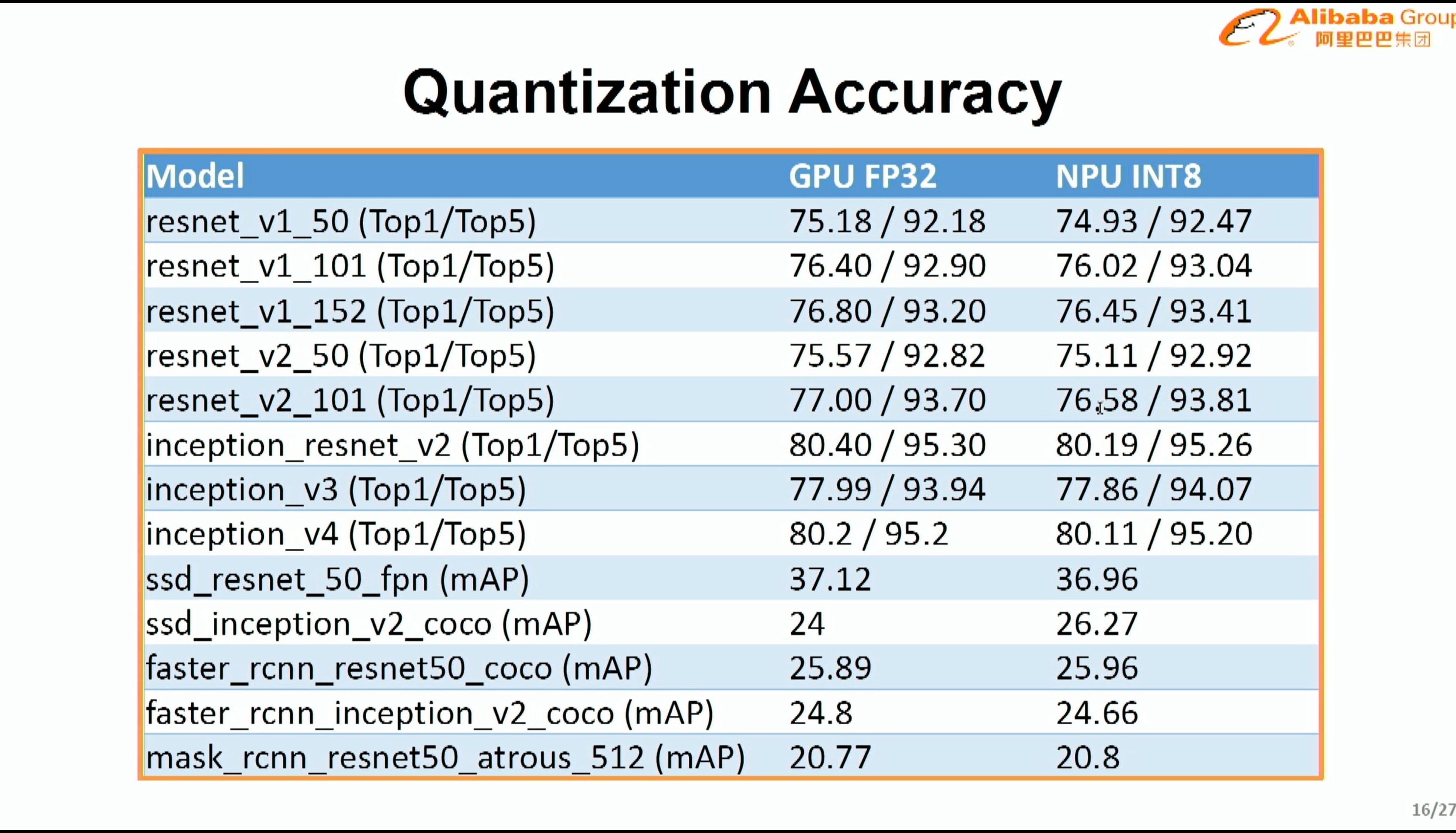
08:13PM EDT - Support for post-training quantization

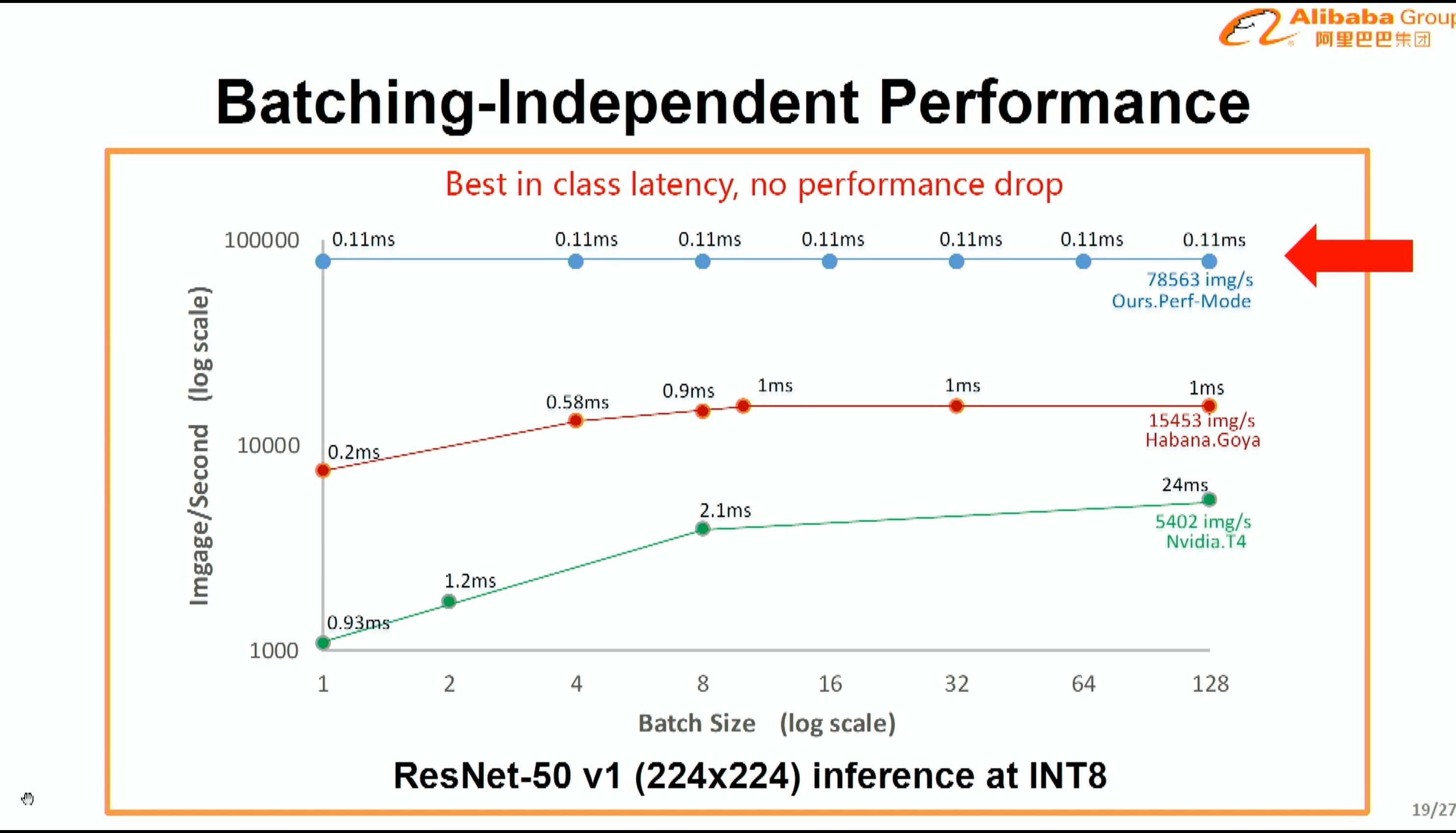
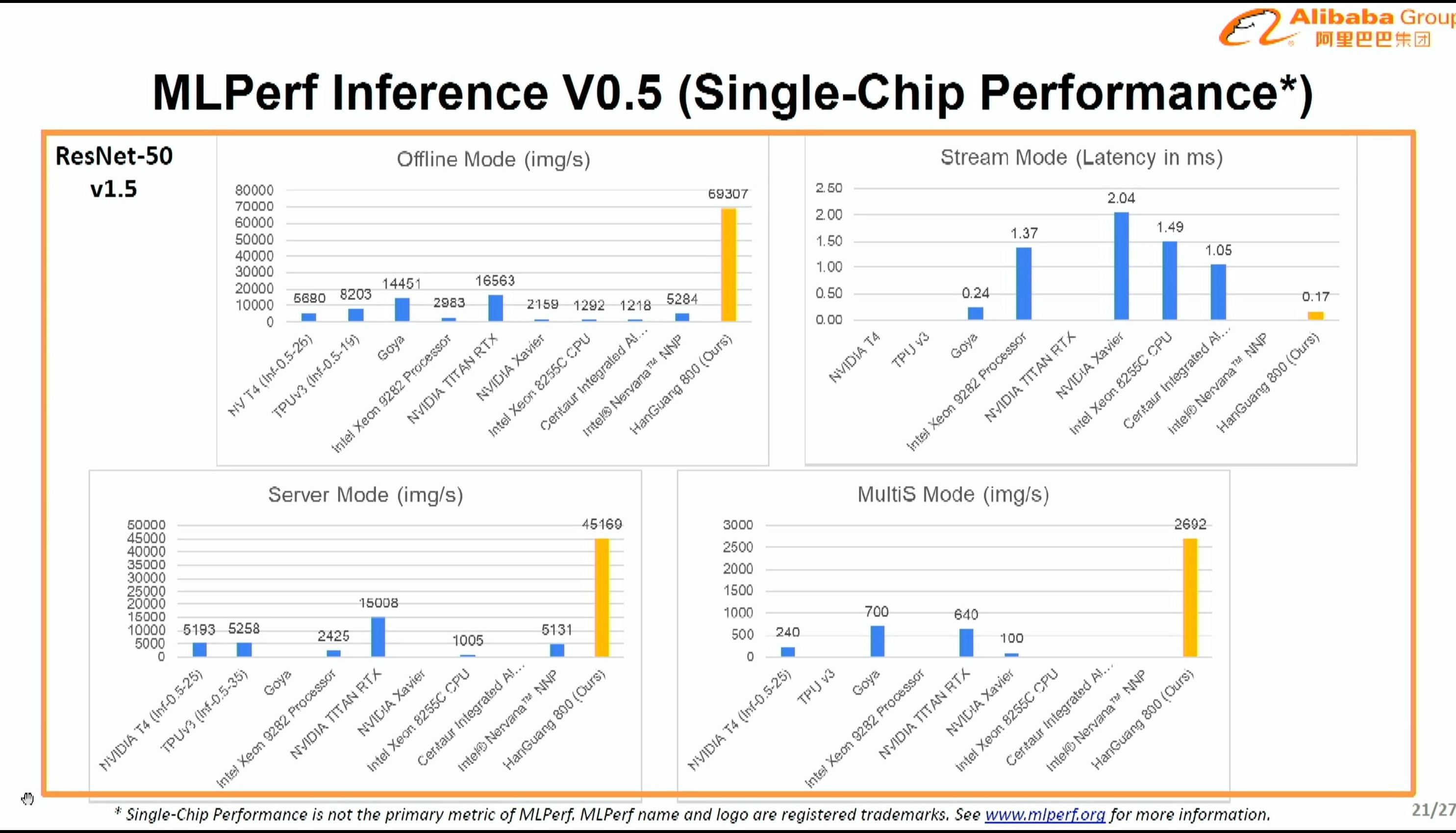
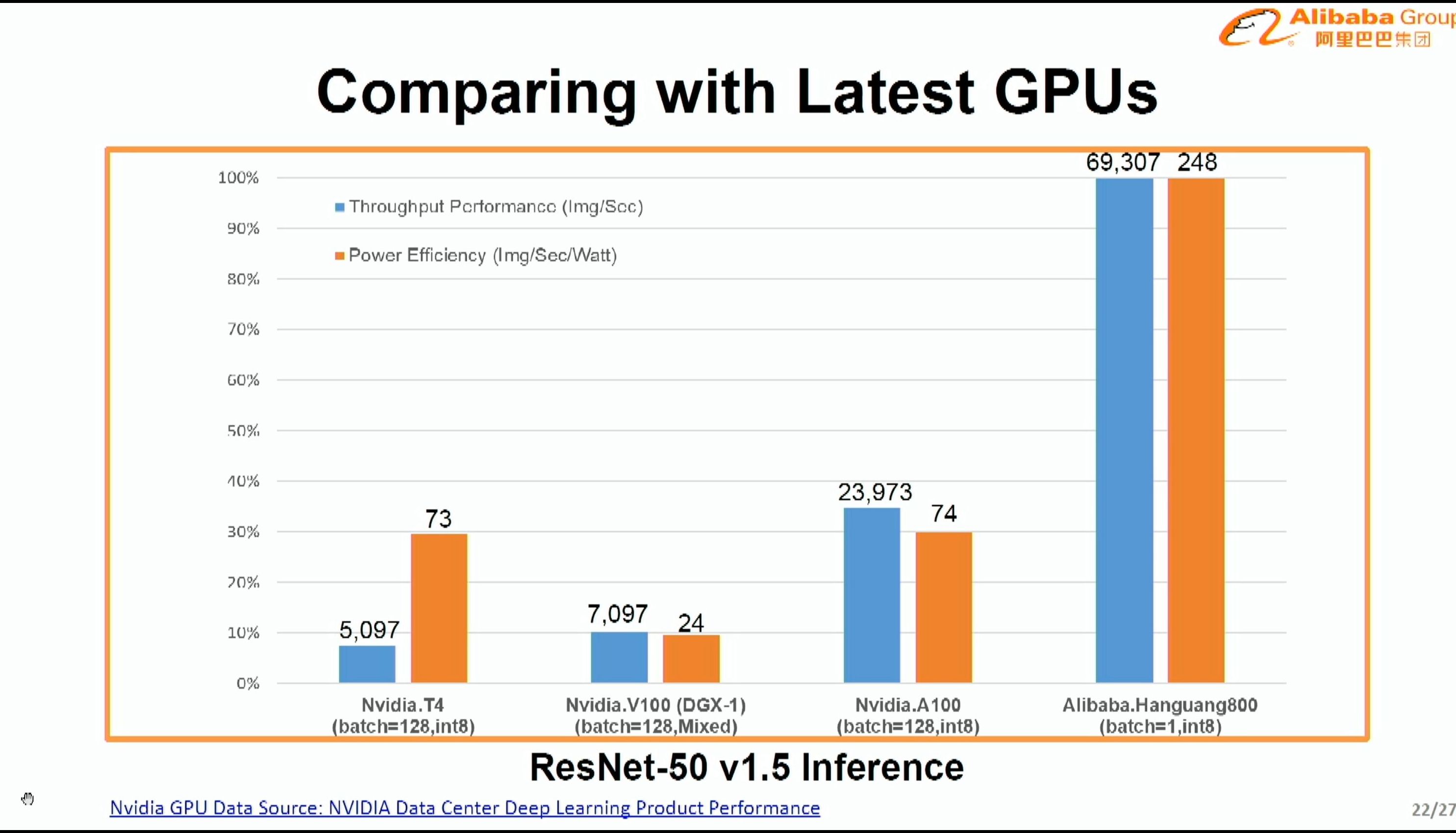
08:15PM EDT - At batch 1, NPU throughput outperfoms V100 at batch 128
08:15PM EDT - using Resnet50 v1
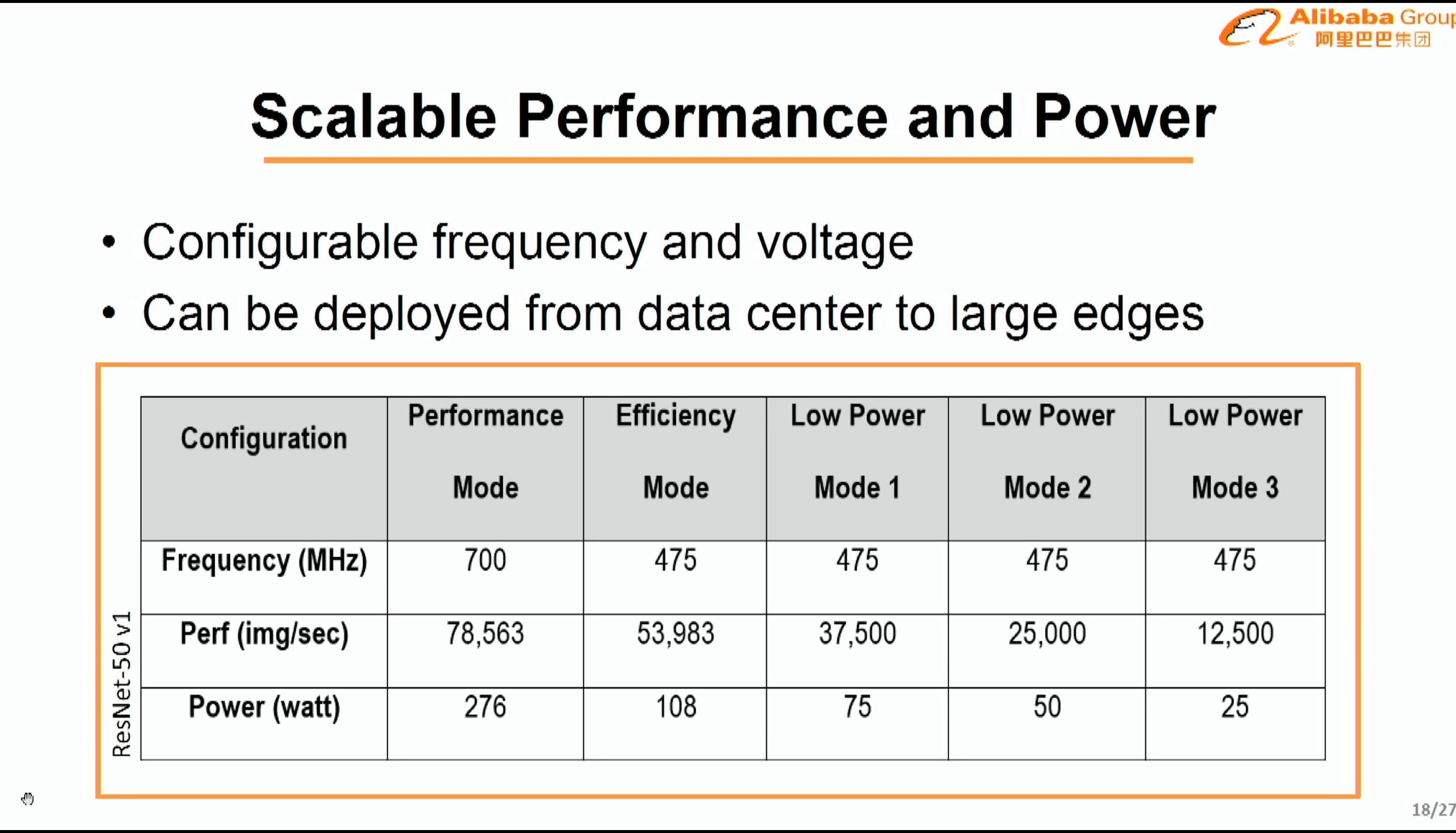
08:16PM EDT - Scalable perf and power
08:16PM EDT - 25W to 280W
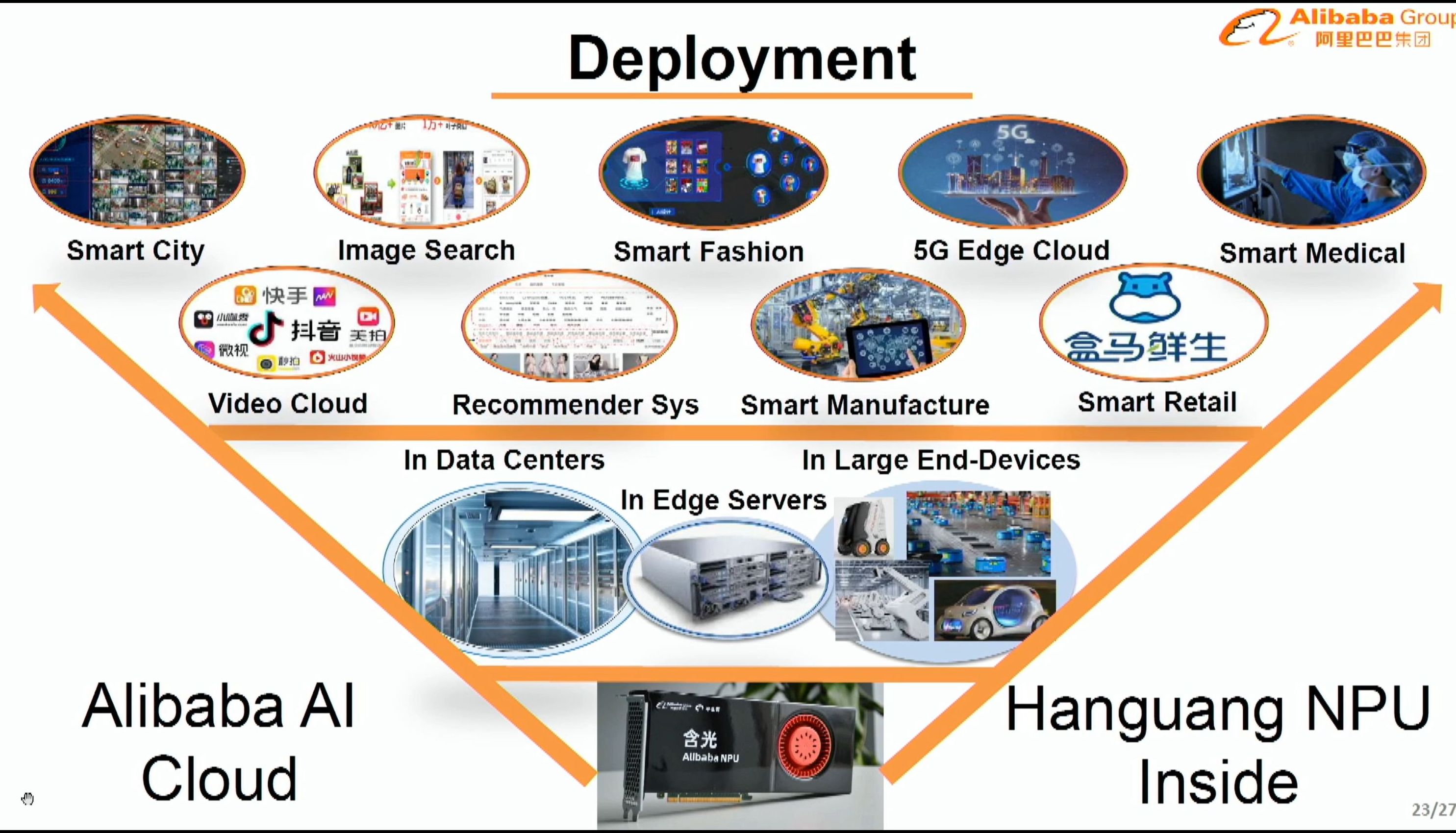
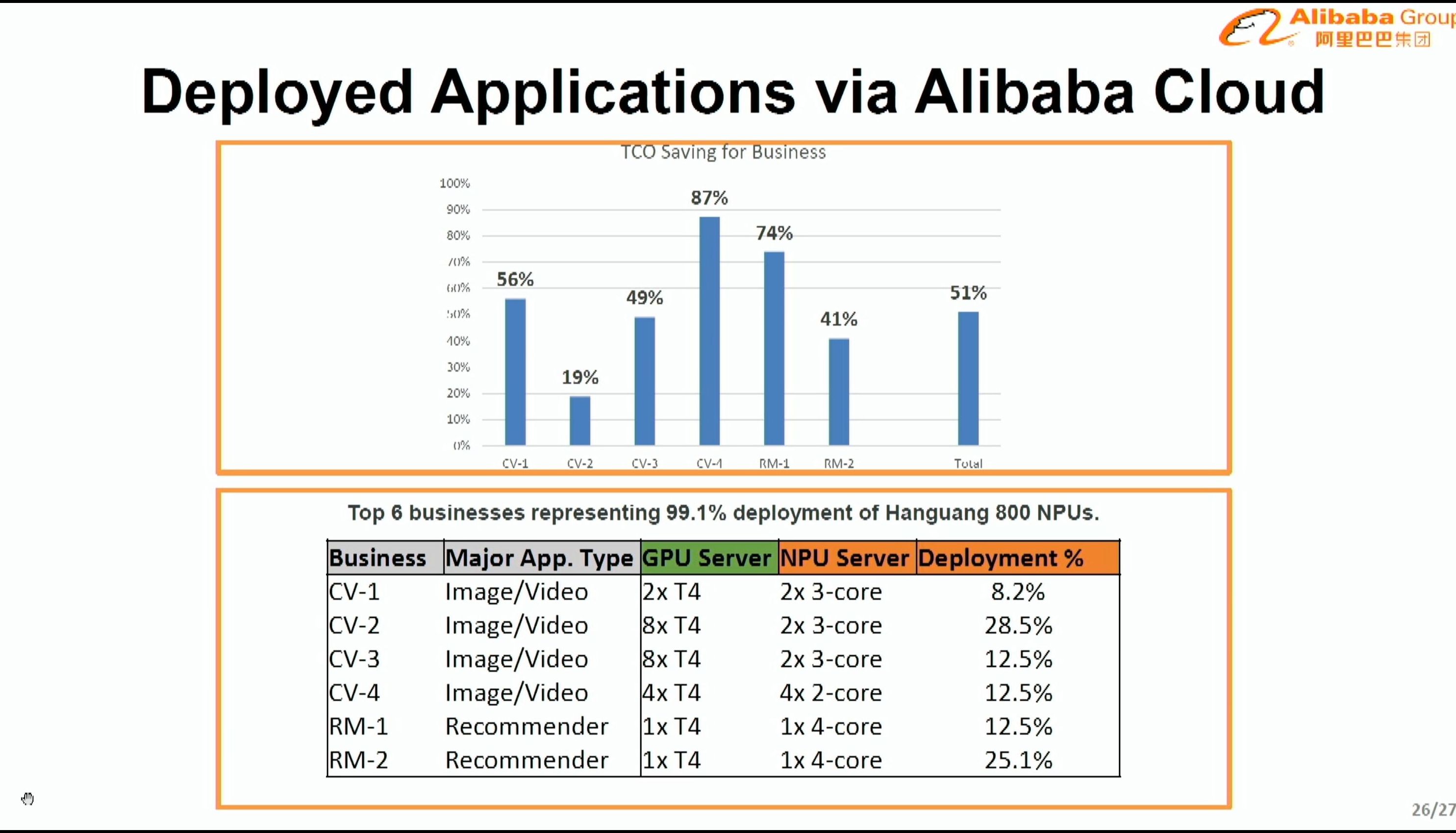
08:19PM EDT - Targeting lots of applications
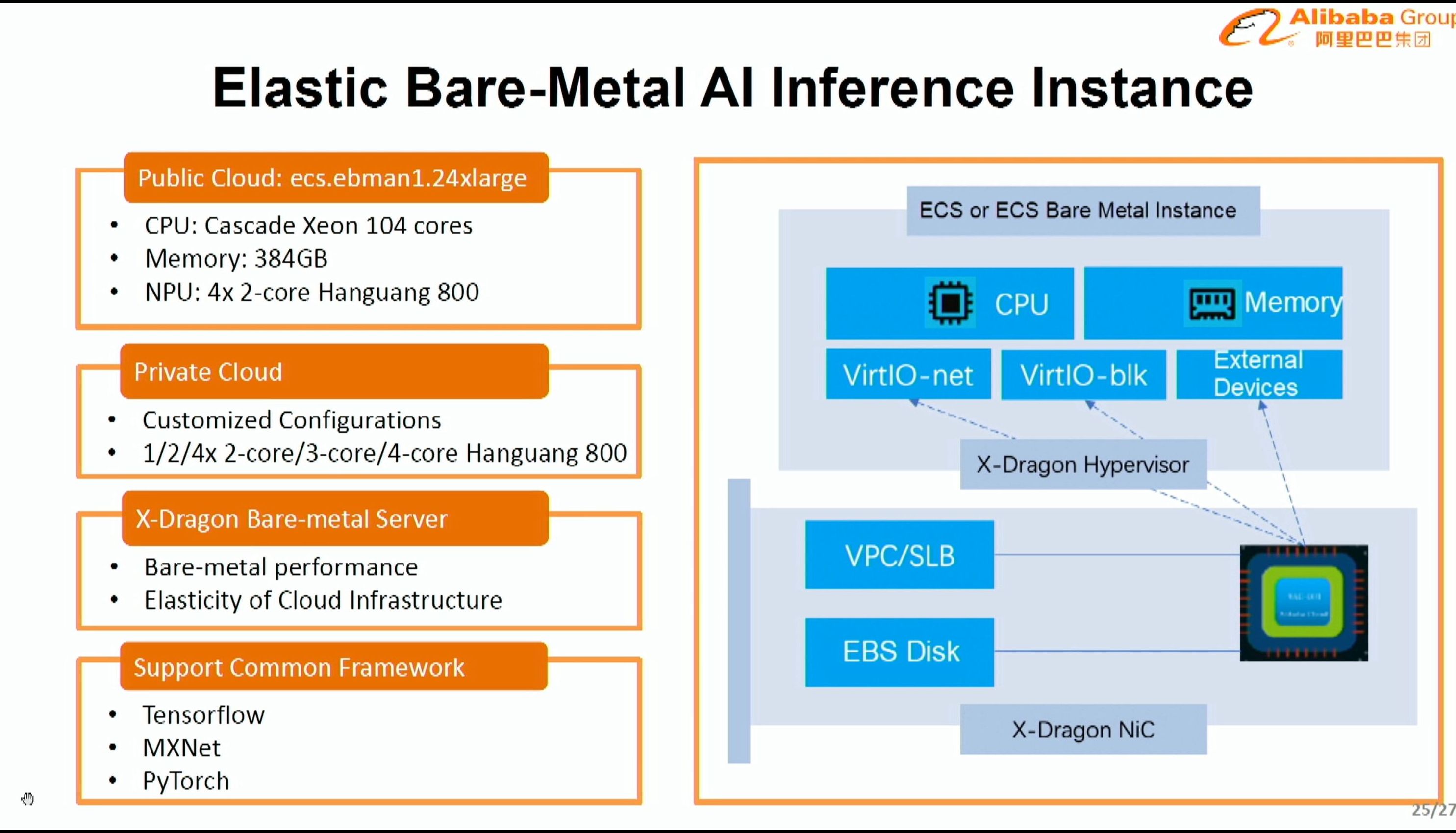
08:21PM EDT - ecs.ebman1.24xlarge us Cascade 104 cores with 4x2-core Hanguang 800
08:21PM EDT - public cloud
08:23PM EDT - Q&A Time
08:23PM EDT - Q: Recommendation engines - what other targets? A: Primarily Computer vision, after the optimizations, it's well suited for recommendation and search as well.
08:24PM EDT - Q: Replacing the T4? A: Yes
08:24PM EDT - Q: Embedding tables in host memory? A: correct
08:25PM EDT - Q: Support workloads > 192 MB? A: Can enable multiple chips and chip-to-chip through PCIe
08:25PM EDT - Q: Sparsity engine for weights and activations? A: Just weights
08:26PM EDT - Q: Non-2D convolution like Bert? A: We can map onto our chip and run it with precision to meet requirements, but performance is not satisfied. Size is a problem, so we need multiple chips which has a perf penalty
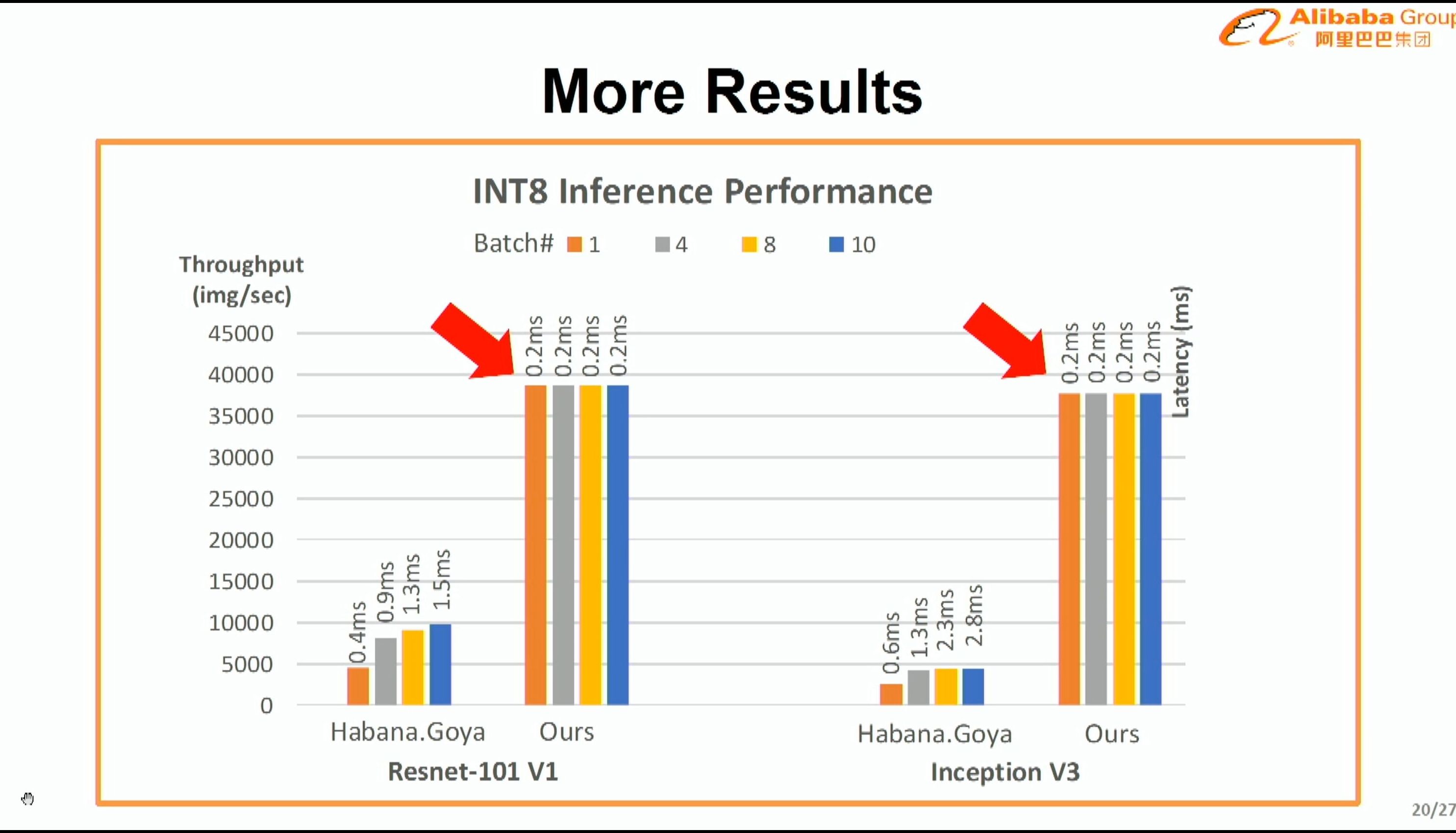
08:27PM EDT - Q: Why compare A100 and Goya at different batches to NPU? A: We can do single batch throughput better while keeping latency super low
08:27PM EDT - Tjat
08:28PM EDT - That's a wrap. Now for the final talk - silicon photonics!
08:28PM EDT - .








0 Comments
View All Comments