Hot Chips 2021 Live Blog: Machine Learning (Graphcore, Cerebras, SambaNova, Anton)
by Dr. Ian Cutress on August 24, 2021 2:25 PM EST
02:28PM EDT - Welcome to Hot Chips! This is the annual conference all about the latest, greatest, and upcoming big silicon that gets us all excited. Stay tuned during Monday and Tuesday for our regular AnandTech Live Blogs.
02:30PM EDT - Start here in a couple minutes
02:30PM EDT - Friend of AT, David Kanter, is chair for this session
02:32PM EDT - 'ML is not the only game in town'
02:33PM EDT - First talk is CO-founder, CTO, Graphcore, Simon Knowles. Colossus MK2

02:34PM EDT - Designed for AI
02:34PM EDT - New structural type of processor - the IPU

02:34PM EDT - 'Why do we need new silicon for AI'
02:35PM EDT - Embracing graph data through AI

02:36PM EDT - Classic scaling has ended
02:36PM EDT - Creating hardware to solve graphs
02:37PM EDT - Control program can control the graph compute in the best way to run on specialized hardware
02:37PM EDT - Hardware abstraction - tiles with processors and memory with a IO interconnect
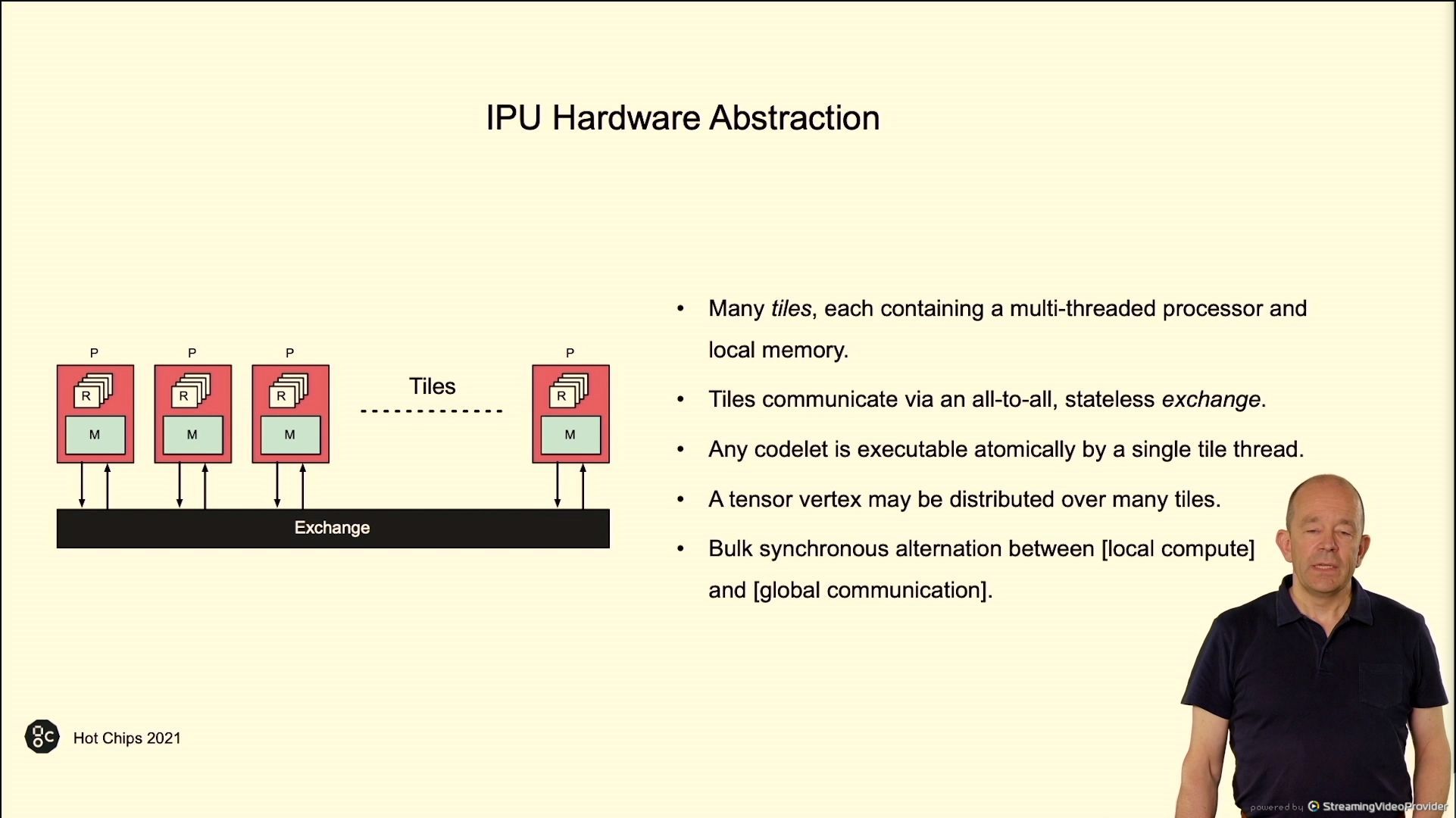
02:37PM EDT - bulk synchronous parallel compute
02:38PM EDT - thread fences for communication

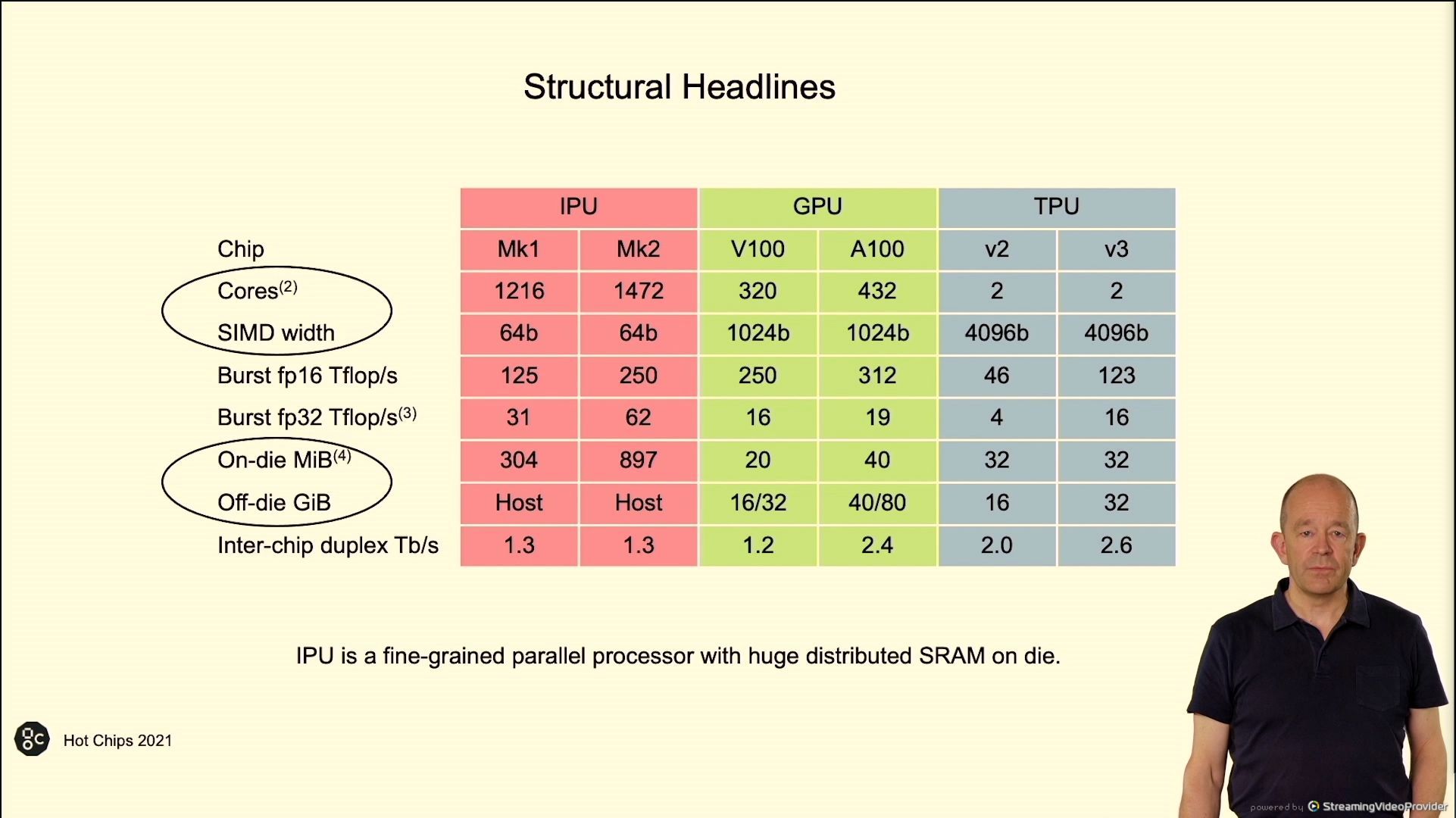
02:38PM EDT - 'record for real transistors on a chip'
02:38PM EDT - This chip has more transistors on it than any other N7 chip from TSMC
02:38PM EDT - within one reticle
02:39PM EDT - 896 MiB of SRAM on N7

02:40PM EDT - 4 IPUs in a 1U
02:40PM EDT - Lightweight proxy host
02:41PM EDT - 1.2 Tb/s off-chassis IO
02:41PM EDT - 800-1200 W typical, 1500W peak
02:41PM EDT - Can use Pytorch, tensorflow, ONNX, but own Poplar software stack is preferred
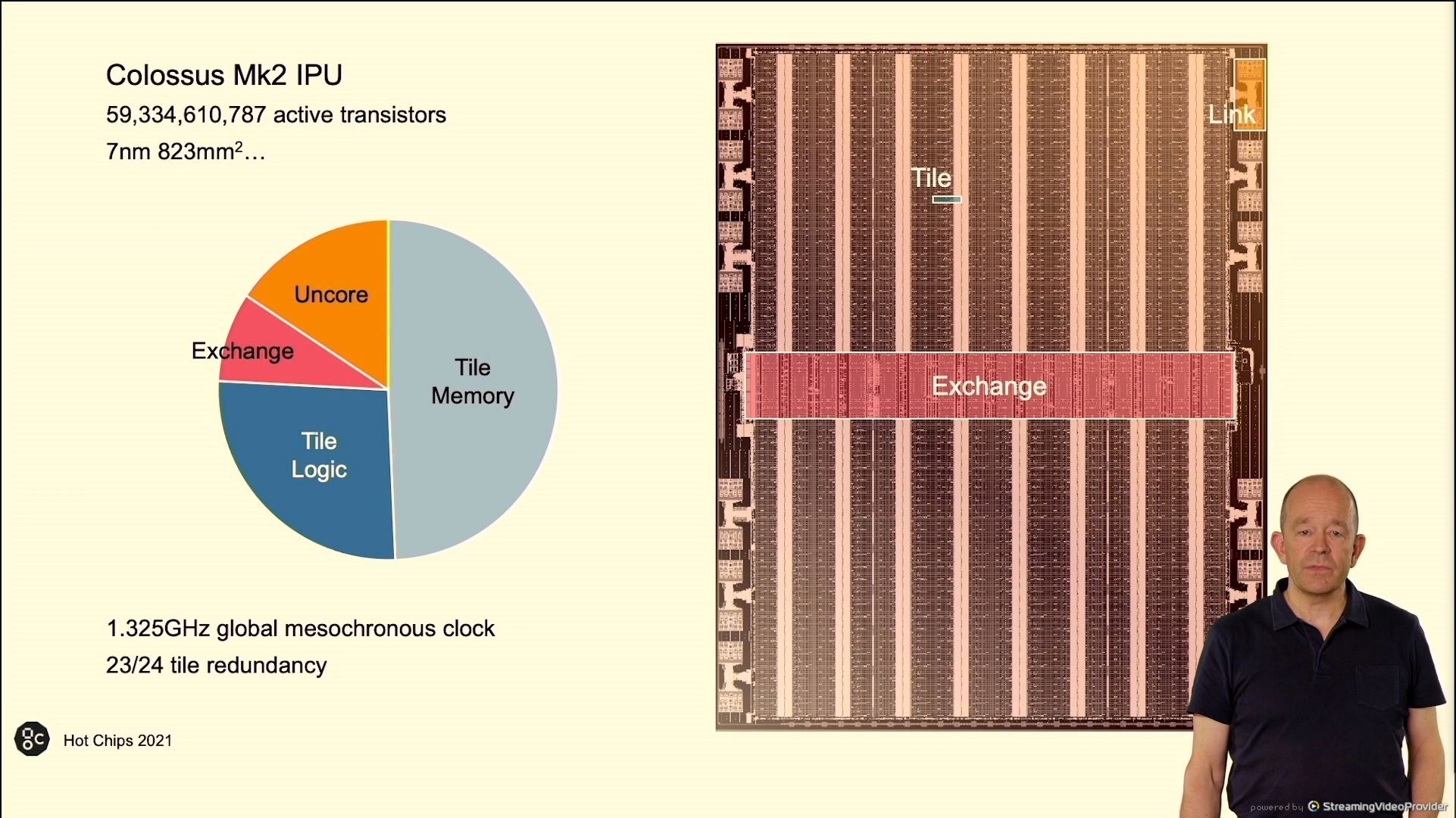
02:43PM EDT - Half the die is memory
02:43PM EDT - 24 tiles, 23 are used to give redundancy
02:43PM EDT - 25 GHz global clock
02:43PM EDT - 823 mm2, TSMC N7
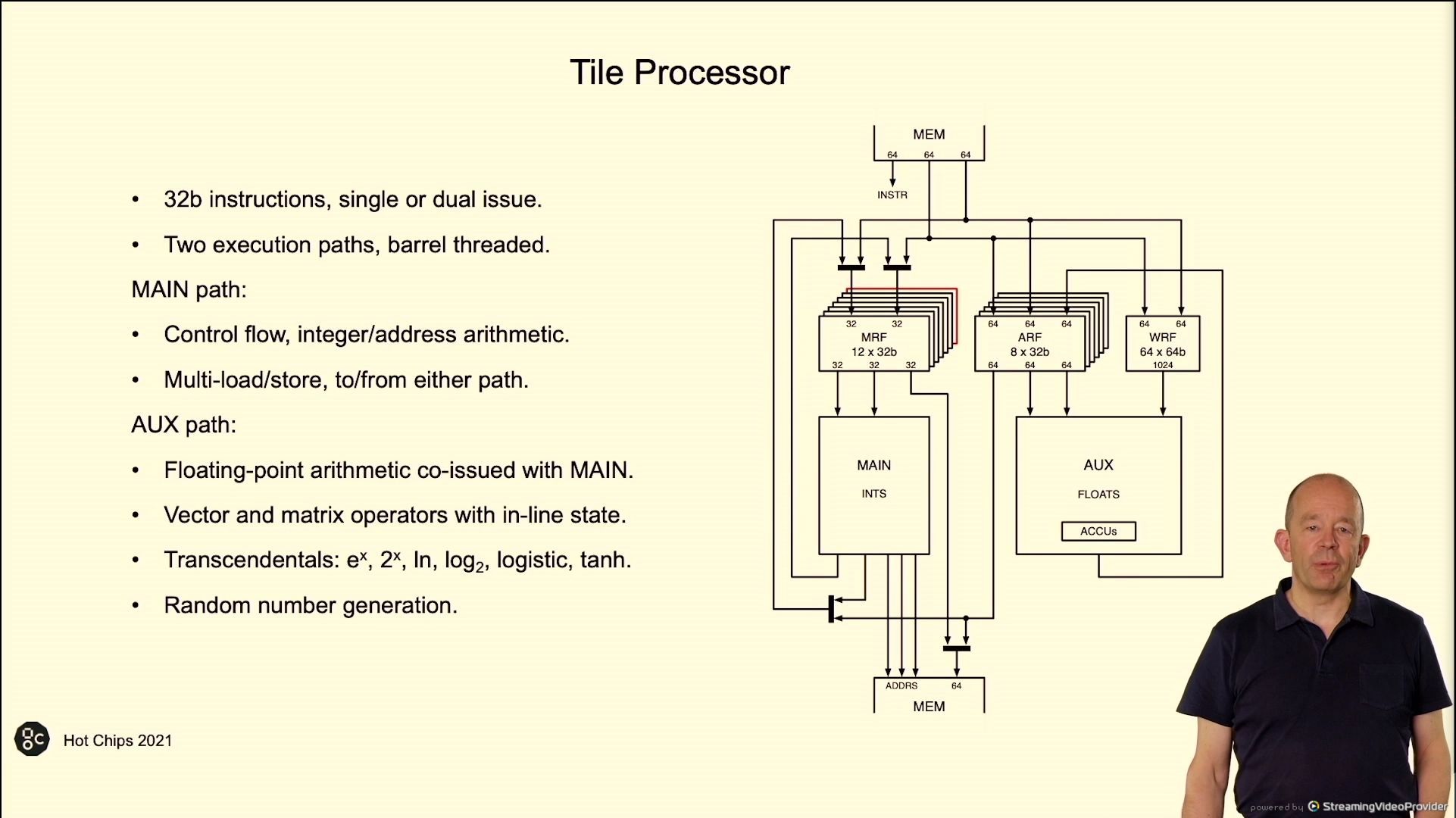
02:44PM EDT - 32 bit instructions, single or dual issue
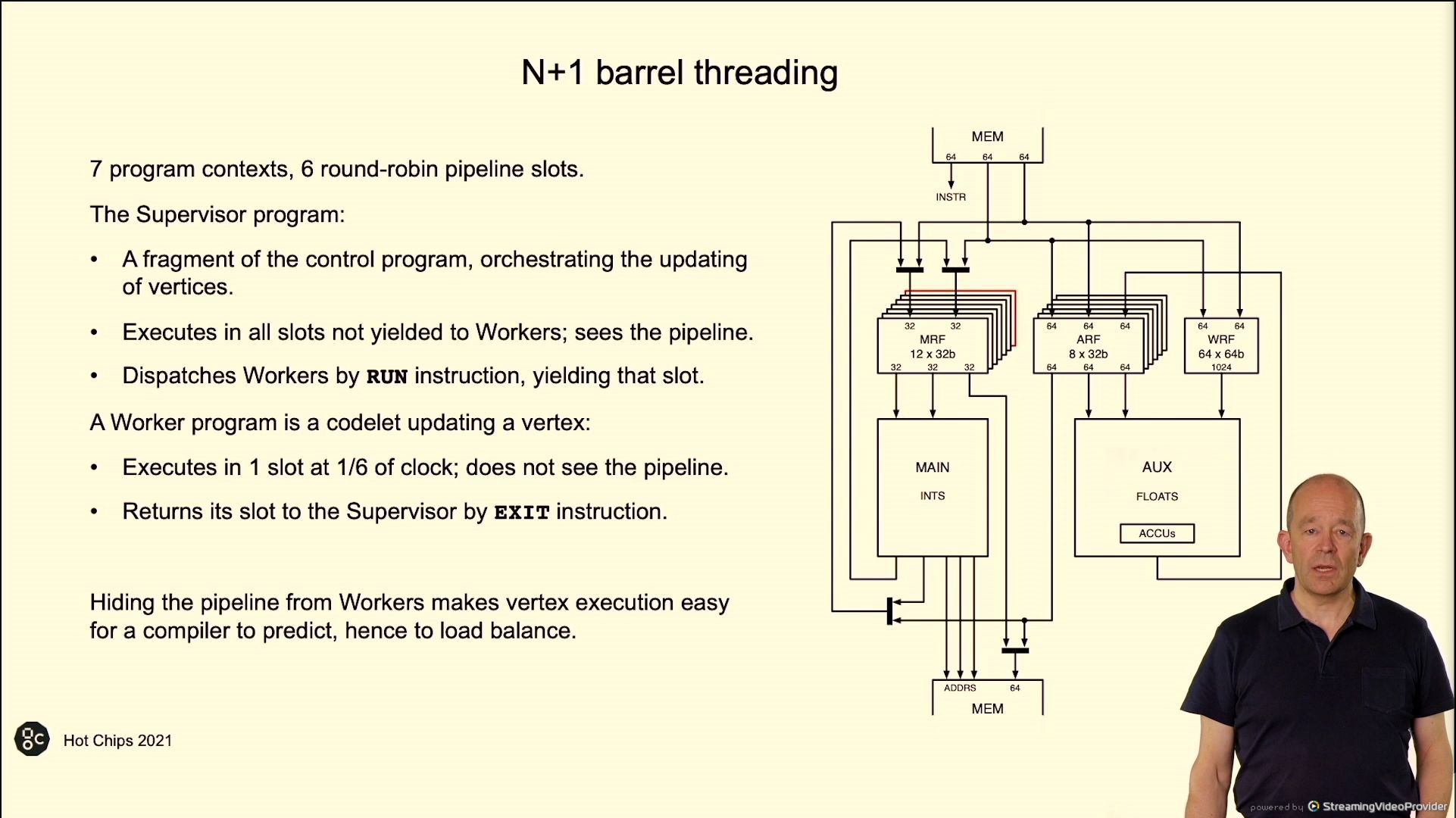
02:44PM EDT - 6 execution threads, launch worker threads to do the heavy lifting
02:45PM EDT - Aim for load balancing

02:45PM EDT - 1.325 GHz* global clock
02:46PM EDT - 47 TB/s data-side SRAM access
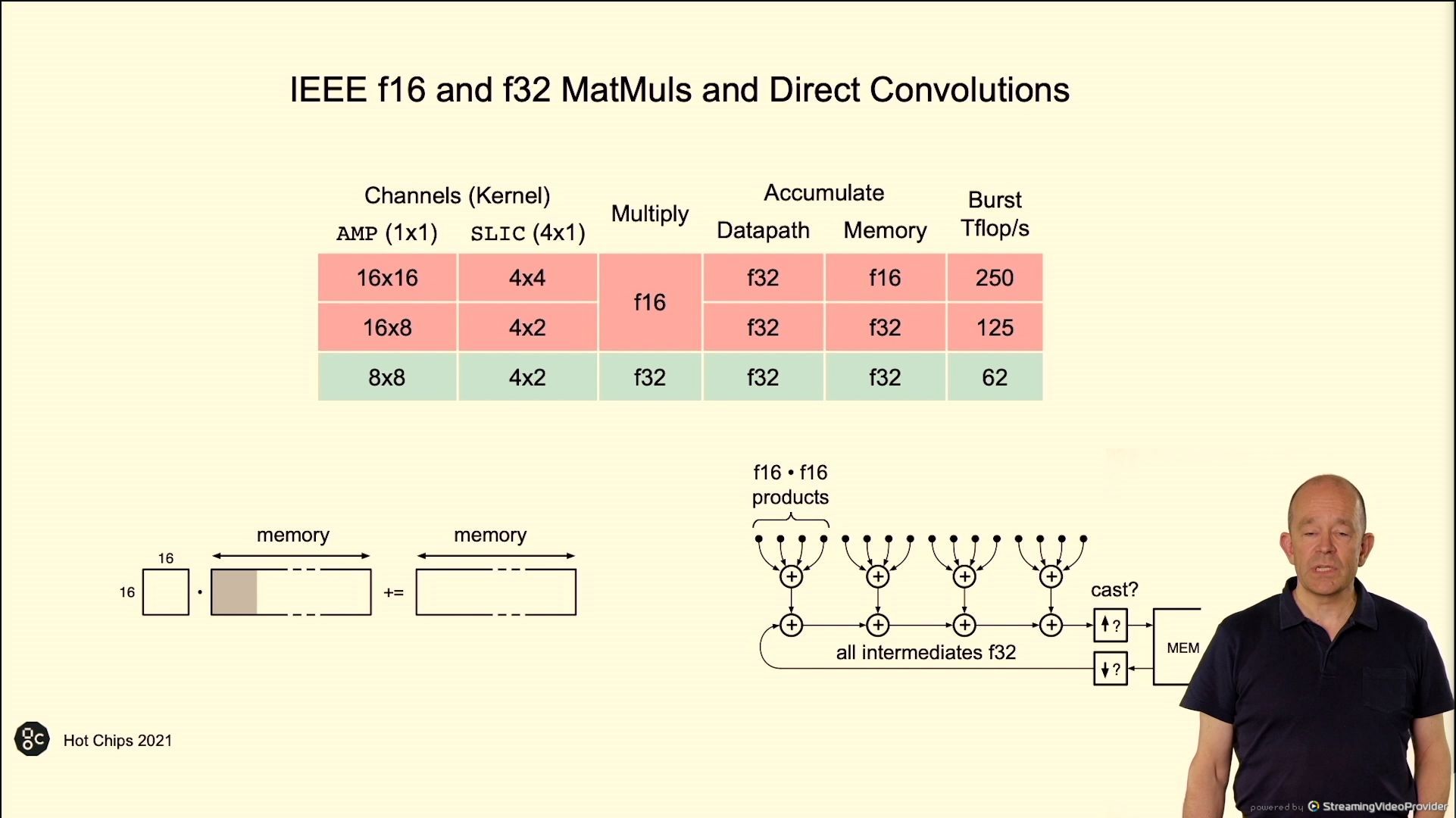
02:46PM EDT - FP16 and FP32 MatMul and convolutions
02:47PM EDT - TPU relies too much on large matrices for high performance

02:48PM EDT - Each tile can generate 128 random bits per cycle
02:48PM EDT - can round down stochastically
02:48PM EDT - at full speed
02:48PM EDT - Avoid FP32 data with stochastic rounding. Helps minimize rounding and energy use
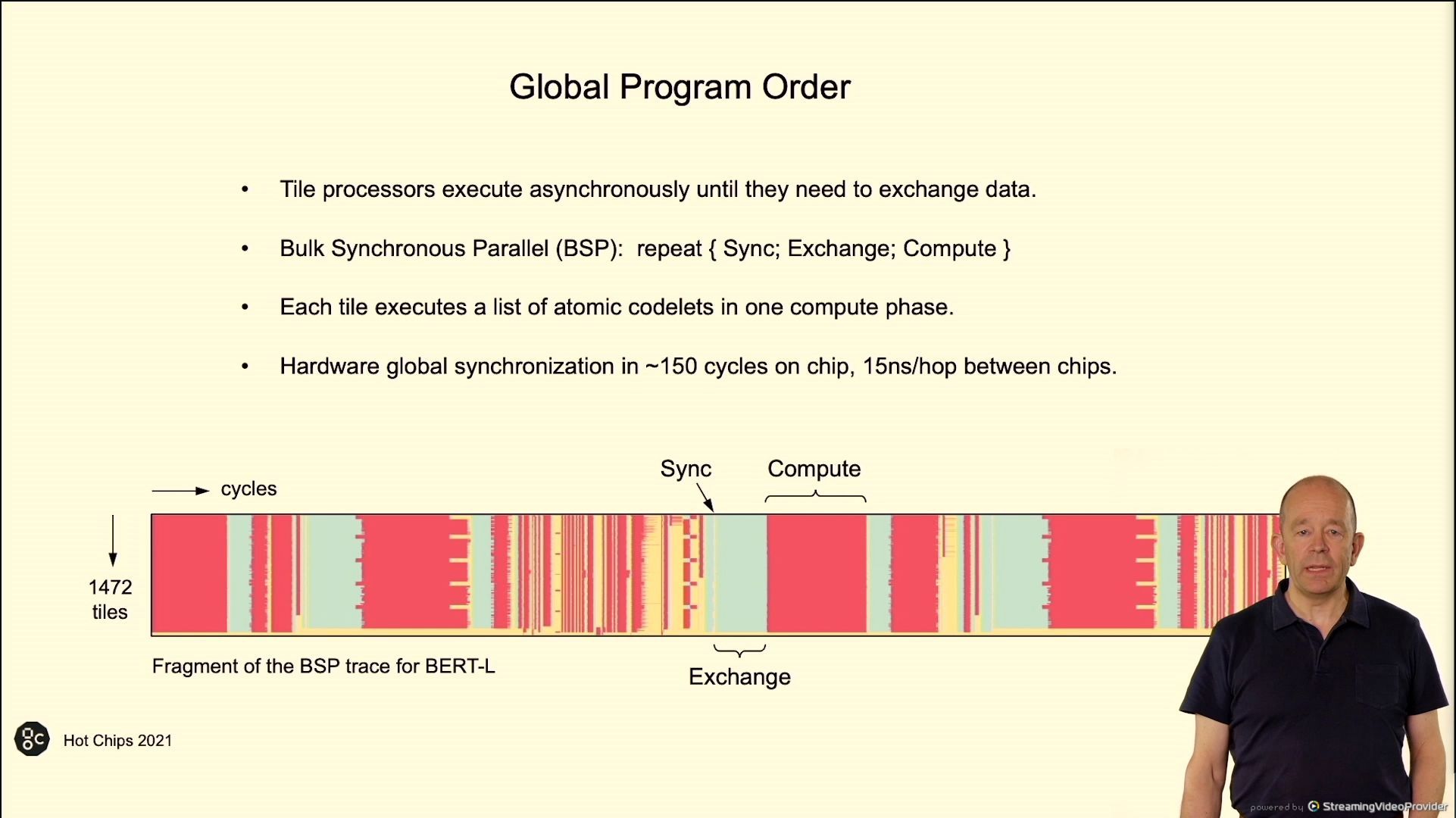
02:49PM EDT - Trace for program
02:49PM EDT - 60% cycles in compute, 30% in exchange, 10% in sync. Depends on the algorithm
02:50PM EDT - Compiler load balance the processors
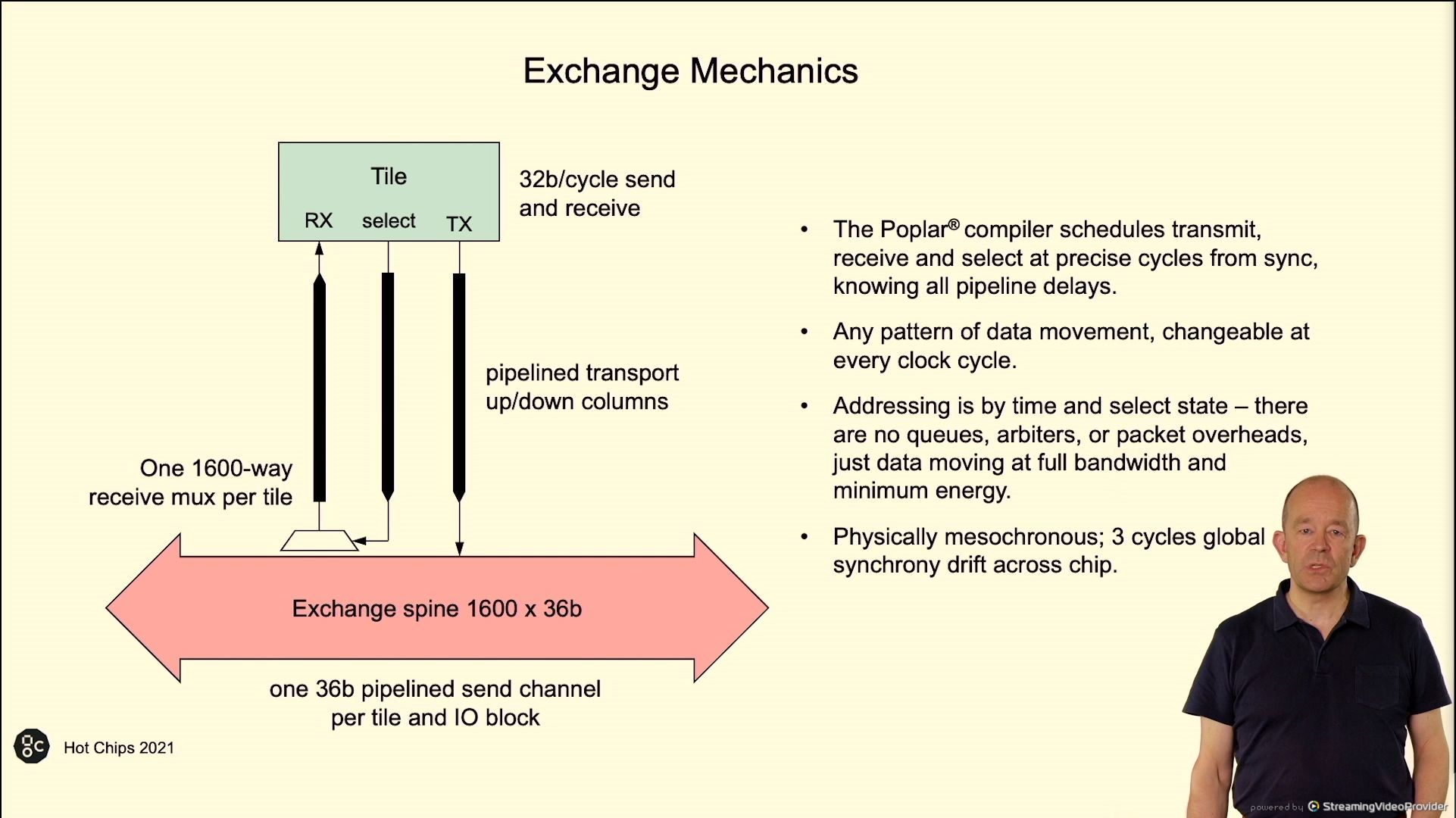
02:50PM EDT - Exchange spine
02:50PM EDT - 3 cycle drift across chip
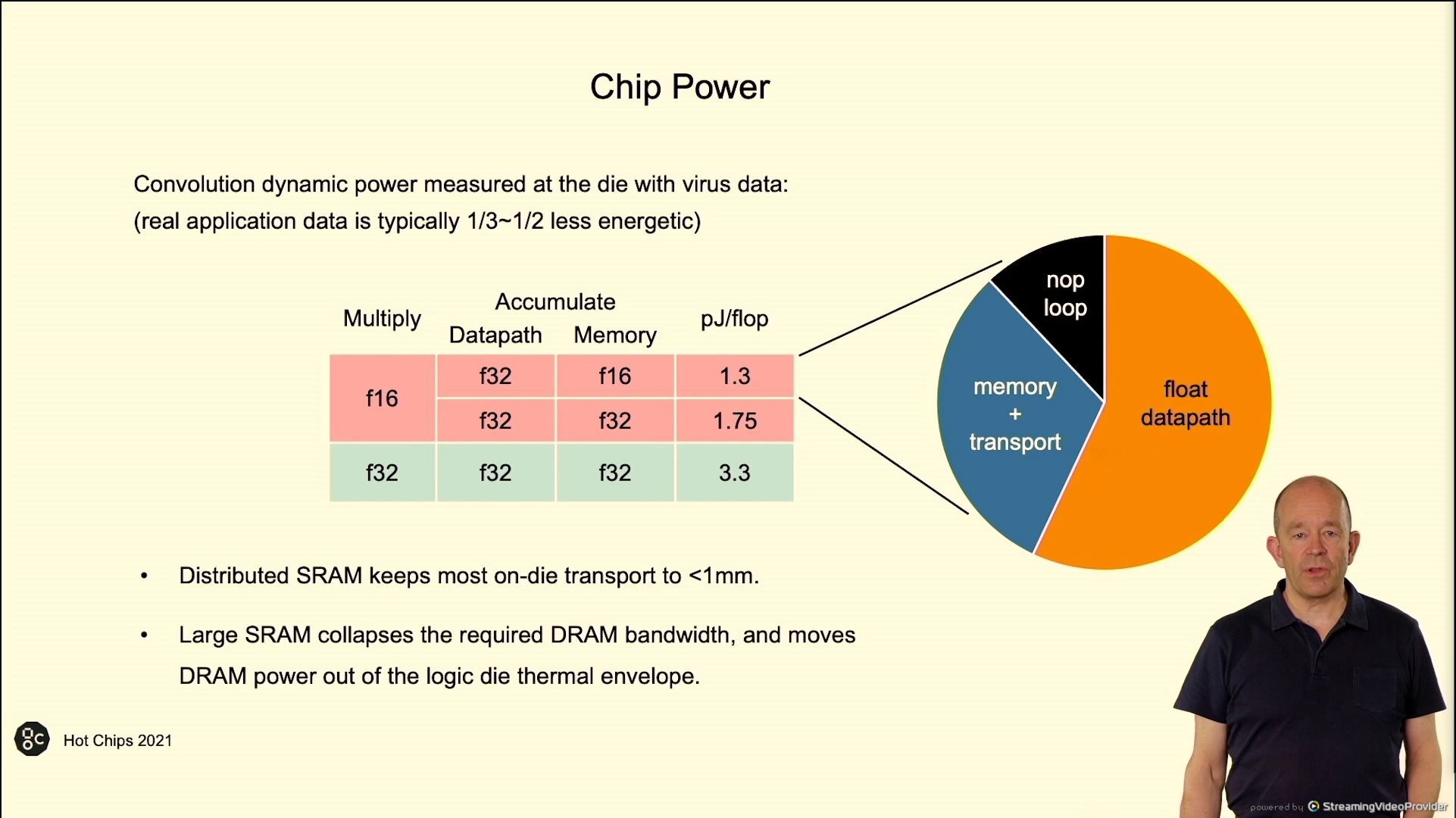
02:51PM EDT - Chip power
02:51PM EDT - pJ/flop
02:52PM EDT - 60/30/10 in the pie chart
02:52PM EDT - arithmetic energy dominates
02:52PM EDT - IPU more efficient in TFLOP/Watt

02:53PM EDT - Not using HBM - on die SRAM, low bandwidth DRAM
02:53PM EDT - DDR for model capacity
02:53PM EDT - HBM has a cost problem - IPU allows for DRAM
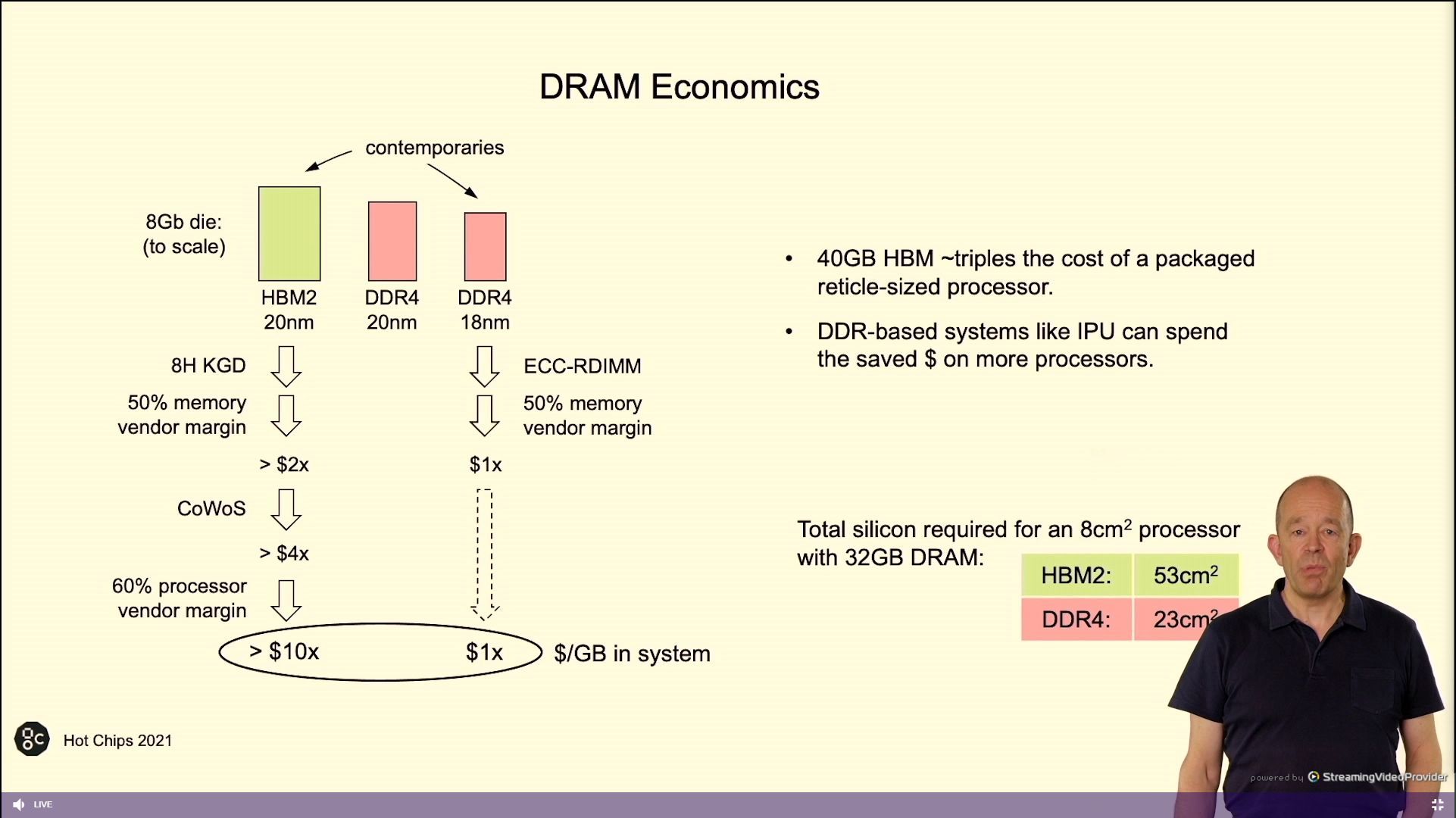
02:54PM EDT - 40 GB HBM triples the cost of a processor
02:54PM EDT - Added cost of CoWoS
02:54PM EDT - VEndor adds margin with CoWoS
02:54PM EDT - No such overhead with DDR
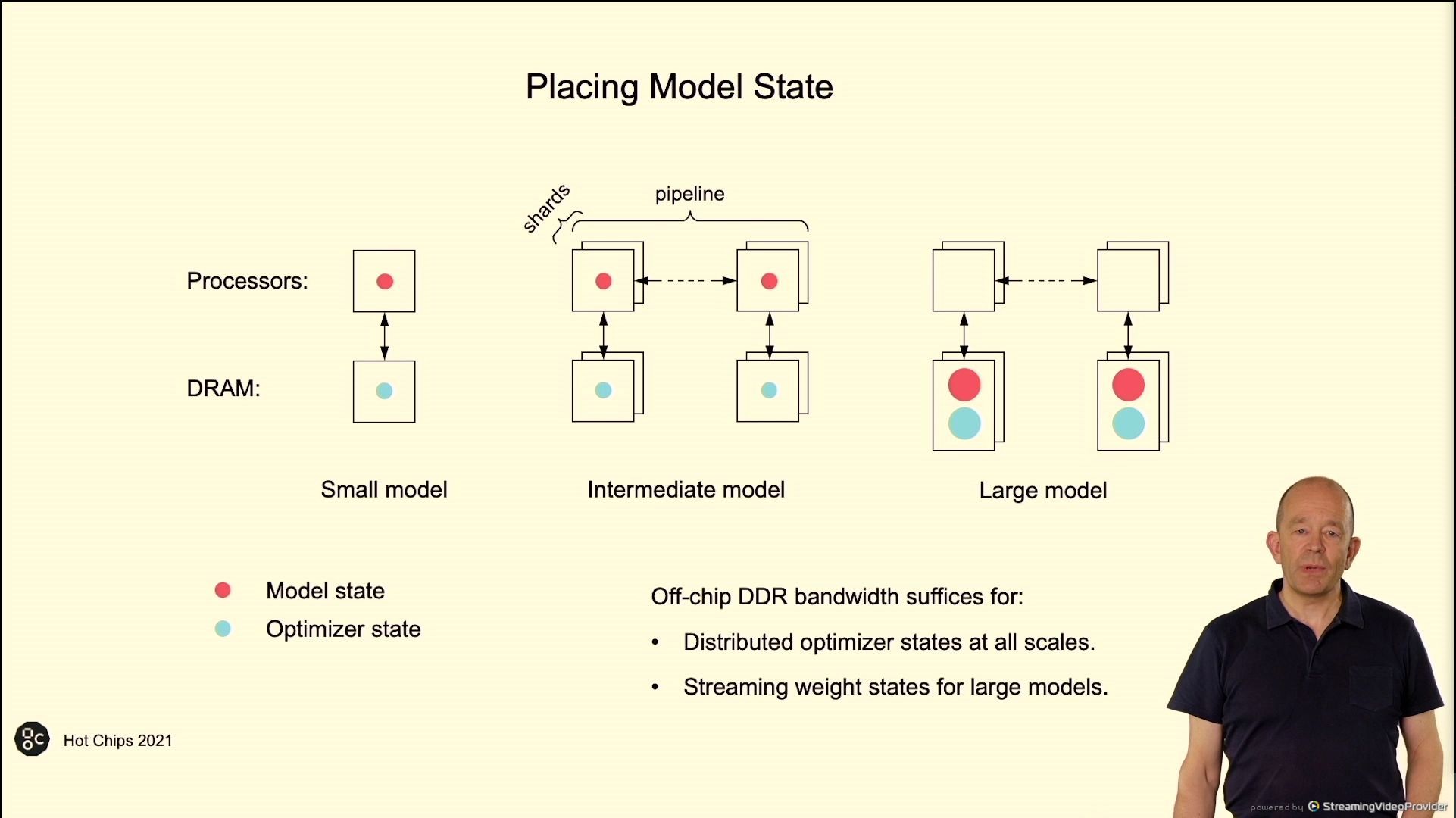
02:55PM EDT - Off-chip DDR bandwidth suffices for streaming weight states for large models
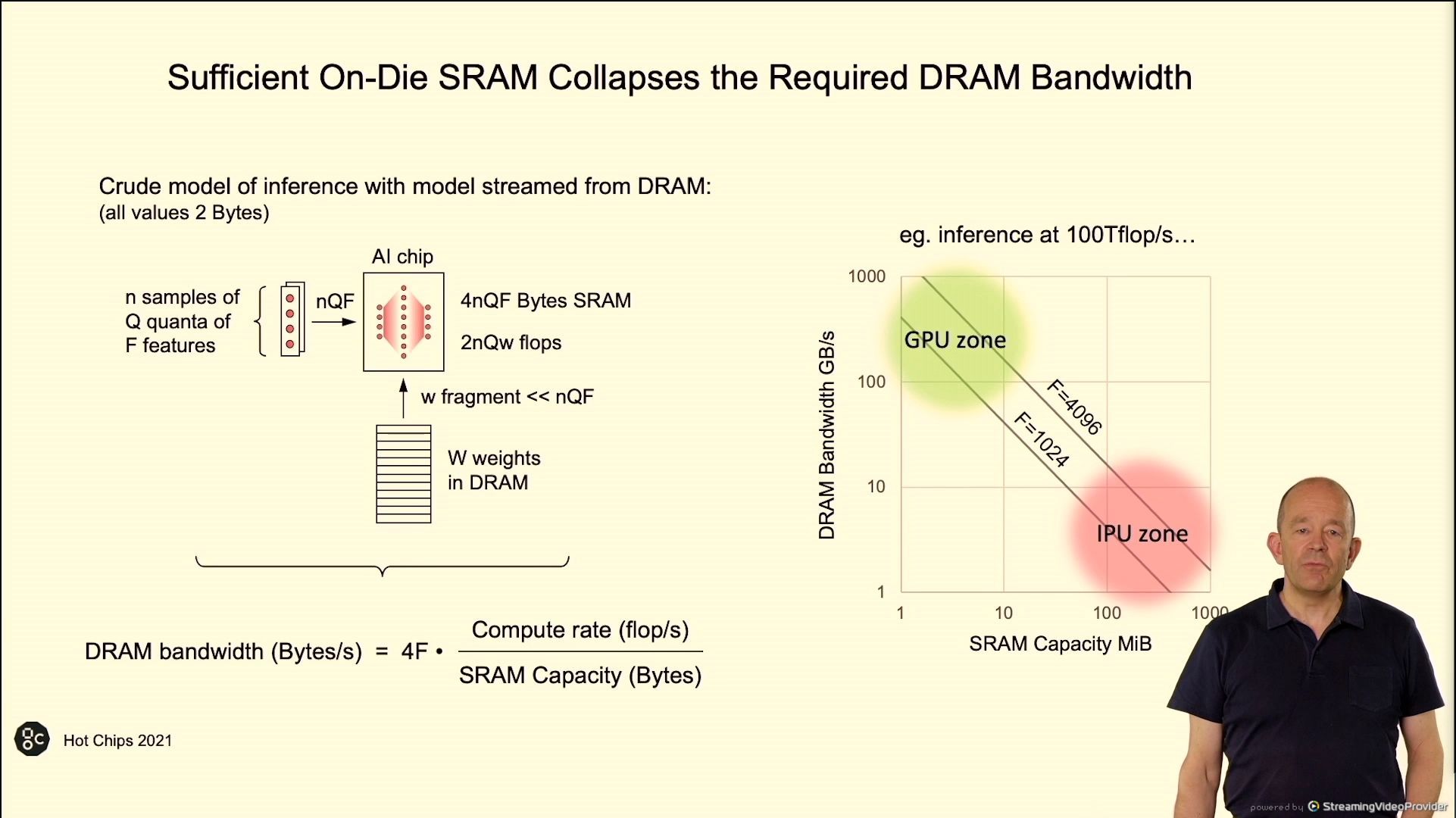
02:56PM EDT - More SRAM on chip means less DRAM bandwidth needed

02:58PM EDT - Q&A
03:00PM EDT - Q: Clocking is mesochrnous but static mesh - assume worst case clocking delays, or something else? A: Behaves as if syncronous. In practice, clocks and data chase each other. Fishbone layout of exchange it to make it straightforward
03:00PM EDT - Q: Are results deterministic? A: Yes because each thread and each tile has its own seed. Can manually set seeds
03:05PM EDT - Next Talk is Cerebras
03:05PM EDT - WSE-2 new system configurations


03:06PM EDT - 2016 started, 2019 WSE-1

03:06PM EDT - 2.6 trillion transistors
03:06PM EDT - 850k cores

03:07PM EDT - CS-2 system on sale today
03:07PM EDT - it costs a few million
03:07PM EDT - Traditional approaches can't keep up

03:08PM EDT - Up-coming multi-trillion parameter models
03:08PM EDT - something has to change in silicon - need a better approach
03:08PM EDT - but large models are hard to support

03:08PM EDT - Massive memory, massive compute, massive IO
03:09PM EDT - More partitioning of model across more chips
03:09PM EDT - More sync
03:09PM EDT - Becomes a distribution complexity problem, rather than a NN problem
03:09PM EDT - How to solve this problem Cerebras style
03:09PM EDT - Cerebras for Extreme Scale - new style of execution, support up to 120 trillion parameters
03:09PM EDT - same as synapses in brain
03:10PM EDT - also needs to run fast
03:10PM EDT - up to 192 WSE-2 with near linear perf scaling
03:10PM EDT - 10x weight sparsity speedup
03:10PM EDT - scales easily with push of button

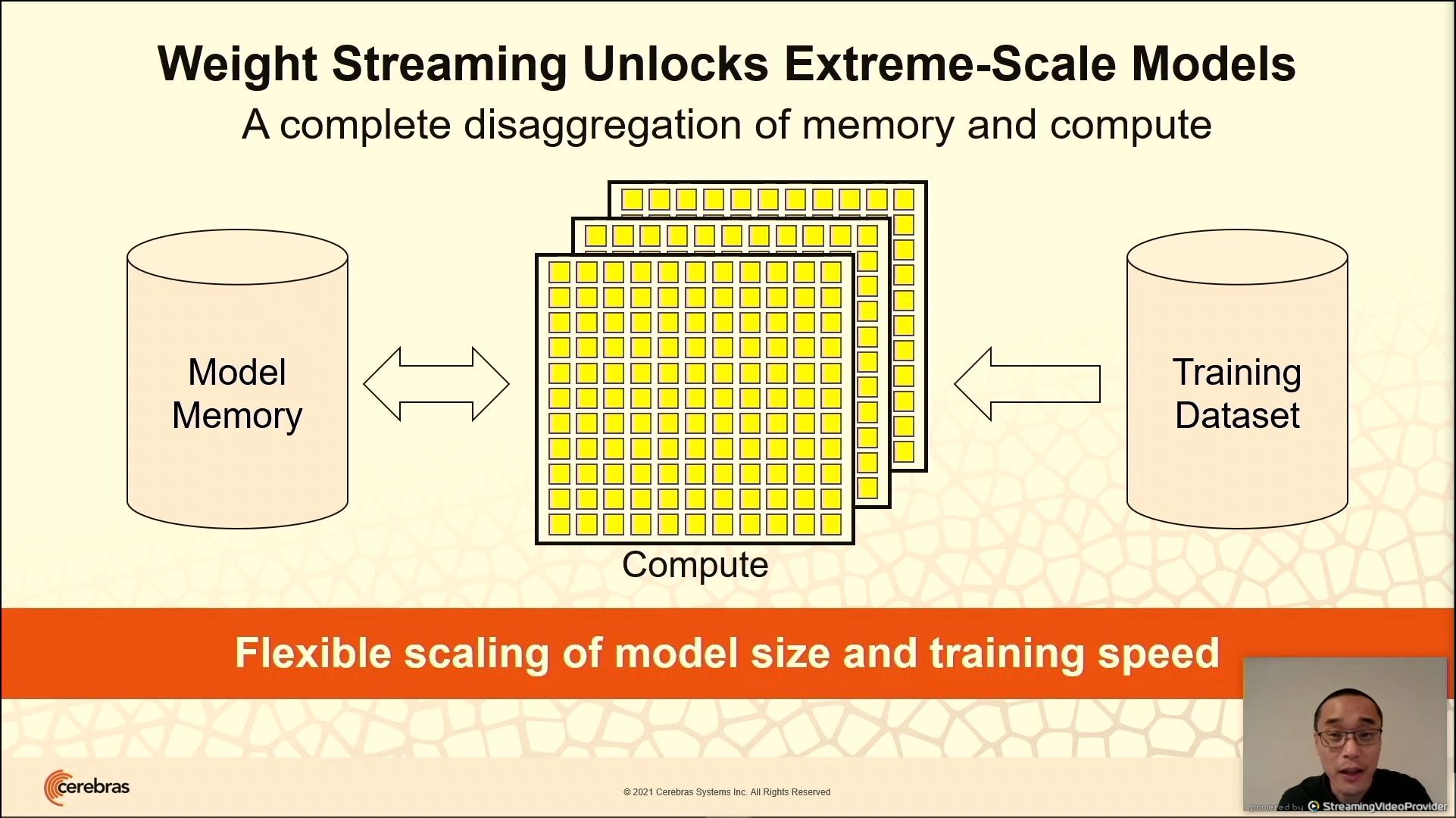
03:10PM EDT - Use weight streaming, rather than data streaming
03:11PM EDT - disaggregate model memory from compute from dataset
03:11PM EDT - can scale memory or compute as needed
03:12PM EDT - Base compute unit is a single CS-2, 850k cores, 14 kW, 1.6 TB/s bandwidth
03:12PM EDT - Add memory store to hold parameters, weights

03:12PM EDT - MemoryX Technology
03:12PM EDT - custom memory store for weights
03:12PM EDT - independent of that, SwarmX interconnect to control

03:13PM EDT - Designed to scale NN training with near linear scaling
03:13PM EDT - Simple execution flow with Cerebras software stack
03:13PM EDT - Program cluster same way as a single system

03:13PM EDT - 'Easy as Pie'
03:13PM EDT - Rethink the execution model
03:14PM EDT - All model weights stored externally, streamed onto the CS2 system as needed
03:14PM EDT - As they stream through, the CS-2 performs the calculation
03:14PM EDT - backward pass, gradients are streamed. Weight update occurs on MemoryX, but swarmX can help
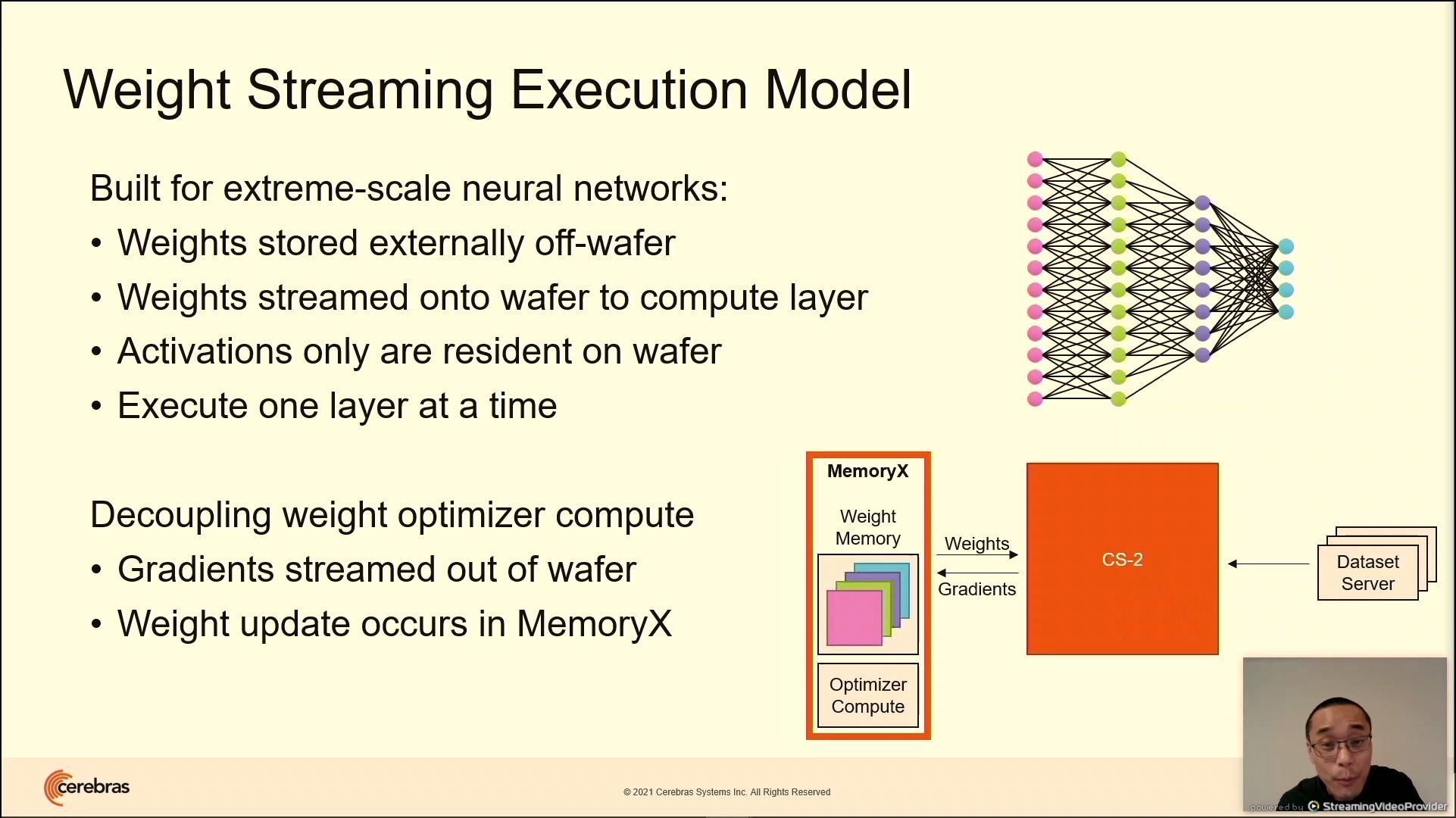
03:16PM EDT - Solving the latency problem
03:16PM EDT - weight streaming has no back-to-back dependencies
03:16PM EDT - ensure weight memory is not latency sensitive
03:16PM EDT - coarse grained pipeline - a pipeline of layers
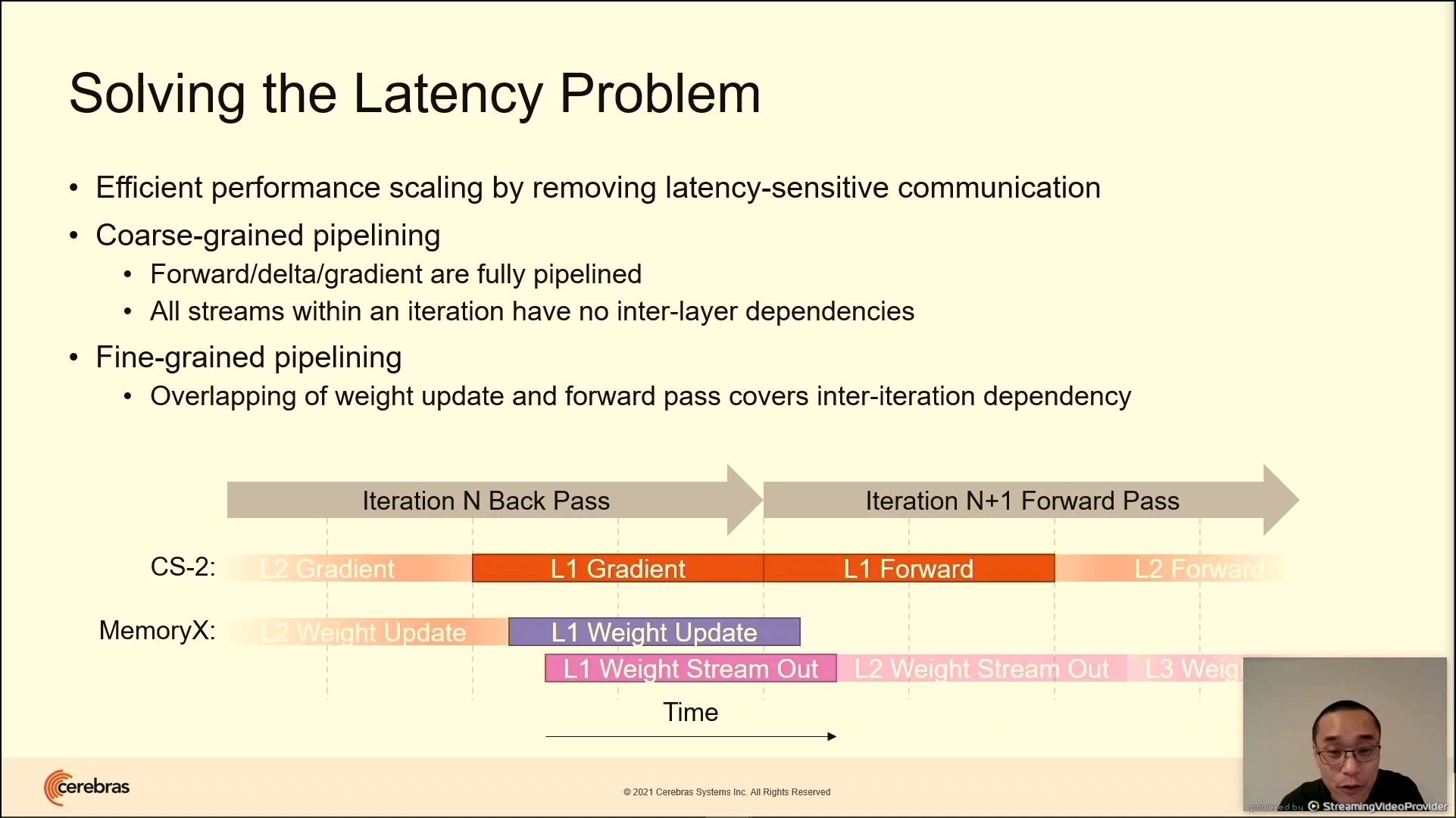
03:17PM EDT - Stream out weights as the next stream comes in
03:17PM EDT - hide the extra latency from extra weights
03:17PM EDT - same performance as if weights were local
03:17PM EDT - now capacity
03:18PM EDT - two main capacity problems
03:18PM EDT - store the giant model

03:18PM EDT - All parameters in MemoryX up to 2.4 PB capacity
03:18PM EDT - 120 trillion weights. DRAM and flash hybrid storage
03:18PM EDT - Internal compute for weight update/optimizer
03:19PM EDT - MemoryX does the intelligent pipeline scaling
03:19PM EDT - Flexible capacity with MemoryX
03:20PM EDT - No need for partitioning with WSE2
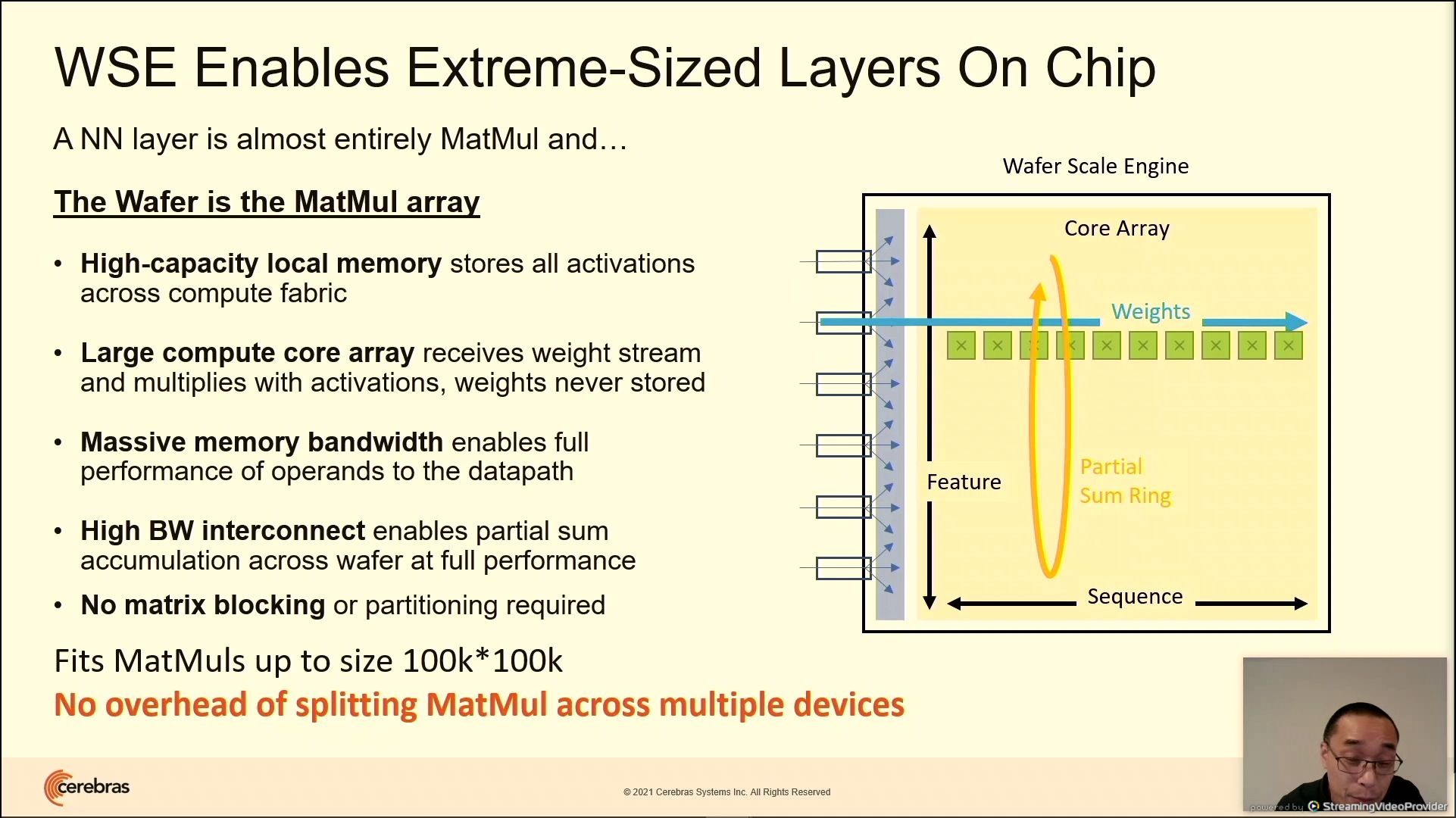
03:21PM EDT - Support for 100kx100k MatMuls
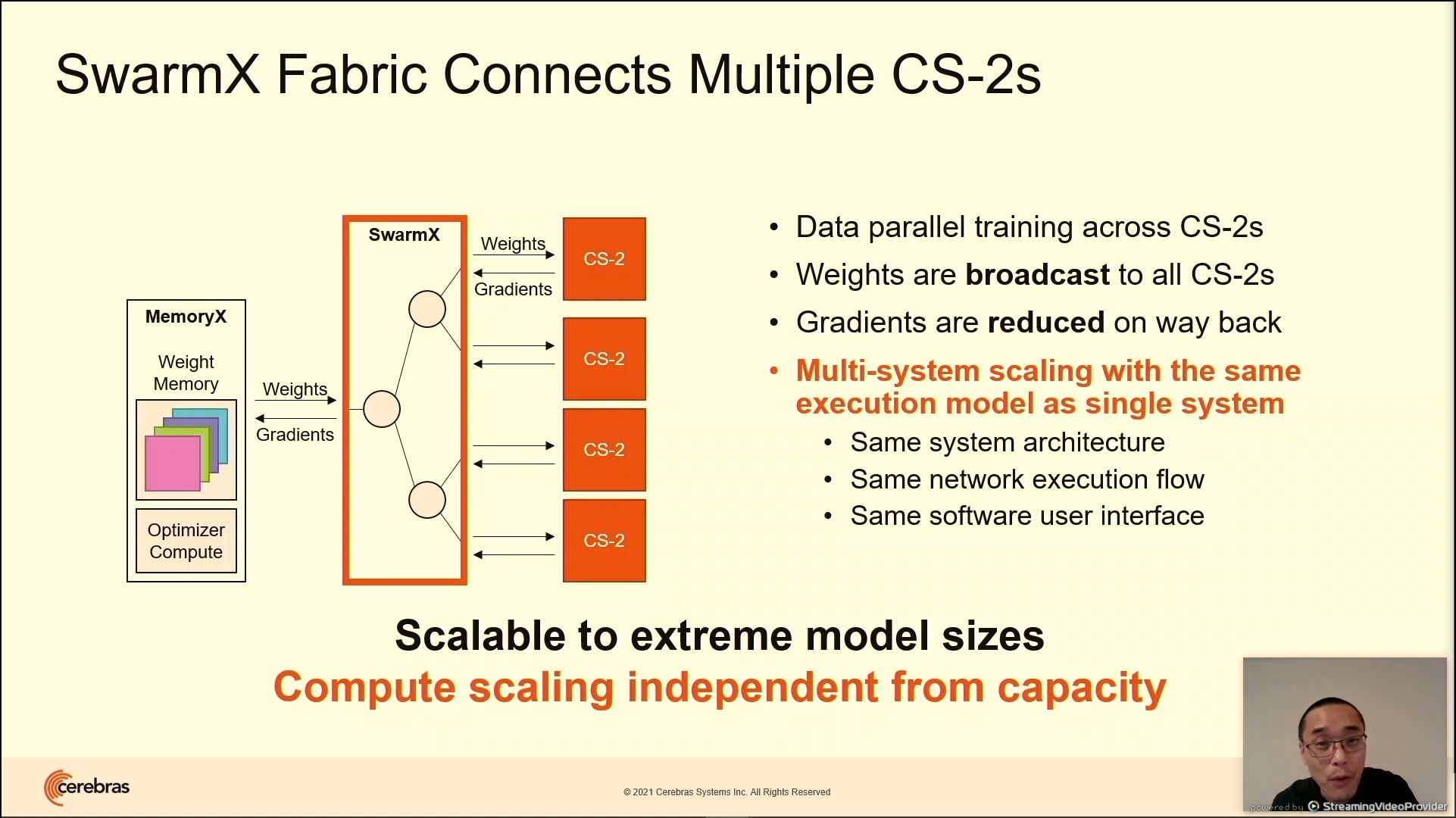
03:22PM EDT - Cluster multiple CS-2 through SwarmX
03:22PM EDT - SwarmX is imdenpdent of CS-2 and MemoryX
03:23PM EDT - Gradients are reduced on the way back, weights are broadcast on the way forward
03:23PM EDT - modular and disaggregated
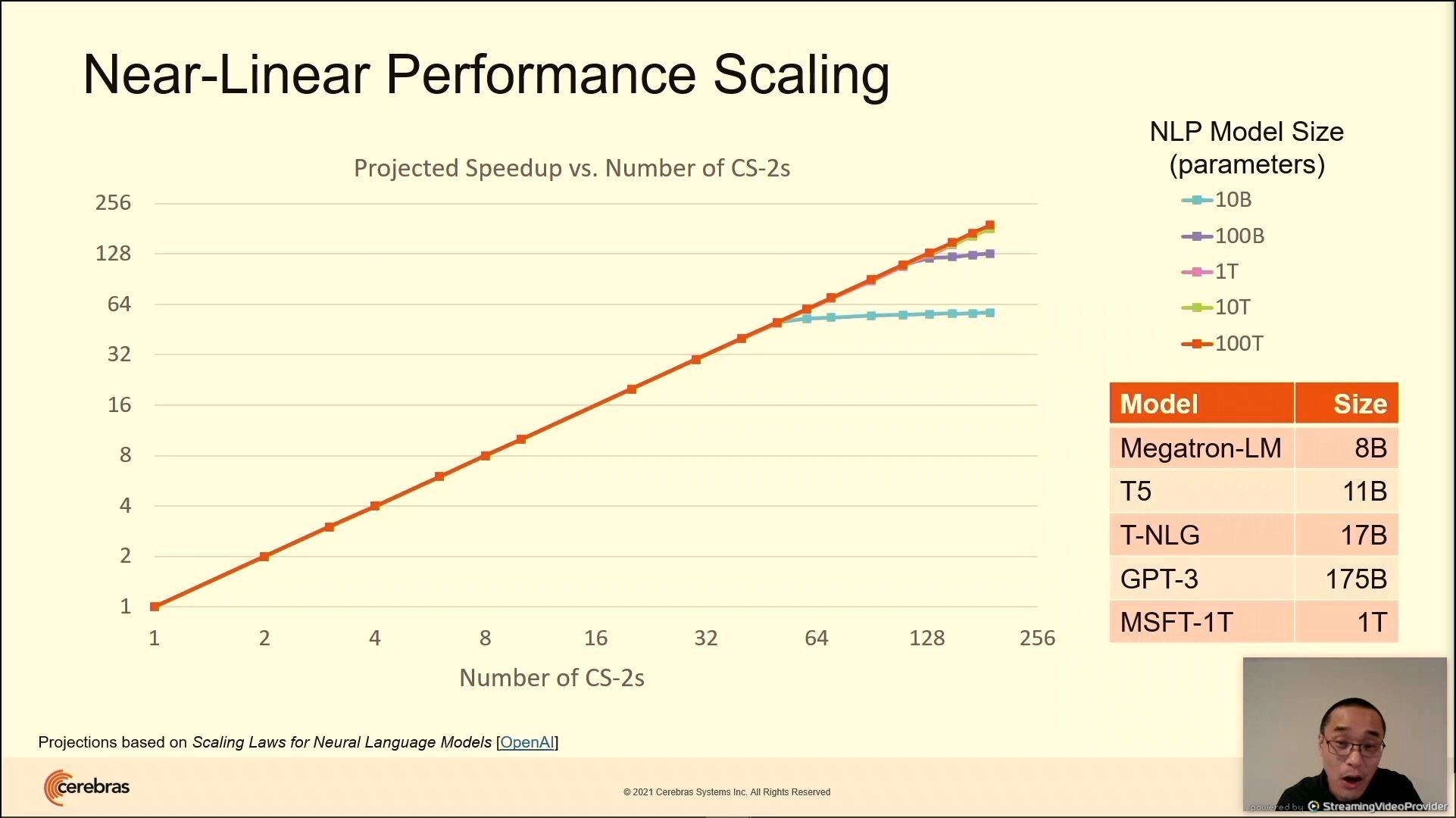
03:23PM EDT - Project near-linear to 192 CS-2 systems
03:25PM EDT - 'Is this enough?' No, need smarter models
03:25PM EDT - Outpacing moore's law by an order of magnitude
03:25PM EDT - Will need a football field of silicon to run a model
03:25PM EDT - Need sparse models to get same answers with less compute

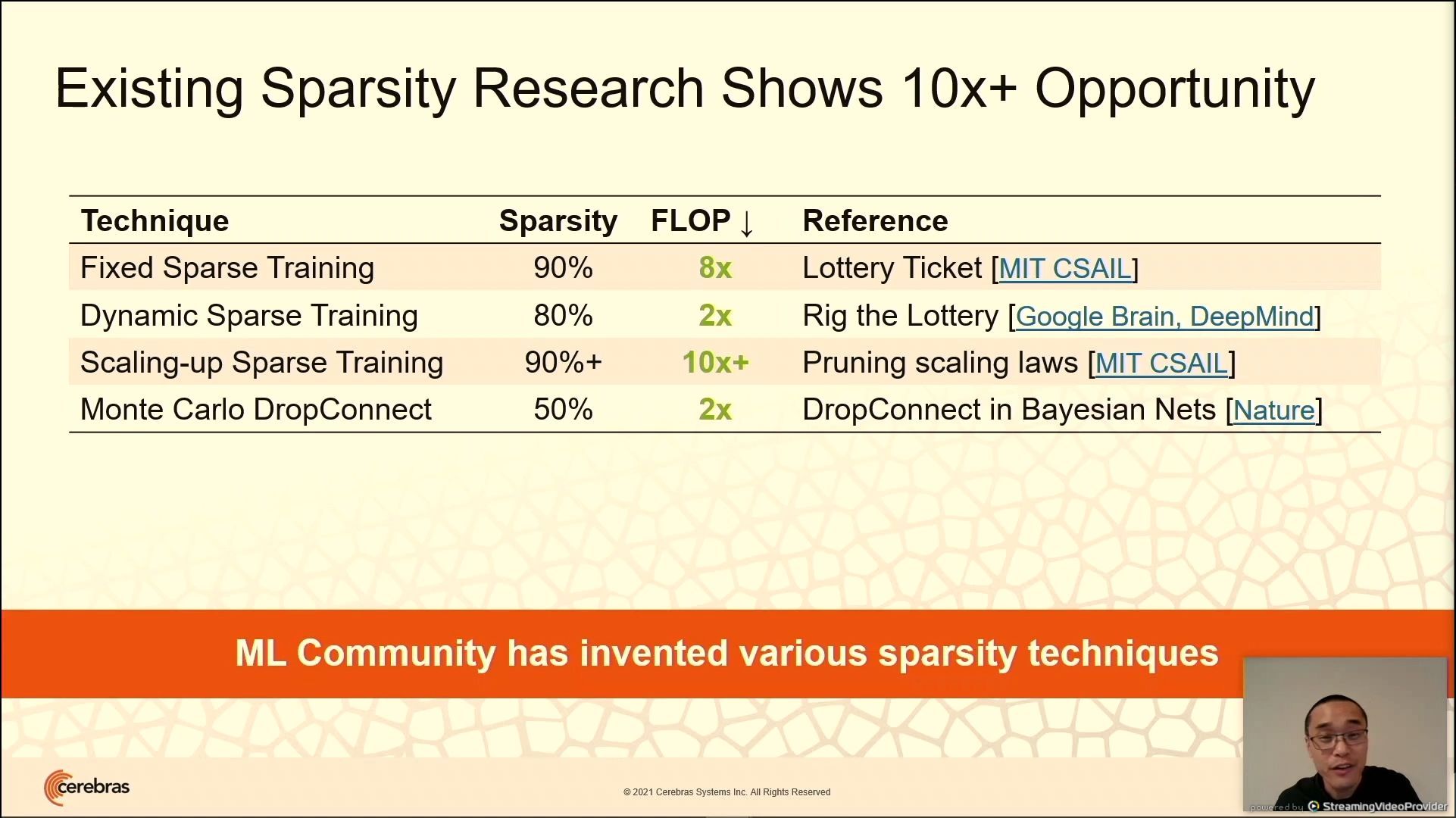
03:25PM EDT - Creating sparsity in dense models
03:26PM EDT - No hardware to solve for this sparsity, except Cerebras
03:26PM EDT - Hardware data control for non-zero data compute
03:26PM EDT - accelerates all types of sparsity
03:26PM EDT - Full performance across all BLAS levels

03:28PM EDT - Sparsity is introduced in the MemoryX unit. Sparse weights are streamed, SwarmX broadcasts to CS-2. CS-2 does compute. Sparse gradients produced,. gradients are streamed back out, reduced through SwarmX, updated on MemoryX .All happens natively, same flow as for dense compute
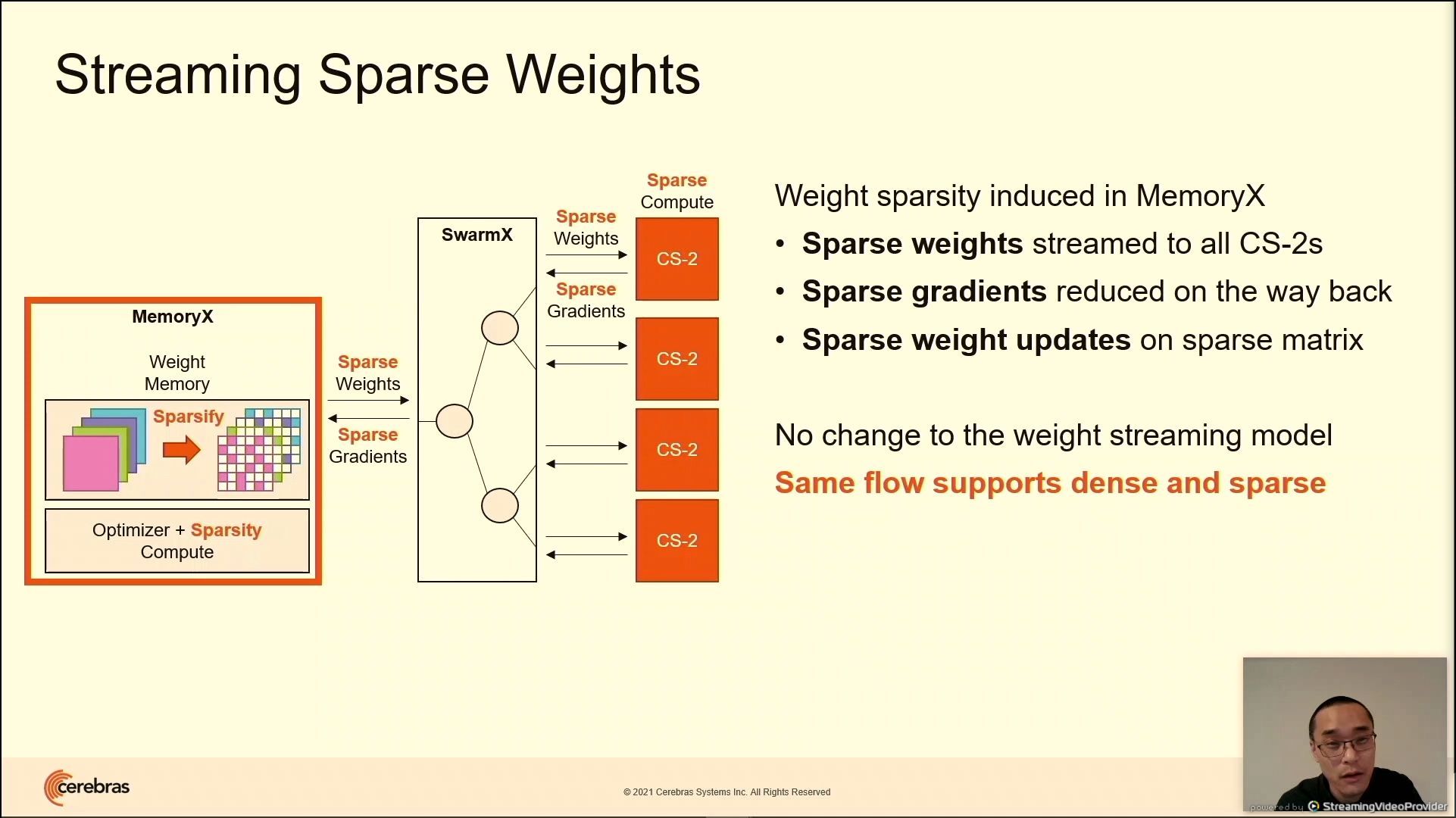

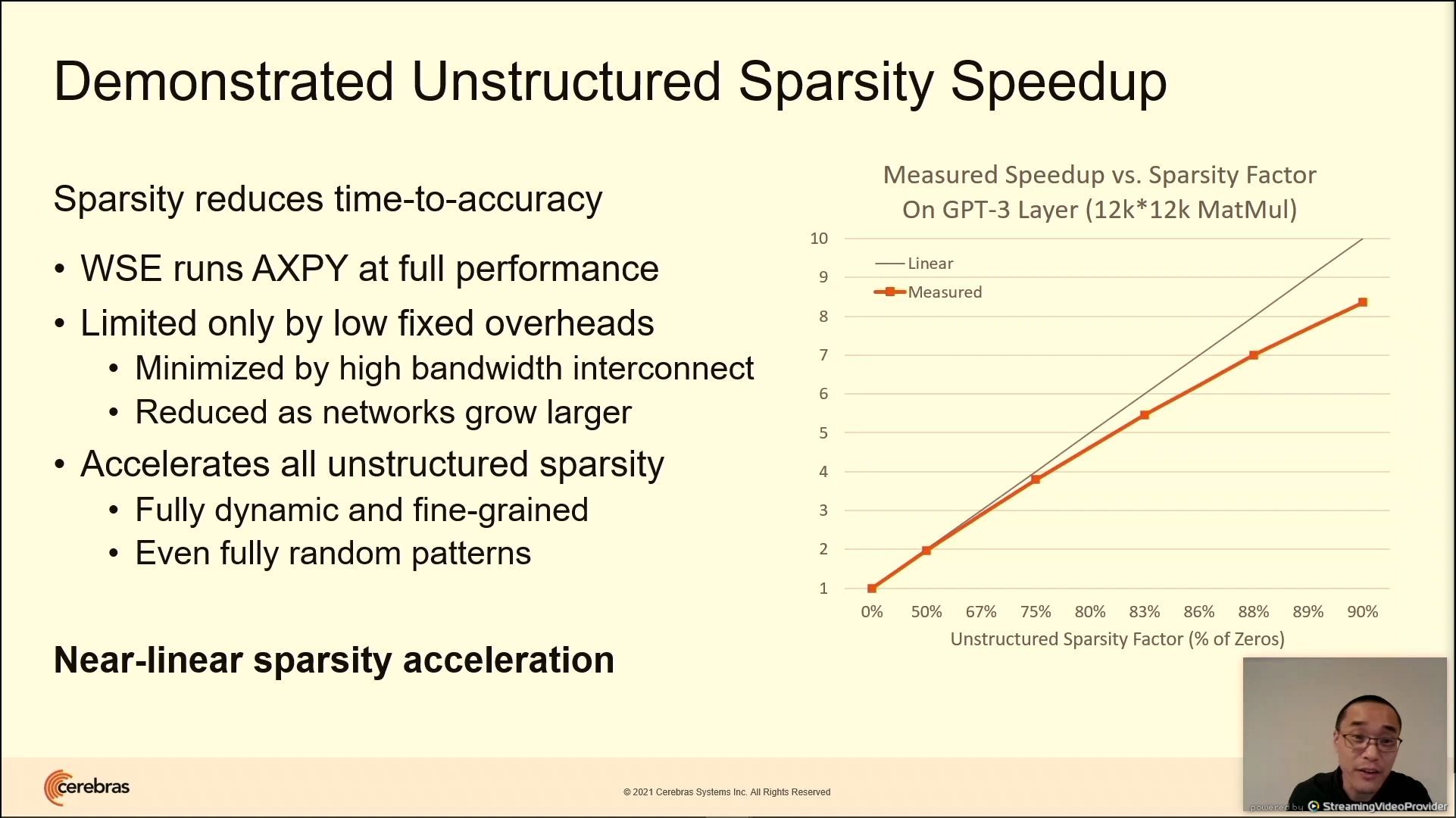
03:29PM EDT - near linear speedup with sparsity

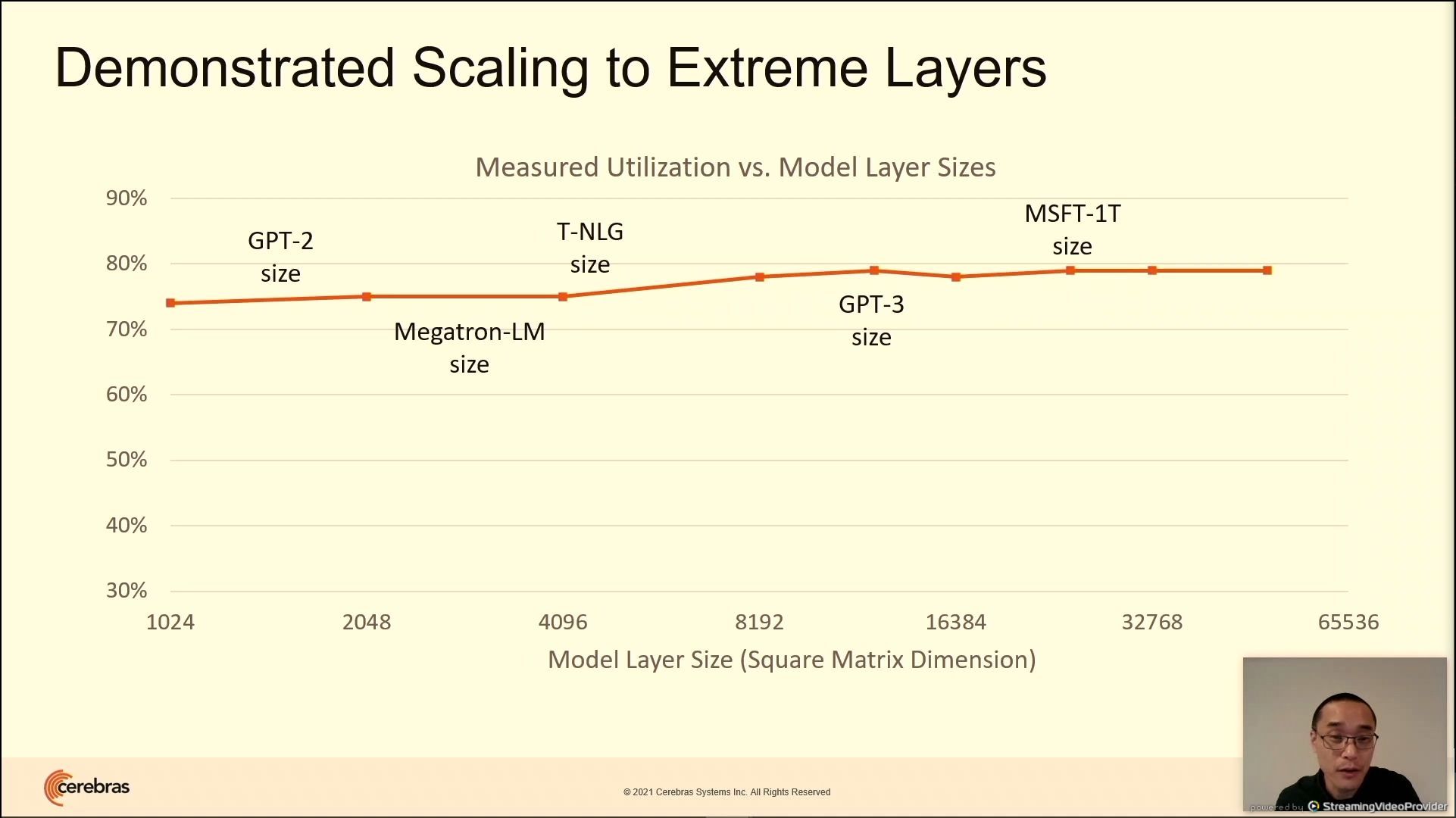
03:31PM EDT - enormous layer support for up to 100k hidden dimensions
03:32PM EDT - Don't need different software to go from 1 device to 192 - execution model is always the same

03:34PM EDT - Q&A
03:35PM EDT - Q: Bandwidth MemoryX to CS-2 A: MemoryX doesn't have to be in the same rack, can be cabled. BW is over 1 Tbit - not just through MemX but also SwarmX
03:35PM EDT - Q: Interconnect is custom? A: Standard, but not disclosing, but not directly exposed to the user. Intended to be integrated into the system and seemless from user point of view
03:36PM EDT - Q: Handle activations for skip connections - A - all activations are kept on wafer. Get picked up in a few layers when needed
03:36PM EDT - Next talk is SambaNova

03:39PM EDT - Cardinal SN10 RDU
03:39PM EDT - TSMC N7, 40B transistors
03:39PM EDT - BF16 focused AI chips for training

03:40PM EDT - base unit of compute is a 12 TB memory system in a quarter rack with 8 SN10 chips
03:40PM EDT - standard rack form factor
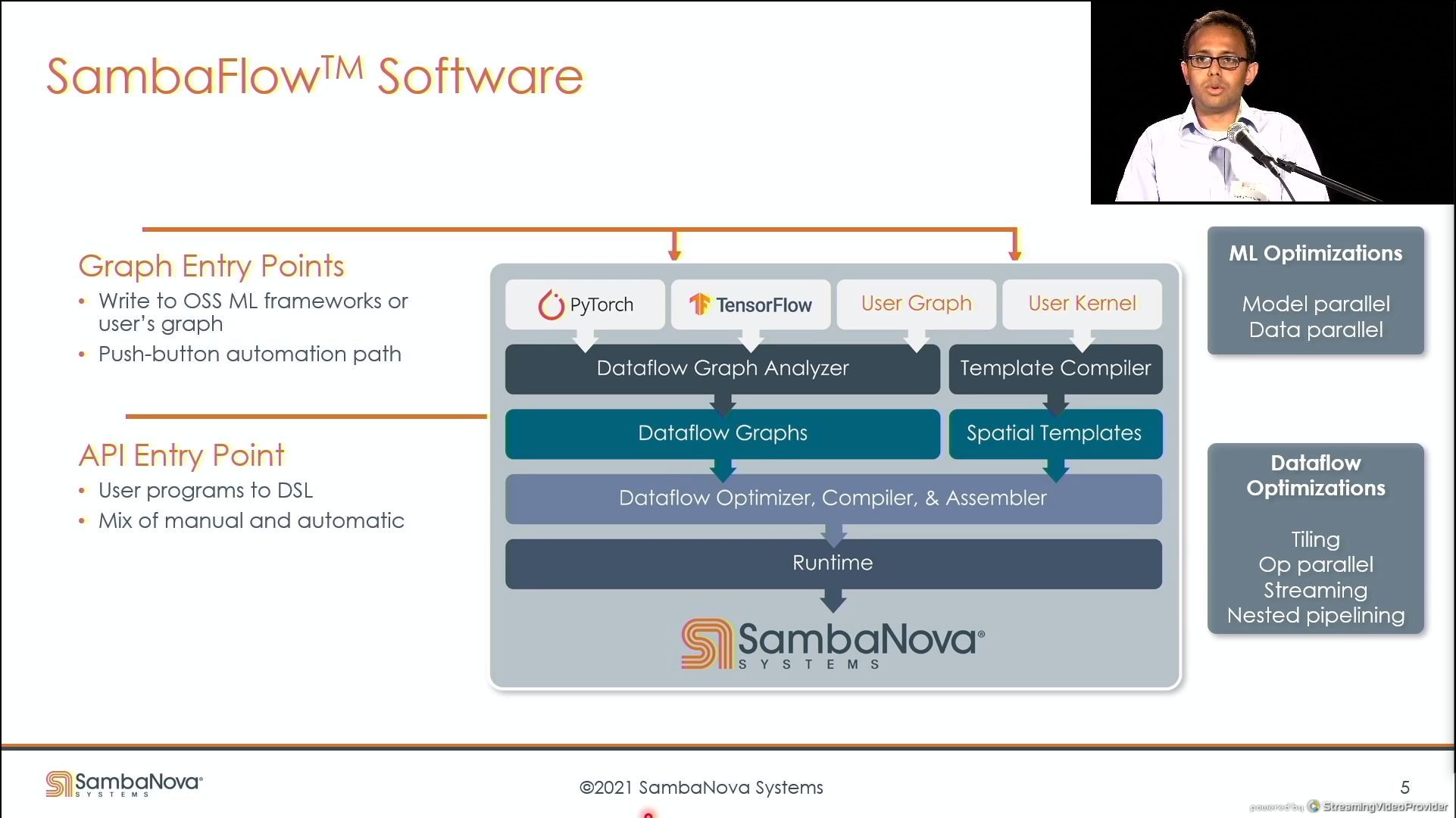
03:40PM EDT - pyTorch, Tensorflow, UserGraph, or User Kernel
03:41PM EDT - Dataflow pipe is SambaNova software stack


03:42PM EDT - graphs are rewriting the way we think about software
03:43PM EDT - current systems not suited for dataflow - goldilocks zone
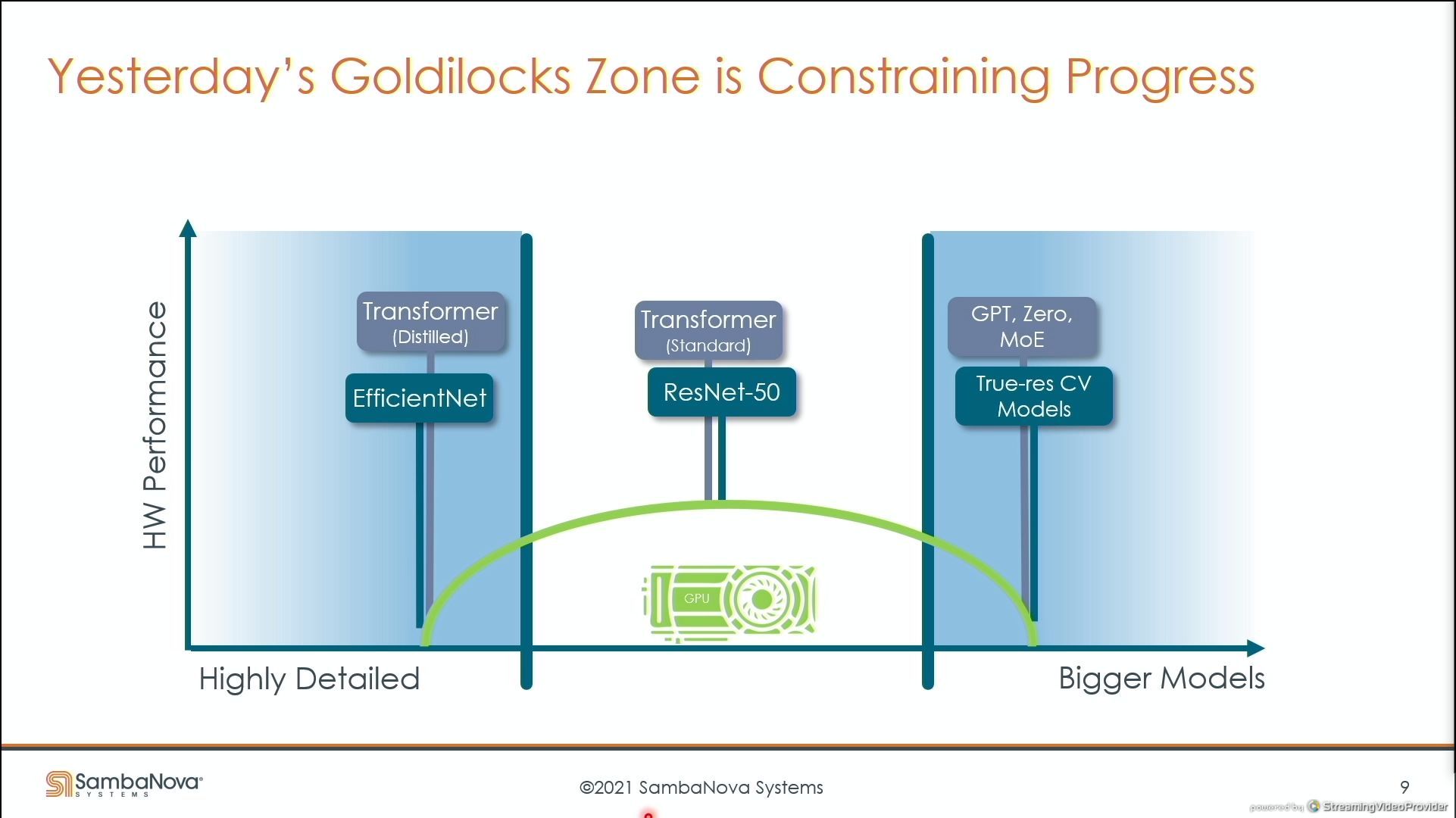
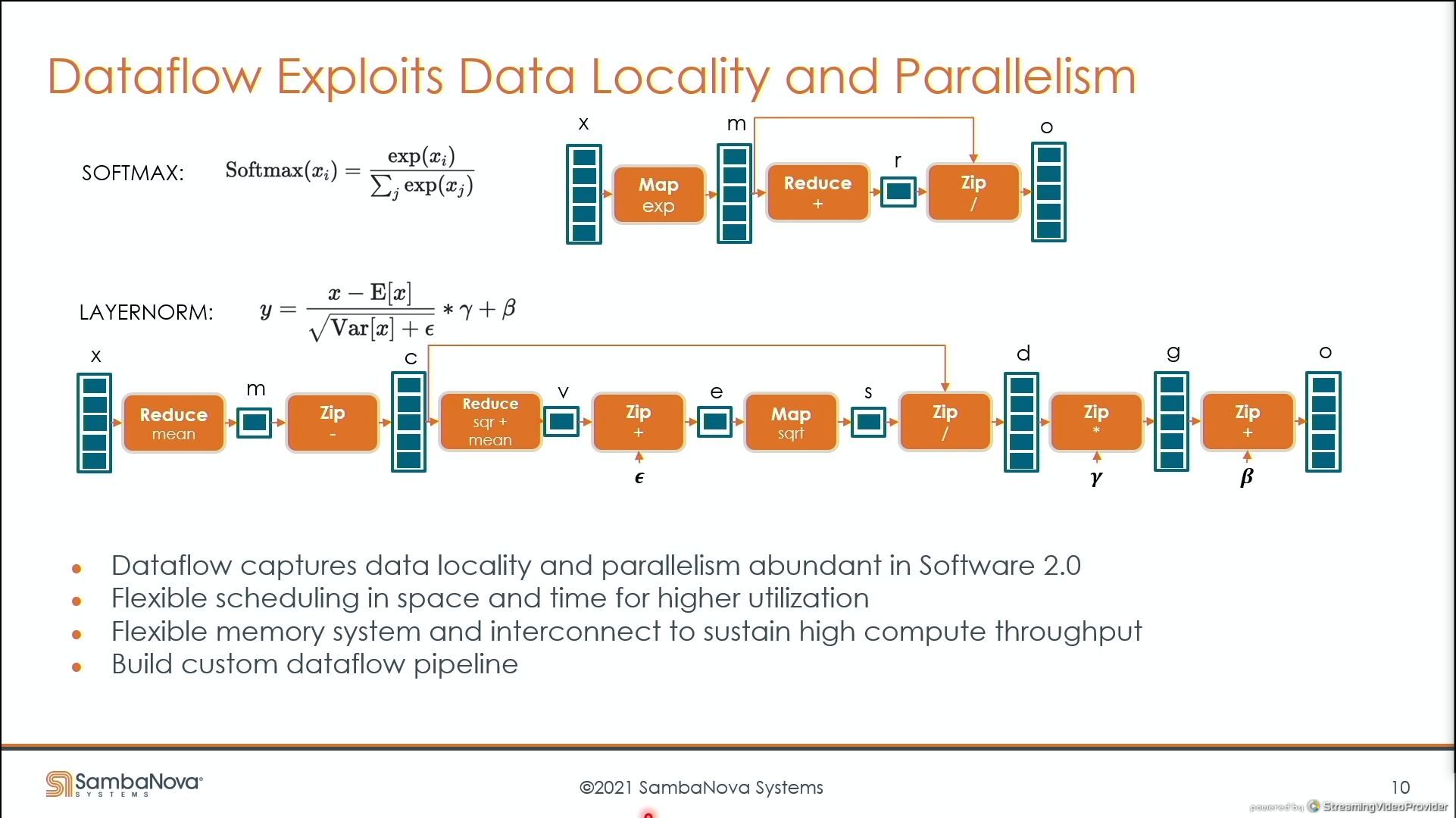
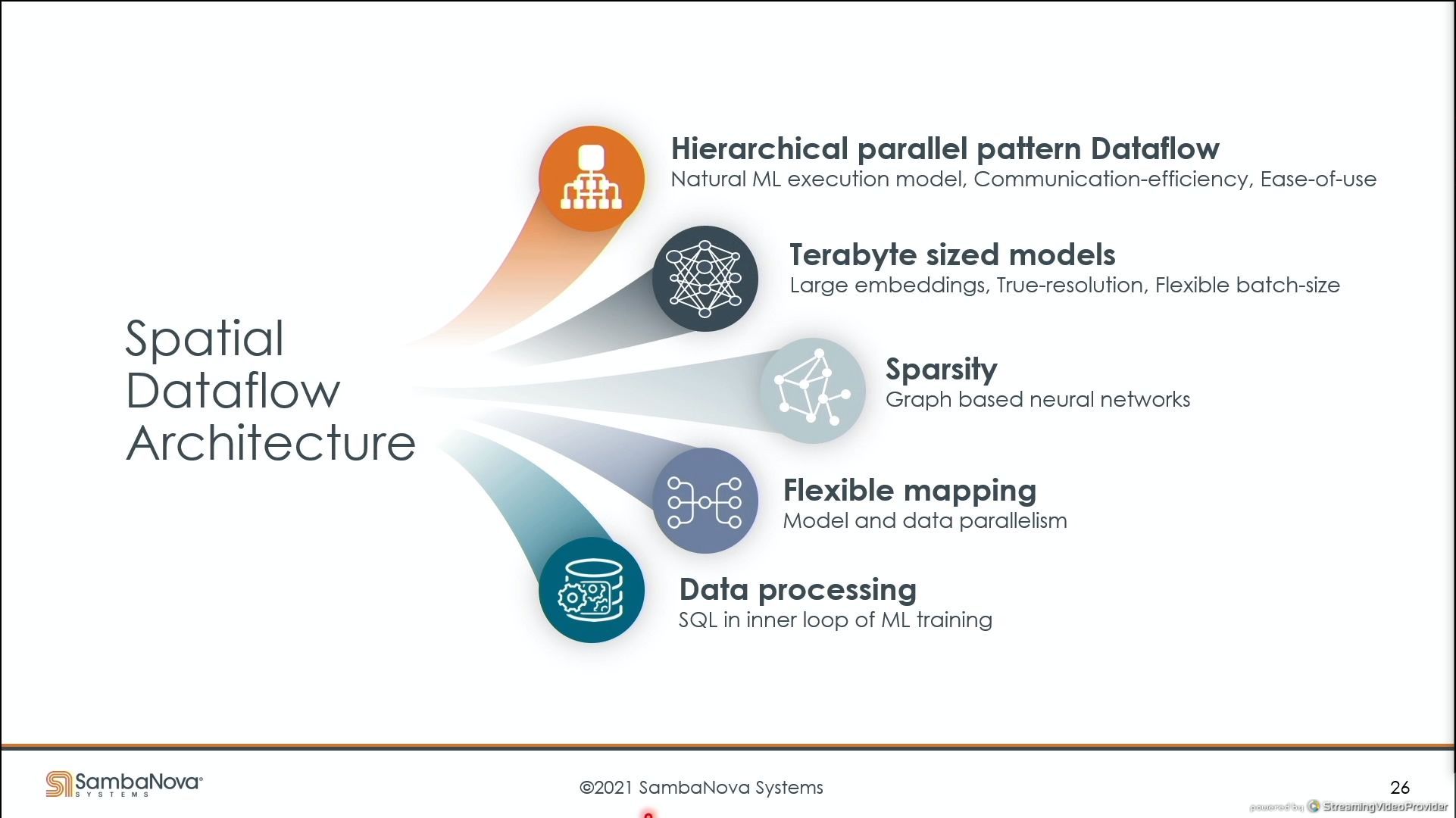
03:43PM EDT - using dataflow to the max
03:44PM EDT - orange boxes here is compute

03:44PM EDT - high-level architecture
03:45PM EDT - four tiles of reconfigurable compute and memory
03:45PM EDT - resources can be managed or combined
03:45PM EDT - Direct access to TBs of DDR4 off-chip memory
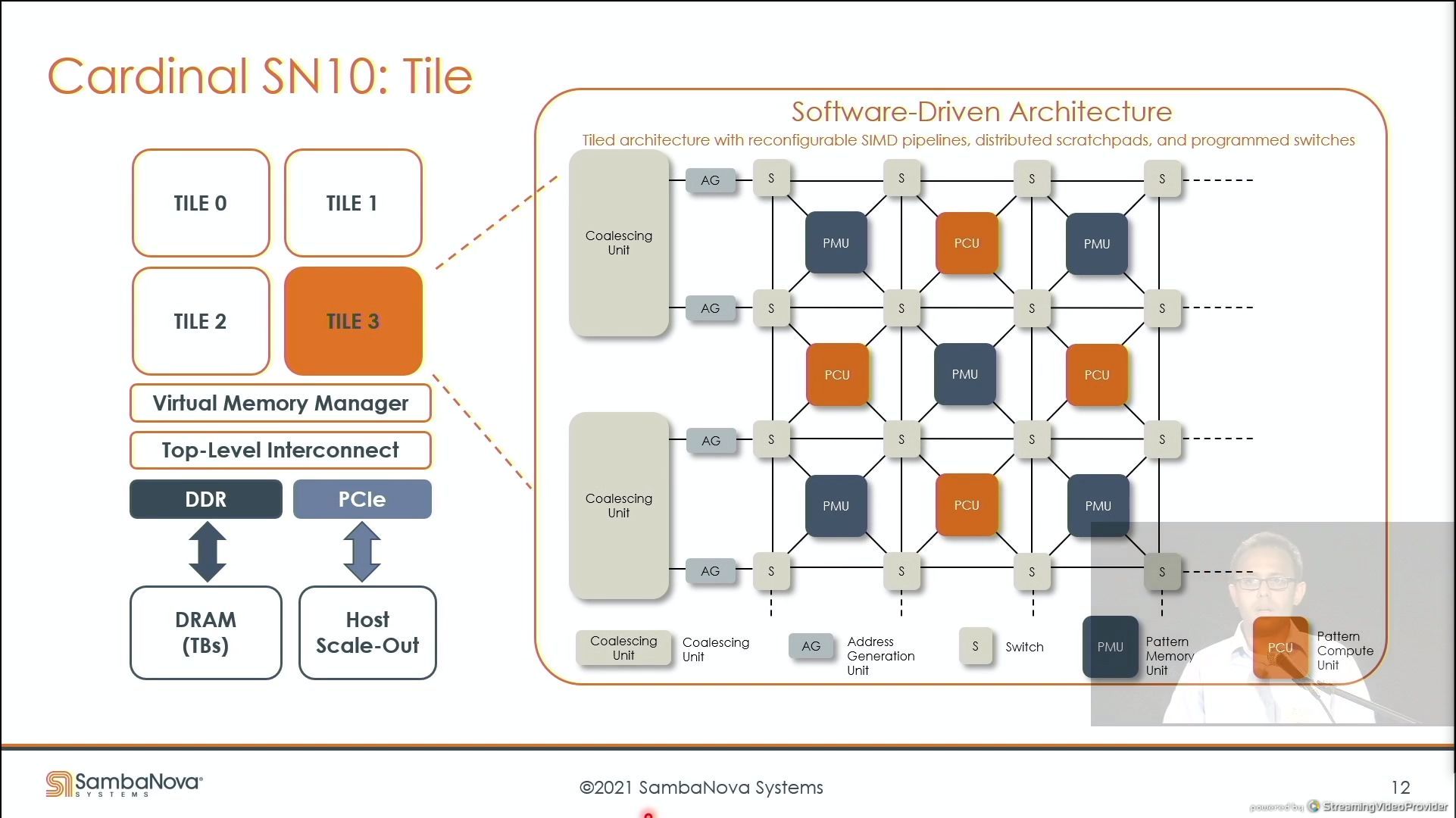
03:45PM EDT - Pattern Memory Units, Pattern Compute Units, Switches
03:46PM EDT - AGUs are before compute and memory
03:46PM EDT - architecture allows for scale out
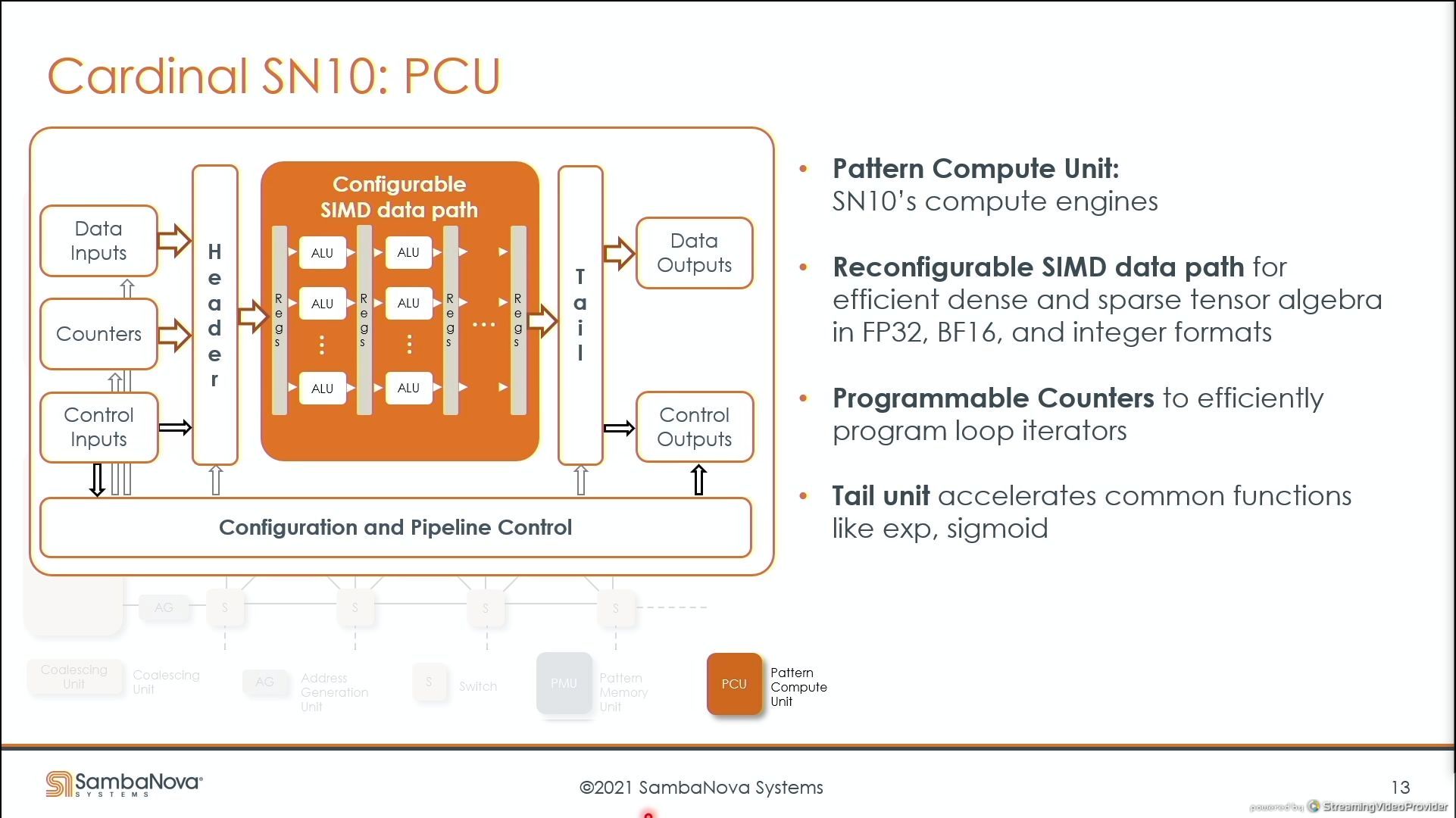
03:46PM EDT - supports systolic modes of execution
03:47PM EDT - Feed the PCUs
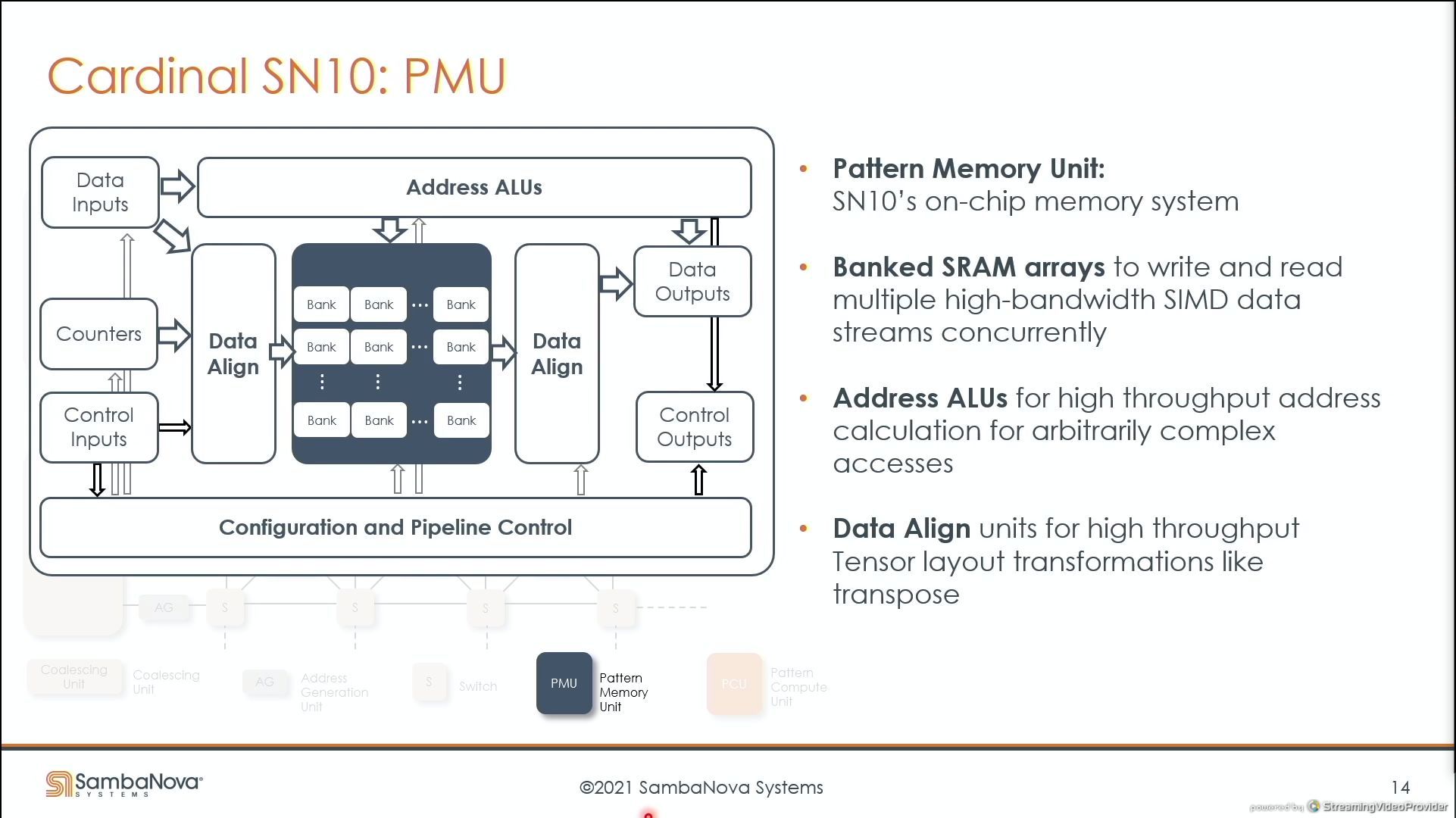
03:47PM EDT - support arbitrary memory access patterns
03:47PM EDT - Data align units
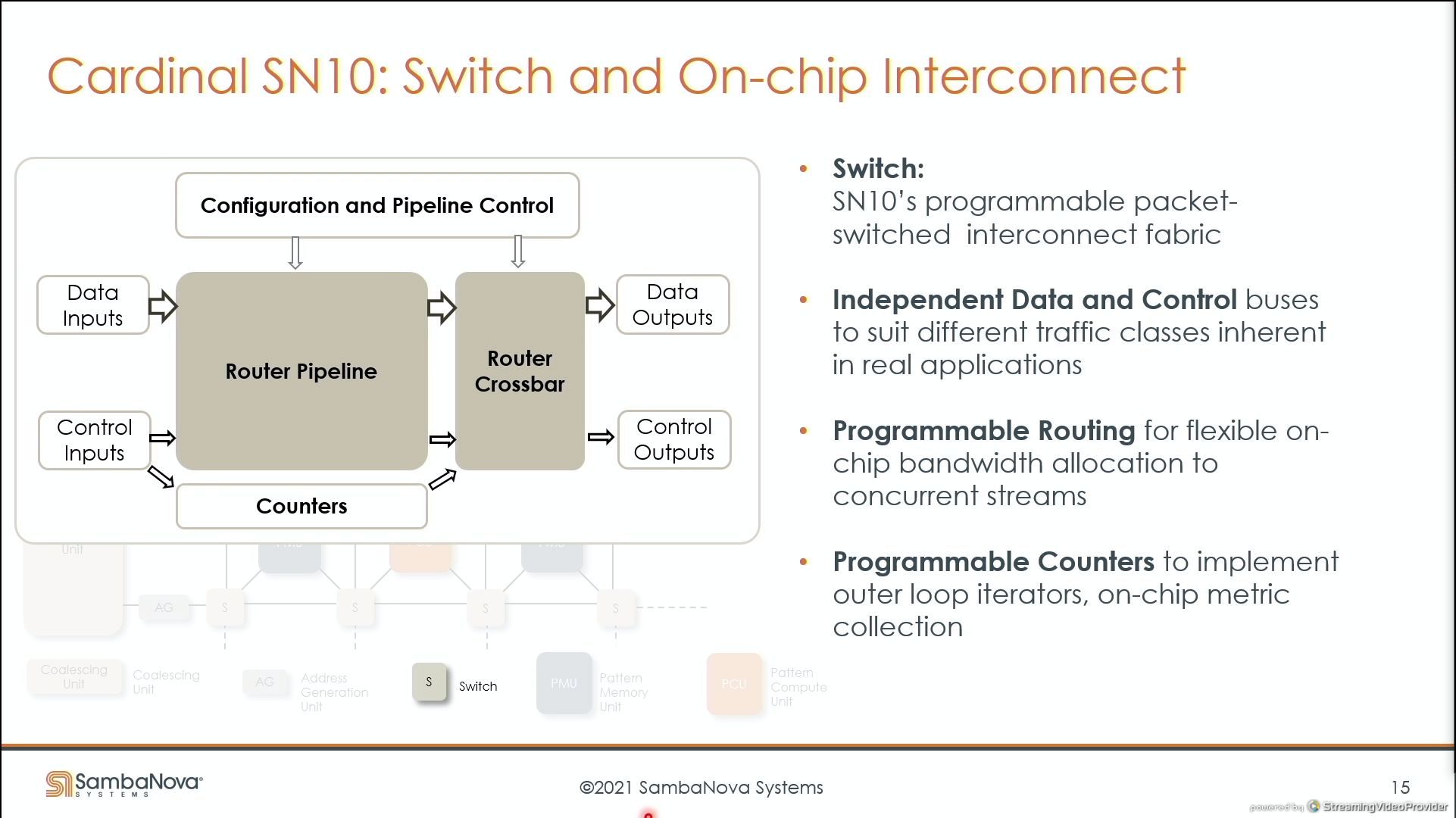
03:48PM EDT - Router is not just nearest neighbor - compiler can construct arbitrary routes
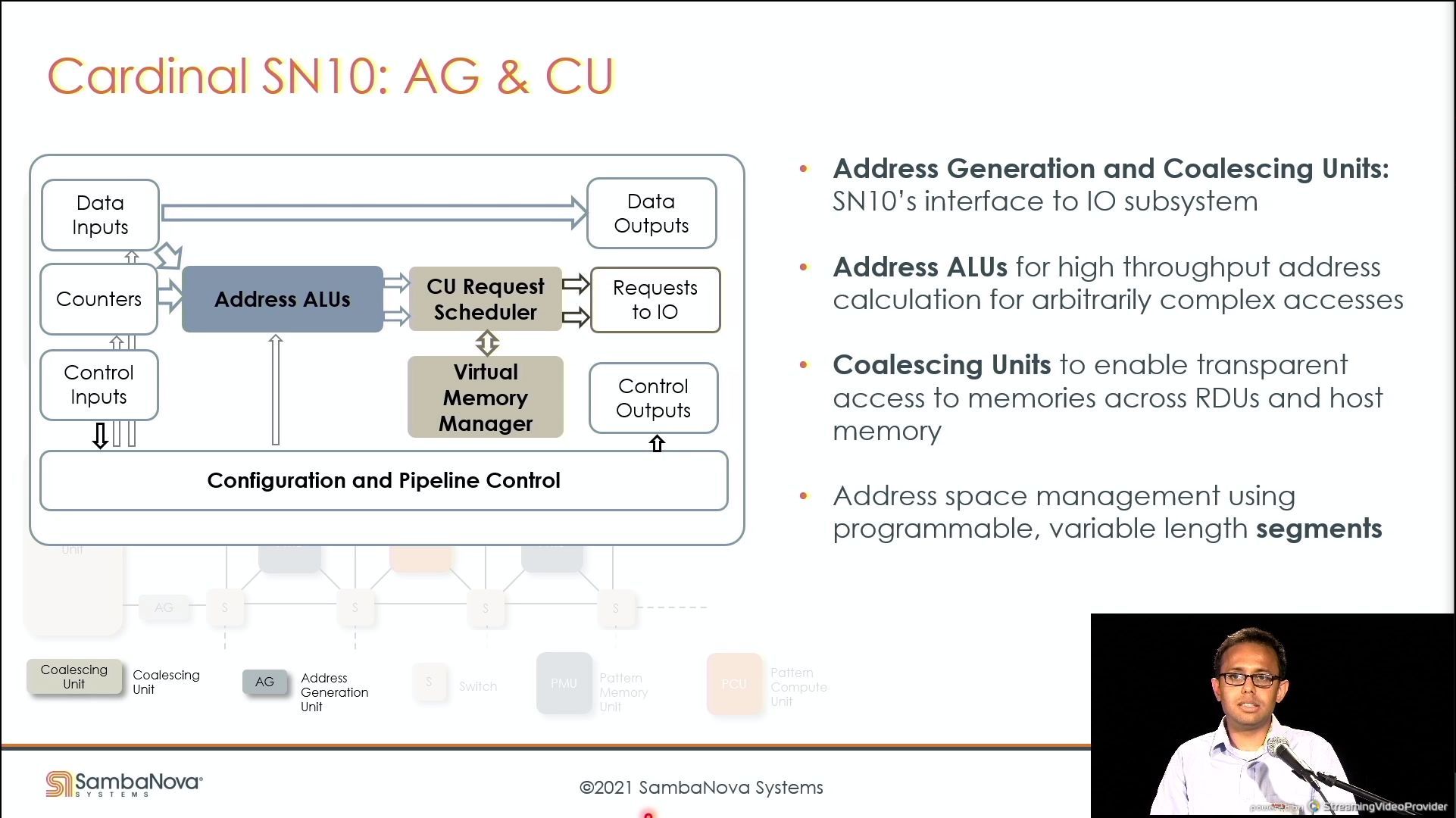
03:48PM EDT - Allows for transfer and transparent scaleout
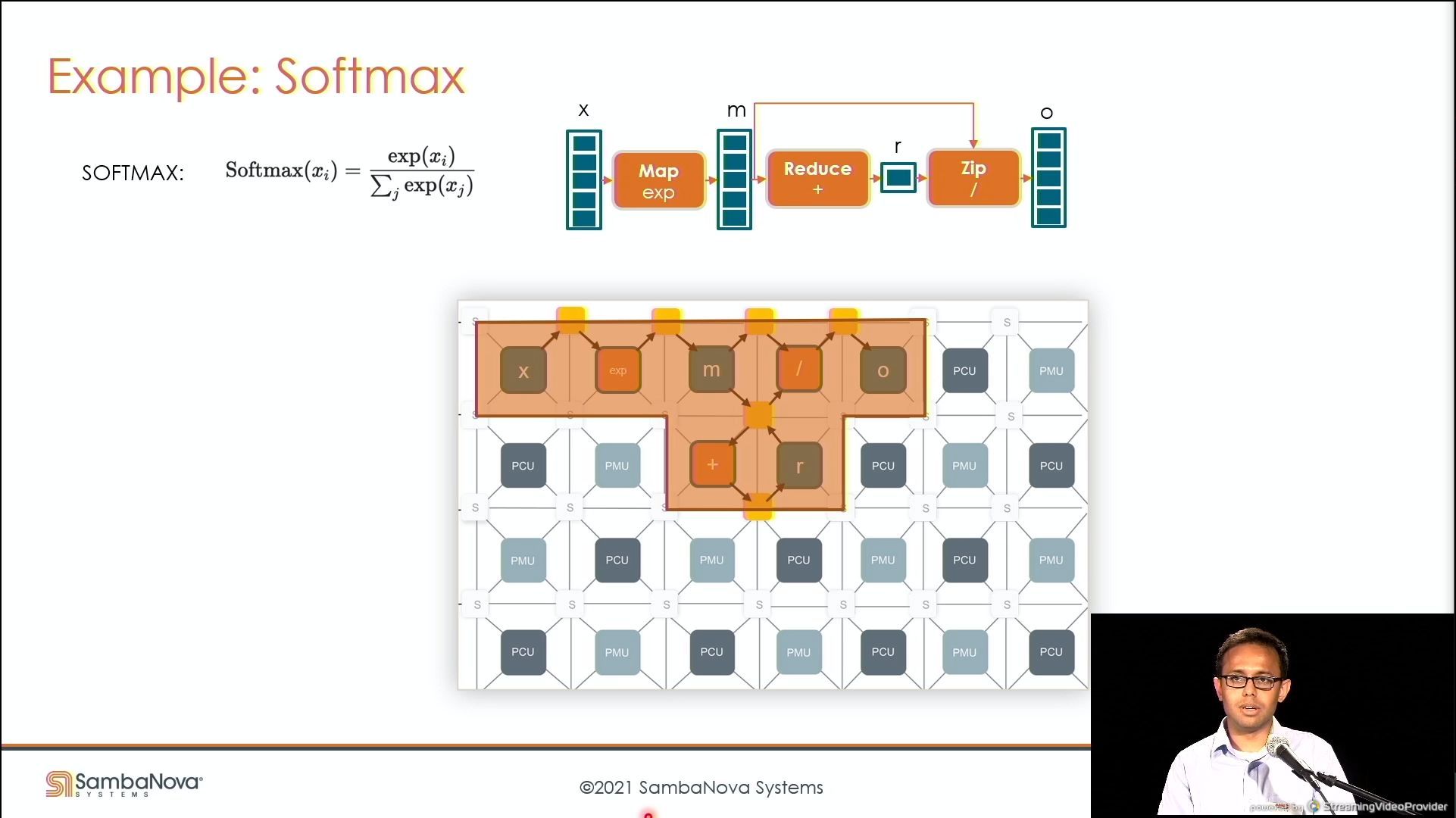
03:49PM EDT - Here's how to map an operation
03:49PM EDT - and communications
03:49PM EDT - Fully pipelined softmax operation
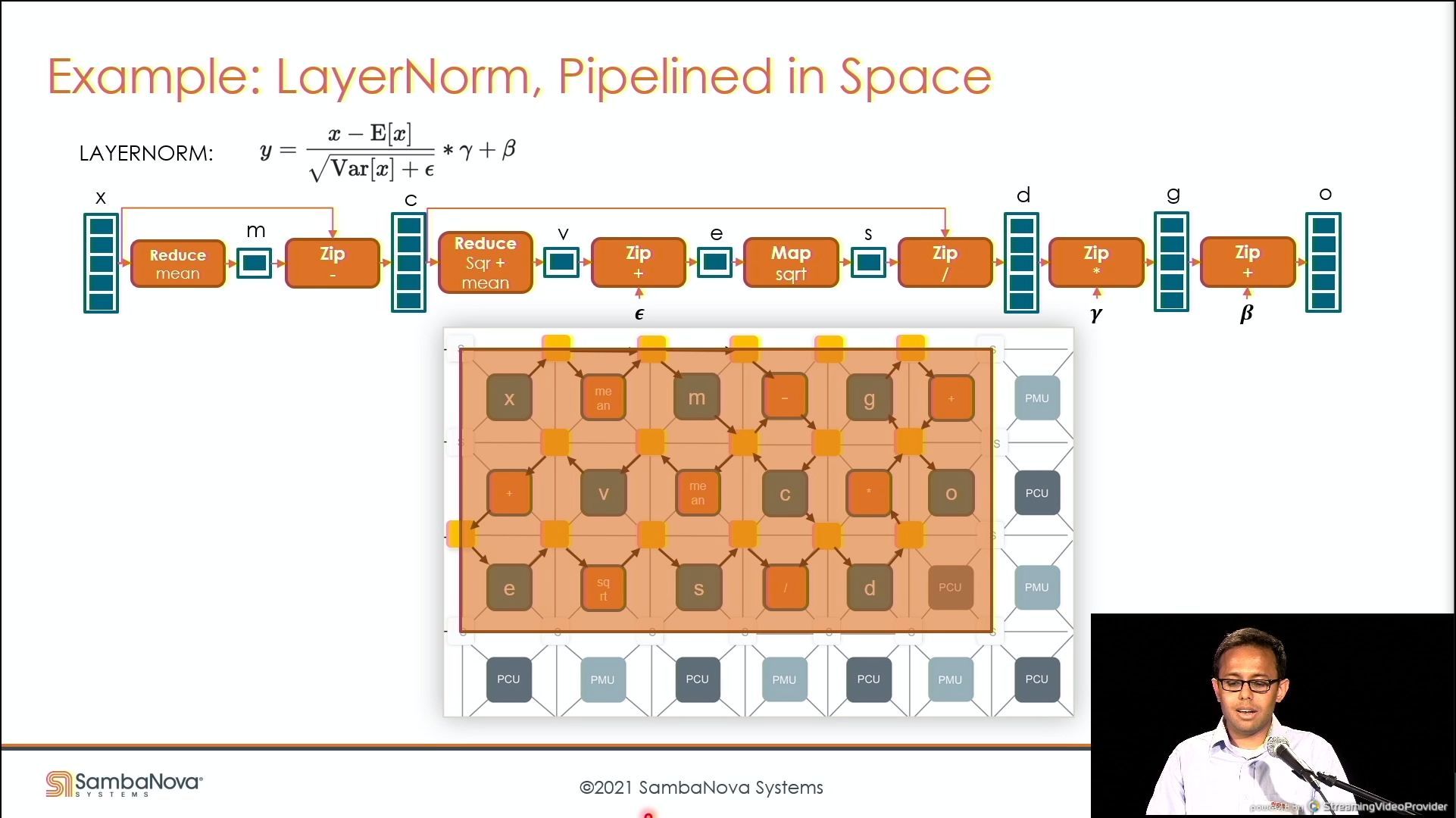
03:49PM EDT - Here's something more complex - the LayerNorm
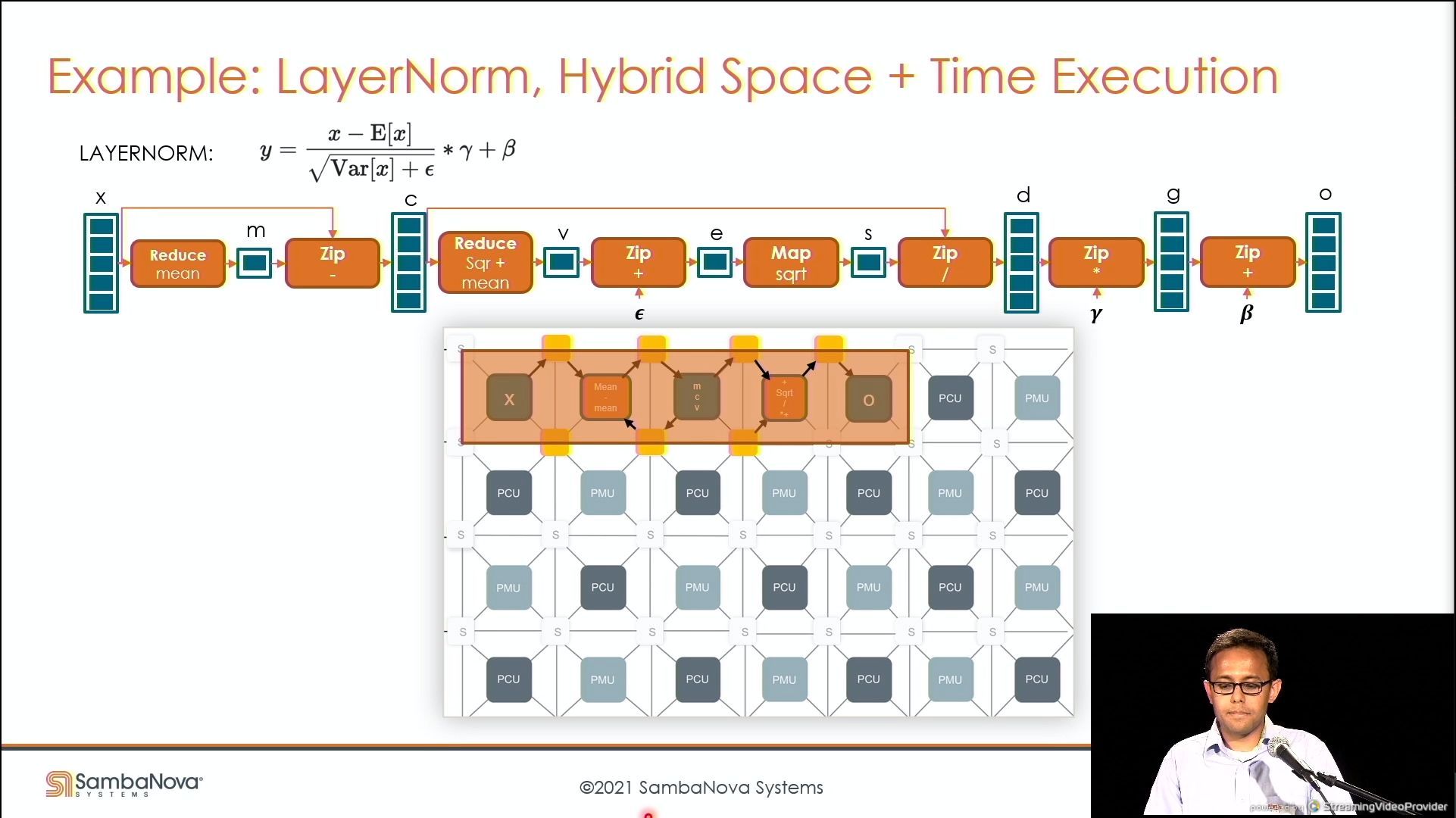
03:50PM EDT - Can also repurpose for tradeoff space/time
03:50PM EDT - Compiler takes advantage
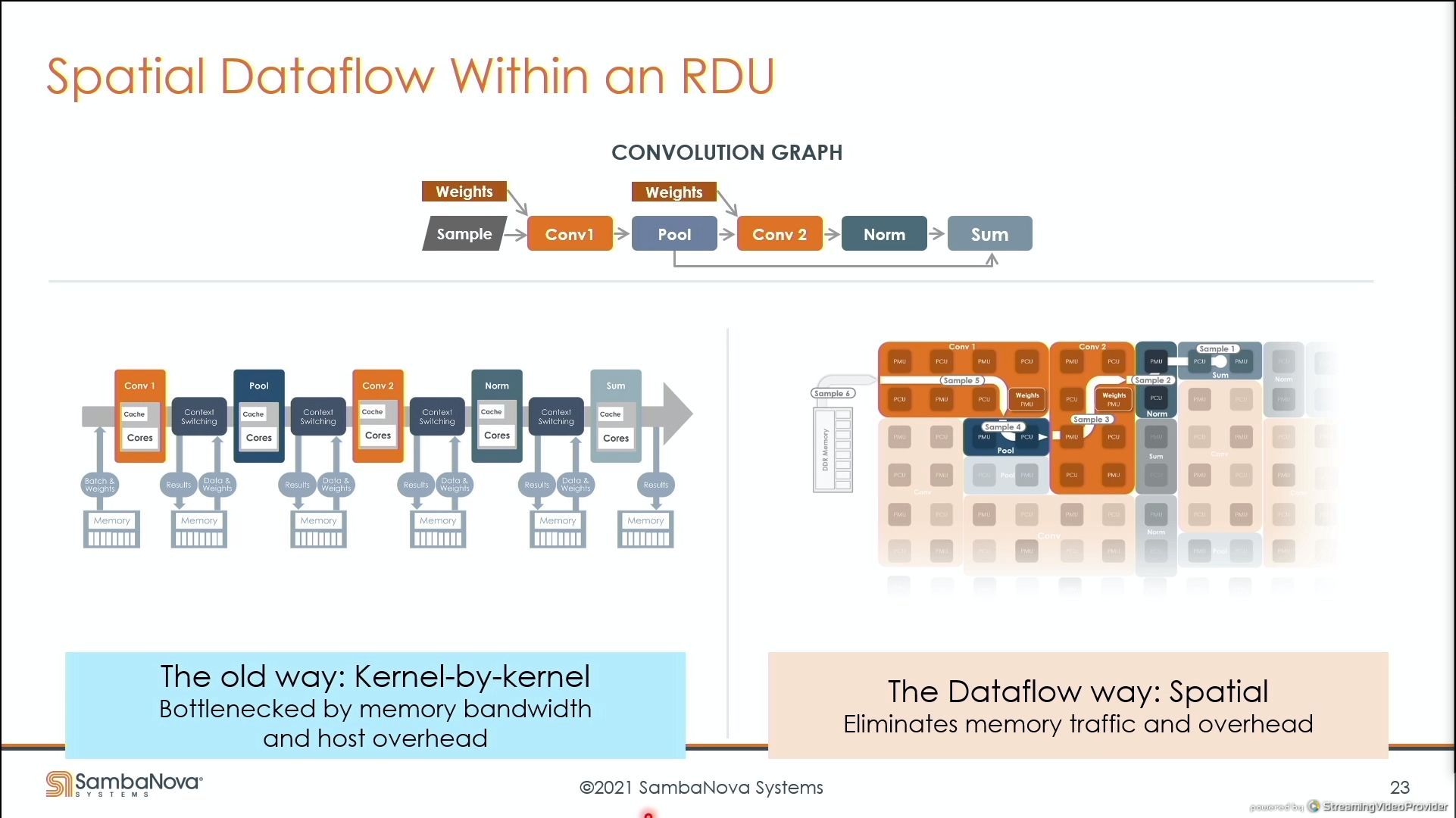
03:51PM EDT - Kernel by Kernel in spatial
03:51PM EDT - Automatic kernel fusion - no need to manually hand fuse operations
03:52PM EDT - Use IO bandwidth more efficiently
03:52PM EDT - High performance high utilization

03:53PM EDT - Compiler can group sparse and dense multiplies to be executed on chip
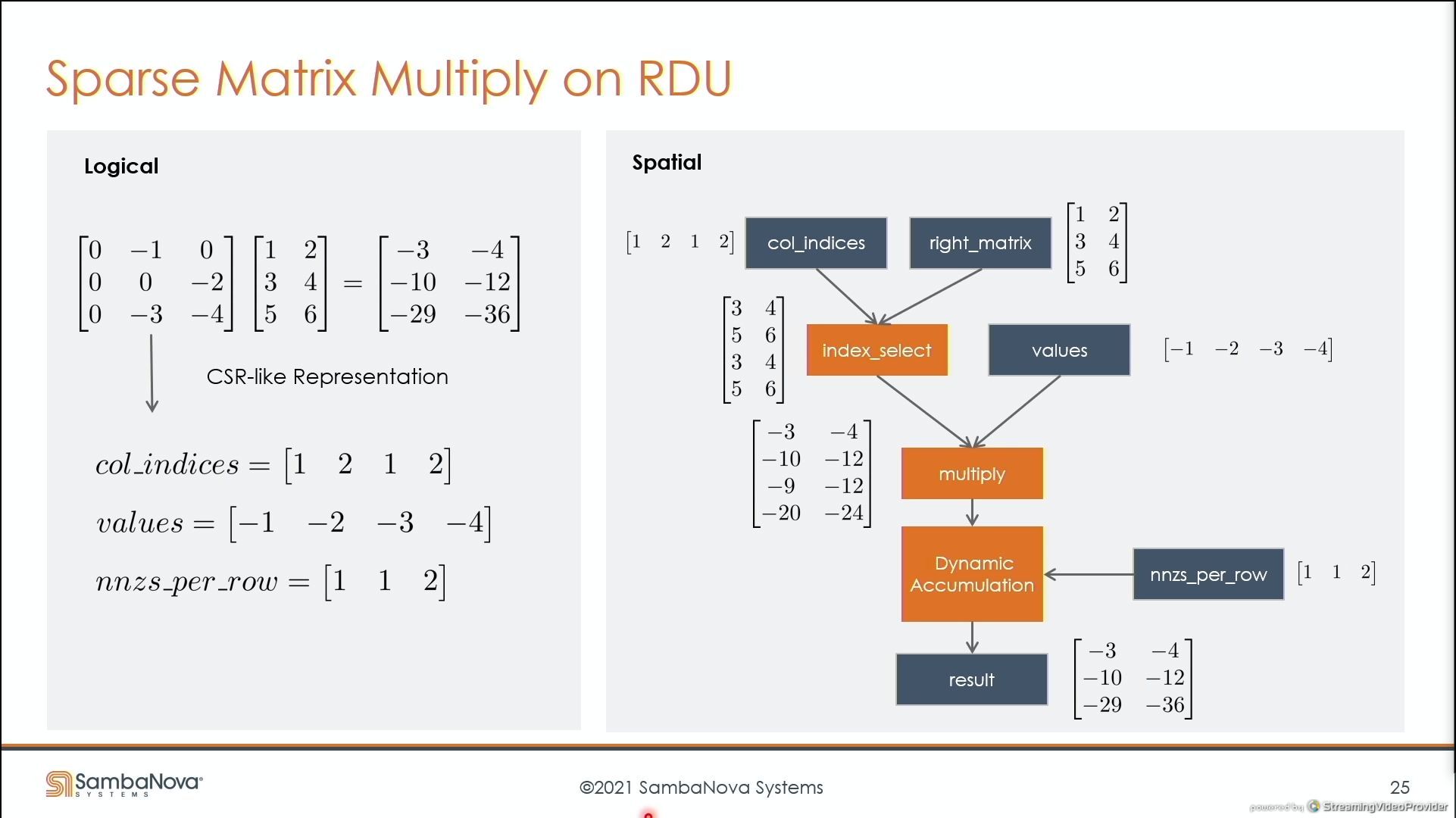
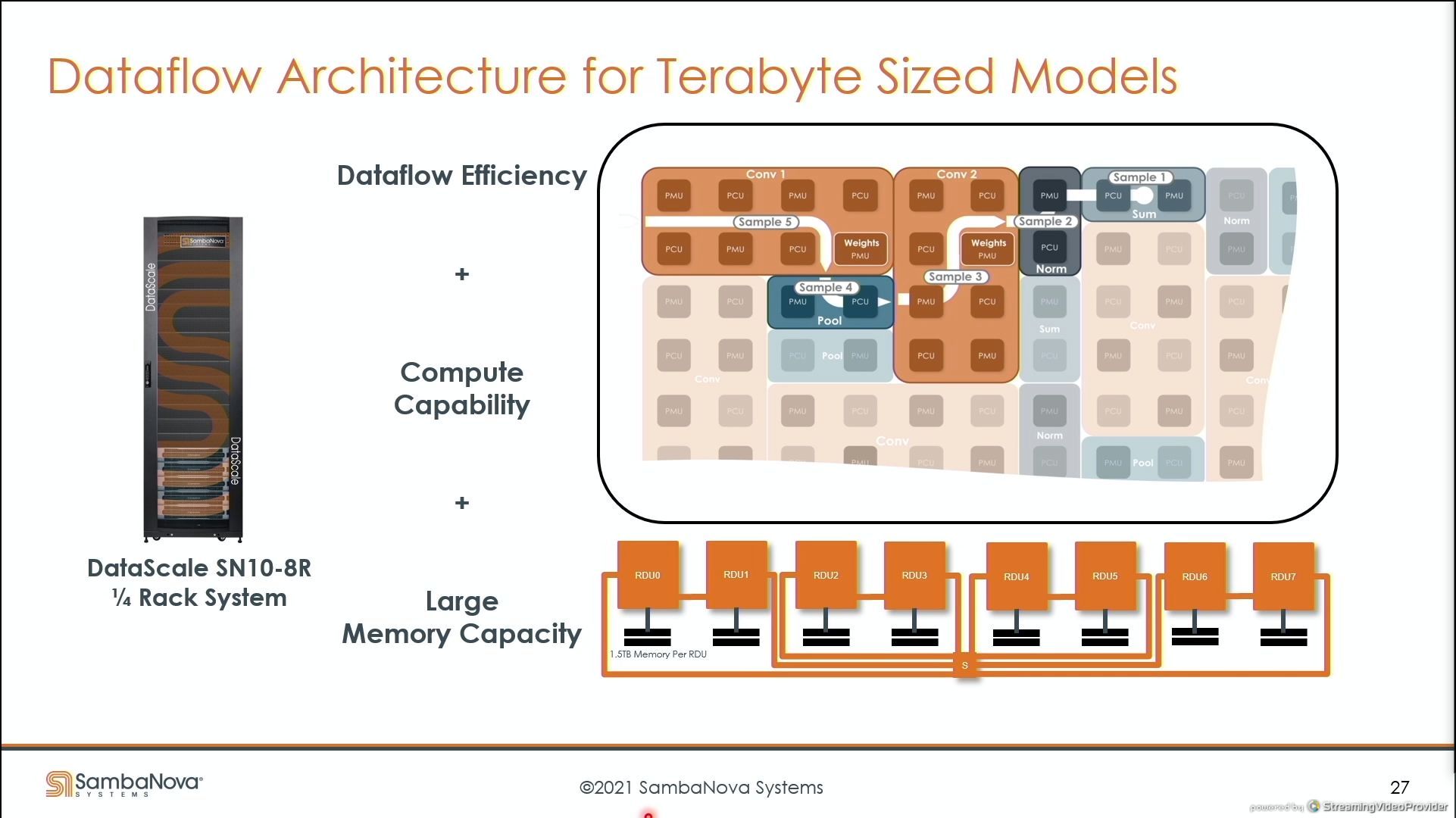
03:54PM EDT - 1.5 TB of DDR4 per chip
03:55PM EDT - 12 TB of DRAM for 8 chips per quarter rack - smallest compute unit for sale
03:55PM EDT - Interleaving in a finegrained manner to be used in proportion
03:56PM EDT - Schedule compiler optimizations
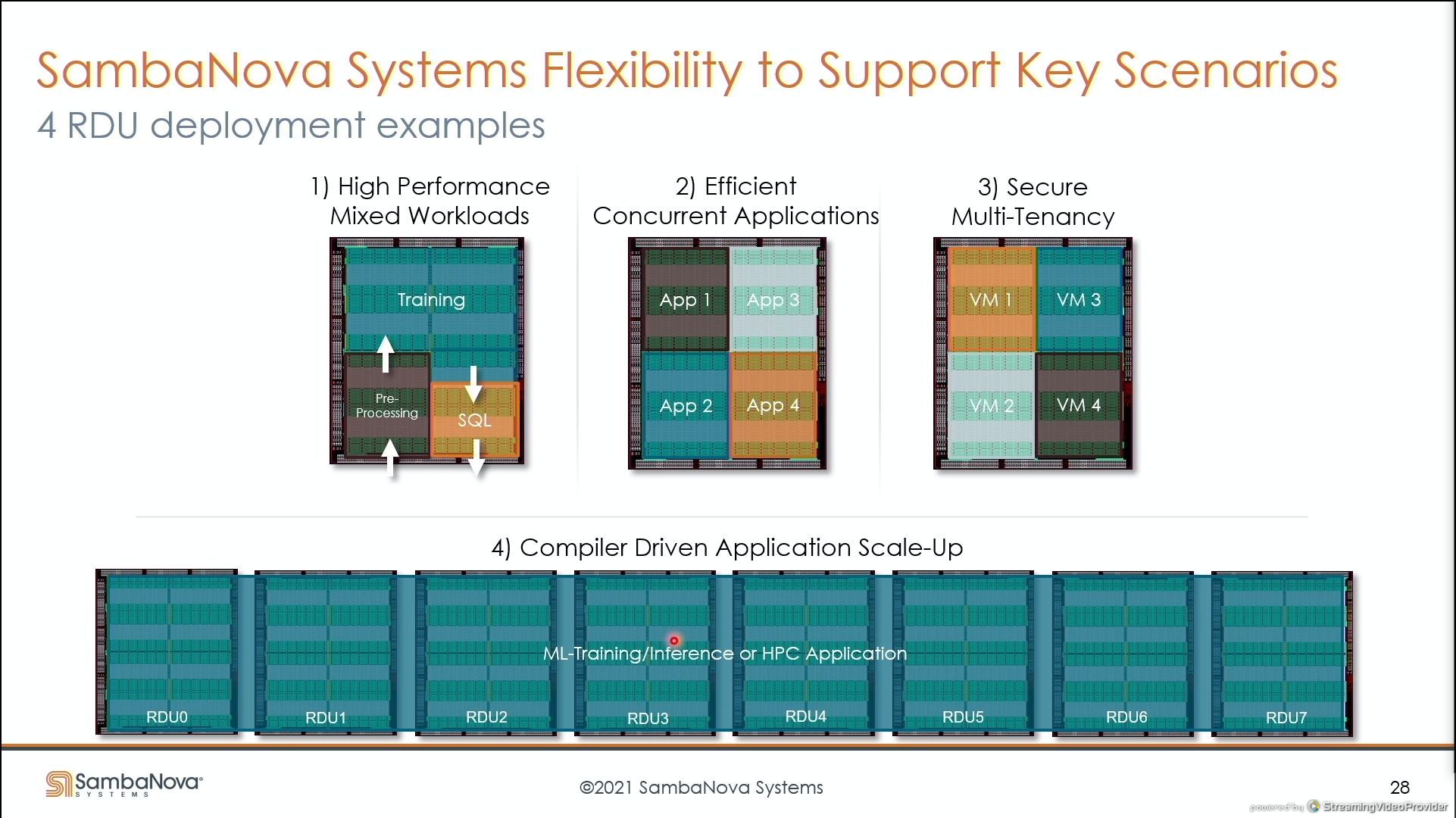
03:58PM EDT - Run multiple applications on each node
03:58PM EDT - Simple scale out

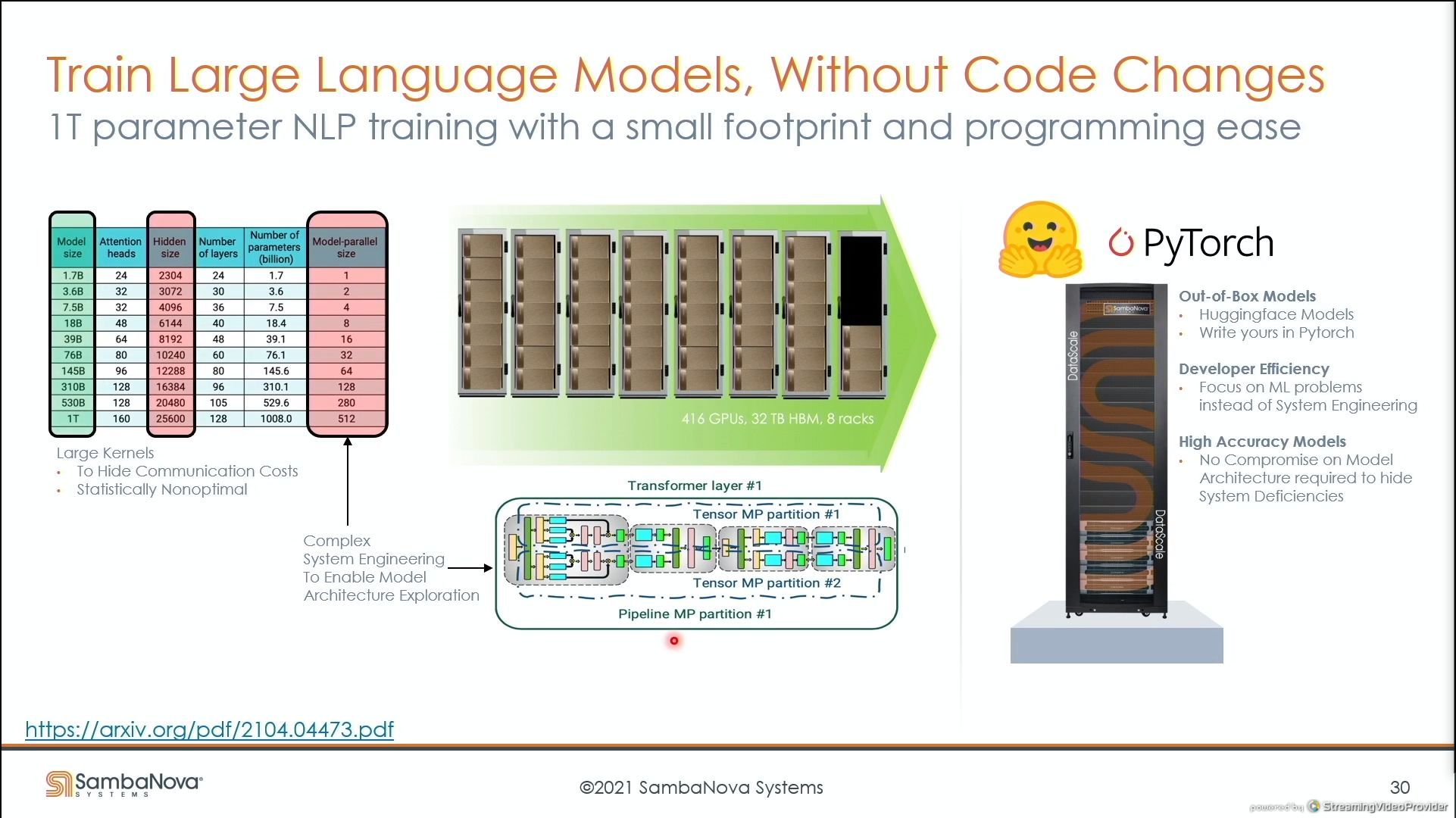
03:59PM EDT - one quarter rack replaces 416 GPUs with 32 TB of HBM in 8 racks
03:59PM EDT - 1 trillion parameter NLP (Natural Language. Processing) training

04:00PM EDT - Scale up to 50k x 50k medical imaging, support any size model
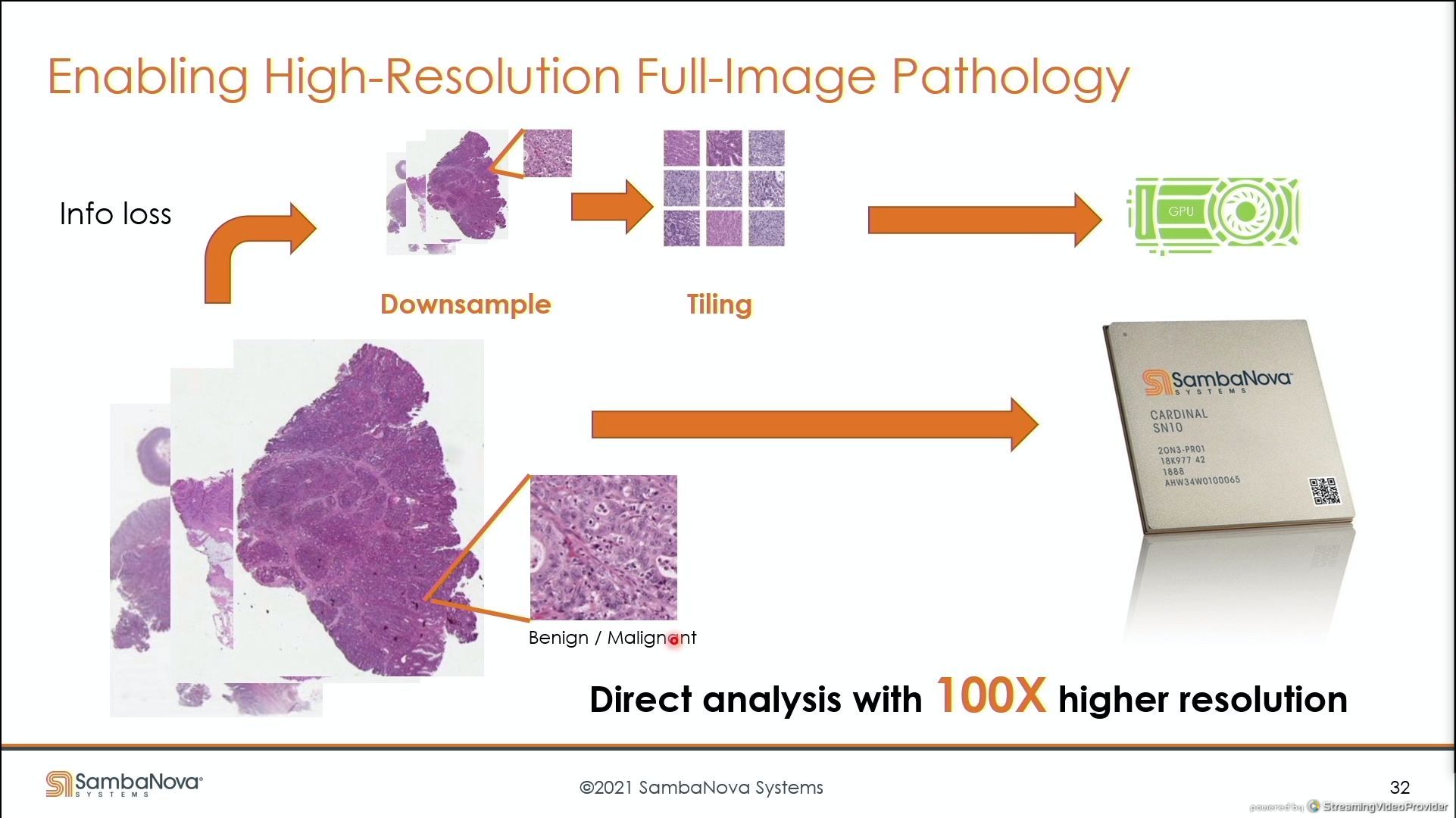
04:01PM EDT - Direct analysis on SambaNova

04:01PM EDT - First models in late 2019
04:02PM EDT - full resolution with RDU
04:02PM EDT - raising problems across the board
04:03PM EDT - raising performance across the board*
04:04PM EDT - Q&A time
04:05PM EDT - Q: Bandwidth at switches A: enough to sustain high streaming throughput - more than what you thing, '150+ TB/s' - 50 km of wire just for that
04:05PM EDT - How long does it take to compile?
04:06PM EDT - A: Quick. BERT Large - a minute or two. GPT-175b, one segment and replicates, starting to go to same time
04:07PM EDT - Q: Mem bandwidth A: six channels per RDU, DDR4-2666 to DDR4-3200 - 48 channels total in a quarter rack
04:08PM EDT - Q: Train a 1T model estimate? A: Depends on the dataset. What matters to us is efficiency.
04:08PM EDT - Now time for Anton ASIC 3
04:09PM EDT - DE Shaw Resarch

04:10PM EDT - Fire breathing monster

04:10PM EDT - Molecular Dynamics simulationm
04:11PM EDT - Almost static snapshots - but atoms move
04:11PM EDT - molecules move!
04:11PM EDT - MD allows modelling
04:12PM EDT - Requires knowing the atom position of molecule and atoms in matrix

04:12PM EDT - discrete timesteps of a few femtoseconds
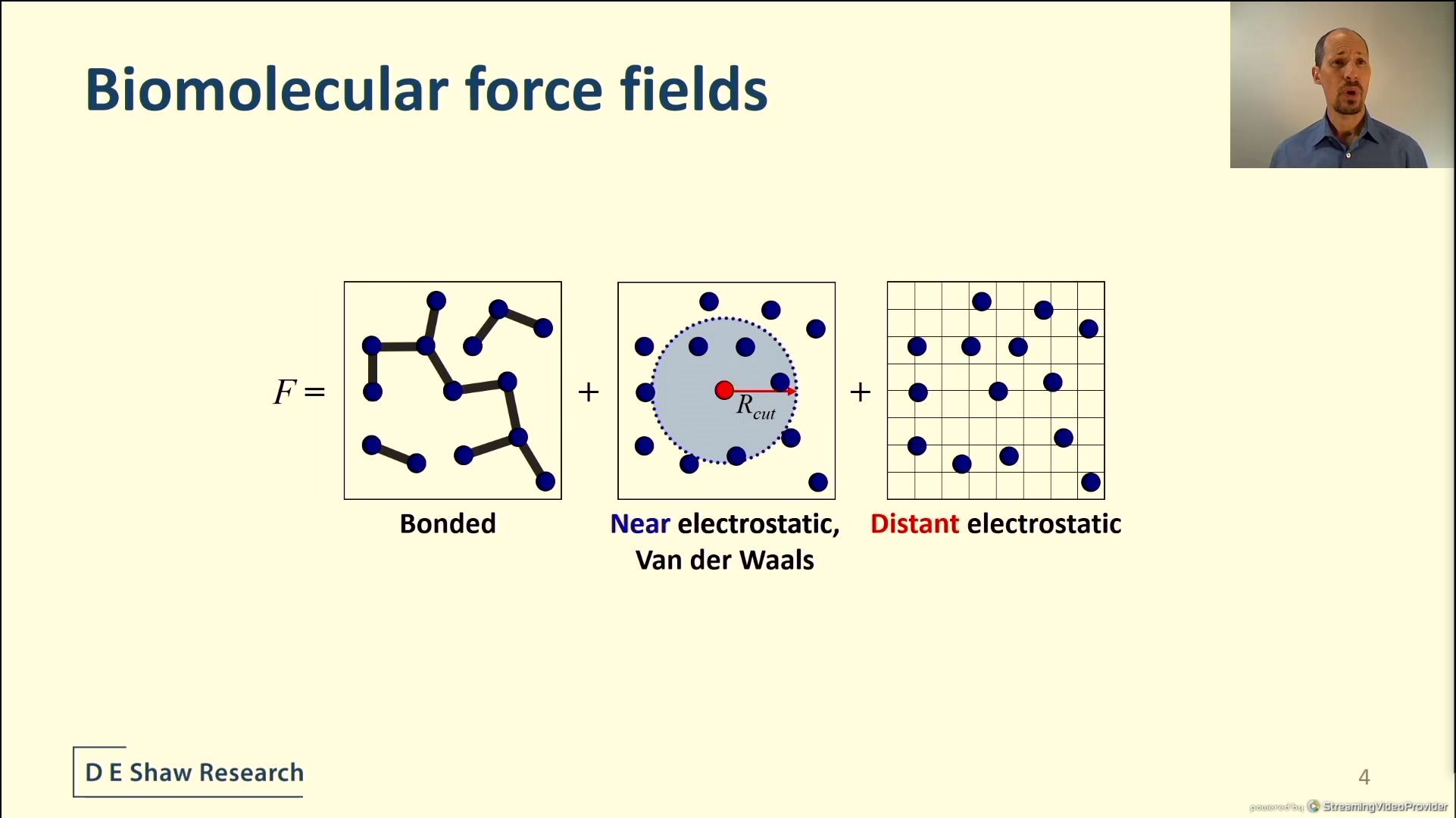
04:12PM EDT - Force computation described by a model
04:13PM EDT - Forces = bonds + vdW + electrostatics
04:13PM EDT - Intractable to rediculous compute
04:14PM EDT - millisecond scale protein simulation from Anton 1
04:14PM EDT - Anton 2 vastly increased performance

04:14PM EDT - It's all about the color of the logo

04:14PM EDT - Here's Anton 2, made on Samsung
04:14PM EDT - Custom ASIC
04:14PM EDT - Two kinds of computational tile
04:15PM EDT - Flex tile, high-throughput interaction subsystem
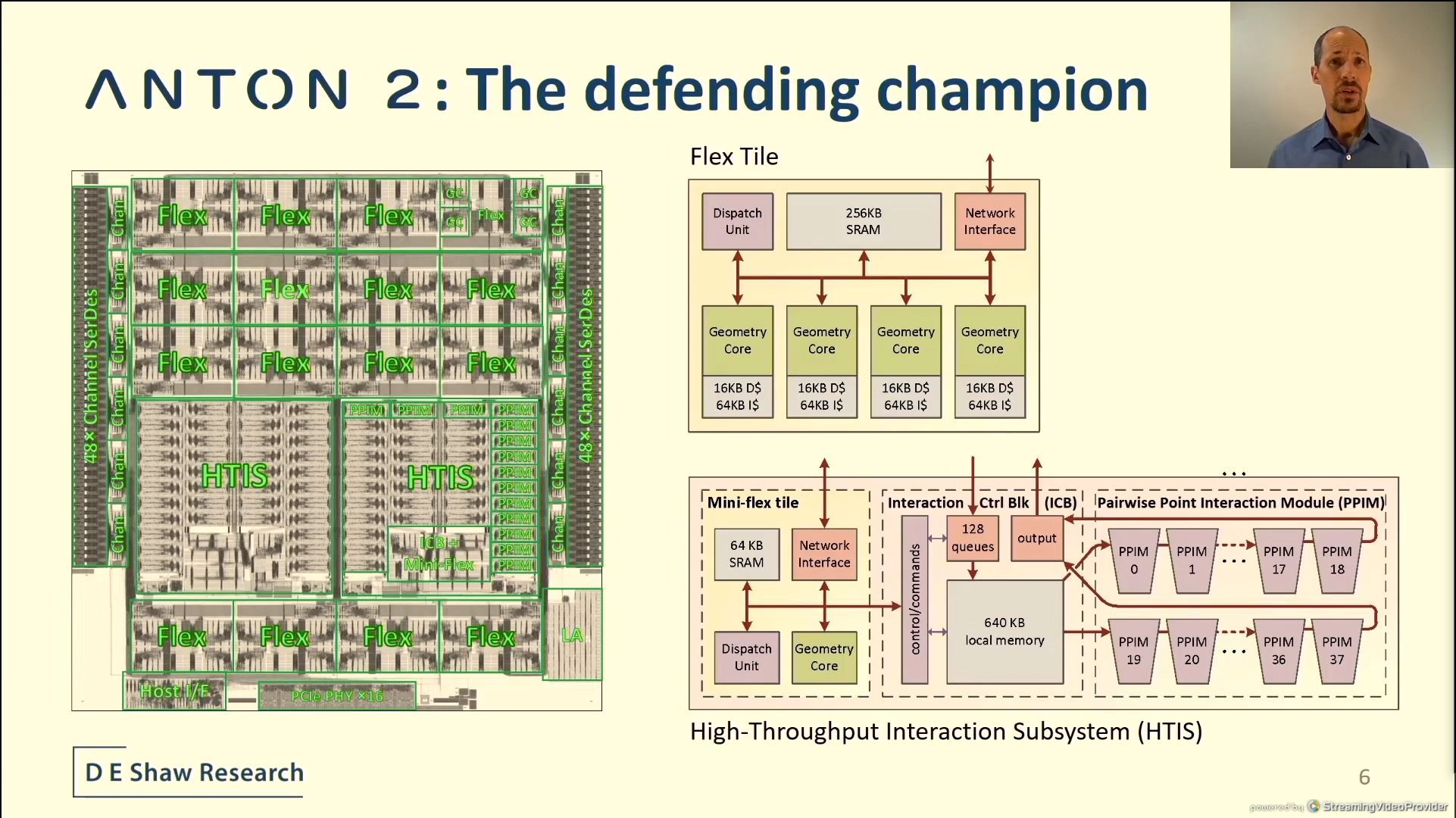
04:15PM EDT - PPIM have unrolled arithmetic pipelines
04:16PM EDT - Periphery is the serdes to connect multiple chips together
04:16PM EDT - To make it better, need to scale PPIMs and Geometry cores
04:16PM EDT - Also address performance bottlenecks - such as scaling off chip bandwidth
04:16PM EDT - Also increasing simulation size support

04:17PM EDT - Control the design and implementation
04:17PM EDT - Anton 3 core tile
04:17PM EDT - Central router
04:17PM EDT - Same GC and PPIM as Anton 2 but with evolutions
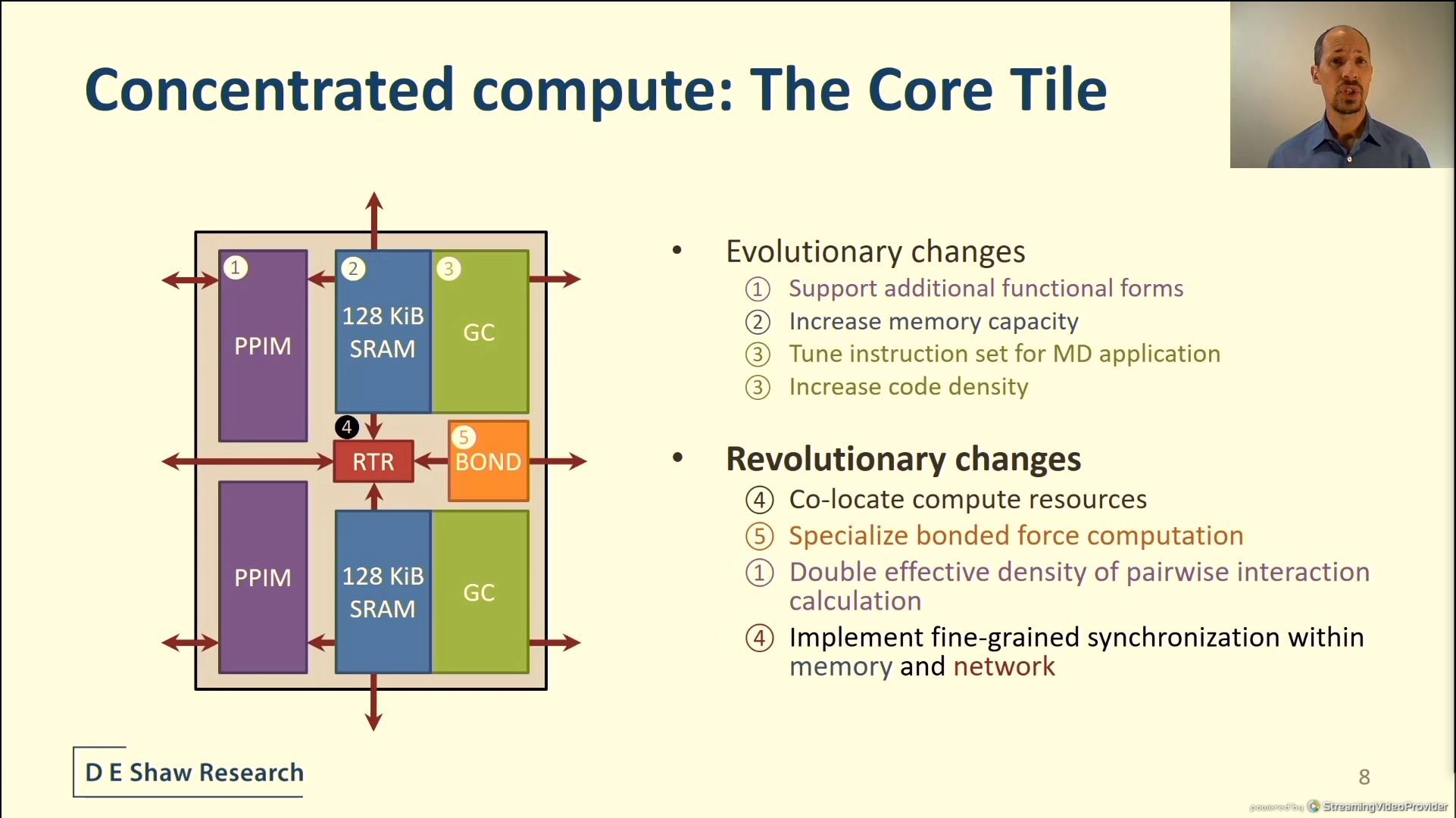
04:18PM EDT - co-location of specialized compute resources
04:18PM EDT - Sync functionality is disributed

04:19PM EDT - Bond length calculators and angle

04:19PM EDT - Dedicated hardware
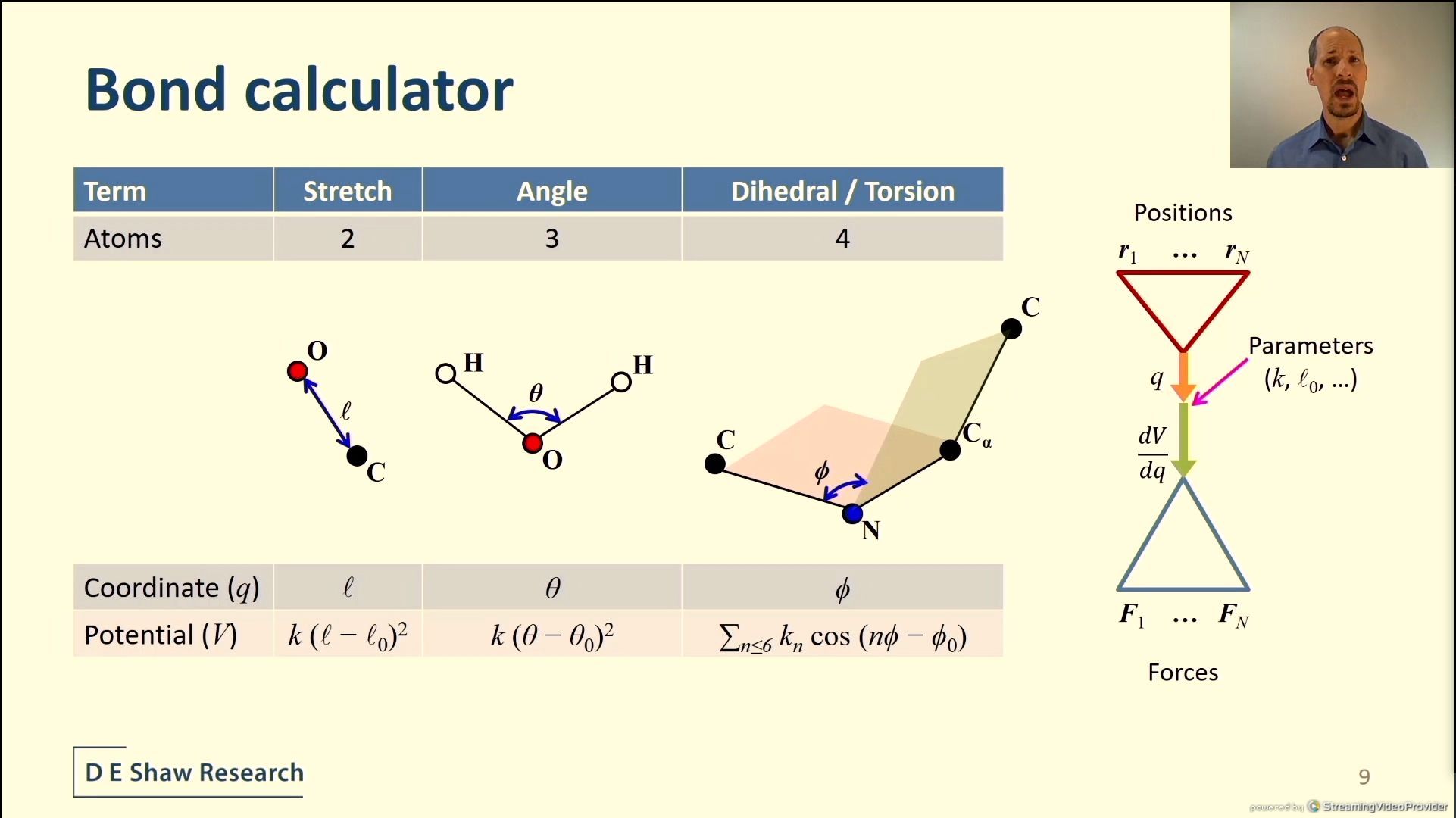
04:20PM EDT - ANTON3 keeps bond calculation off the critical path
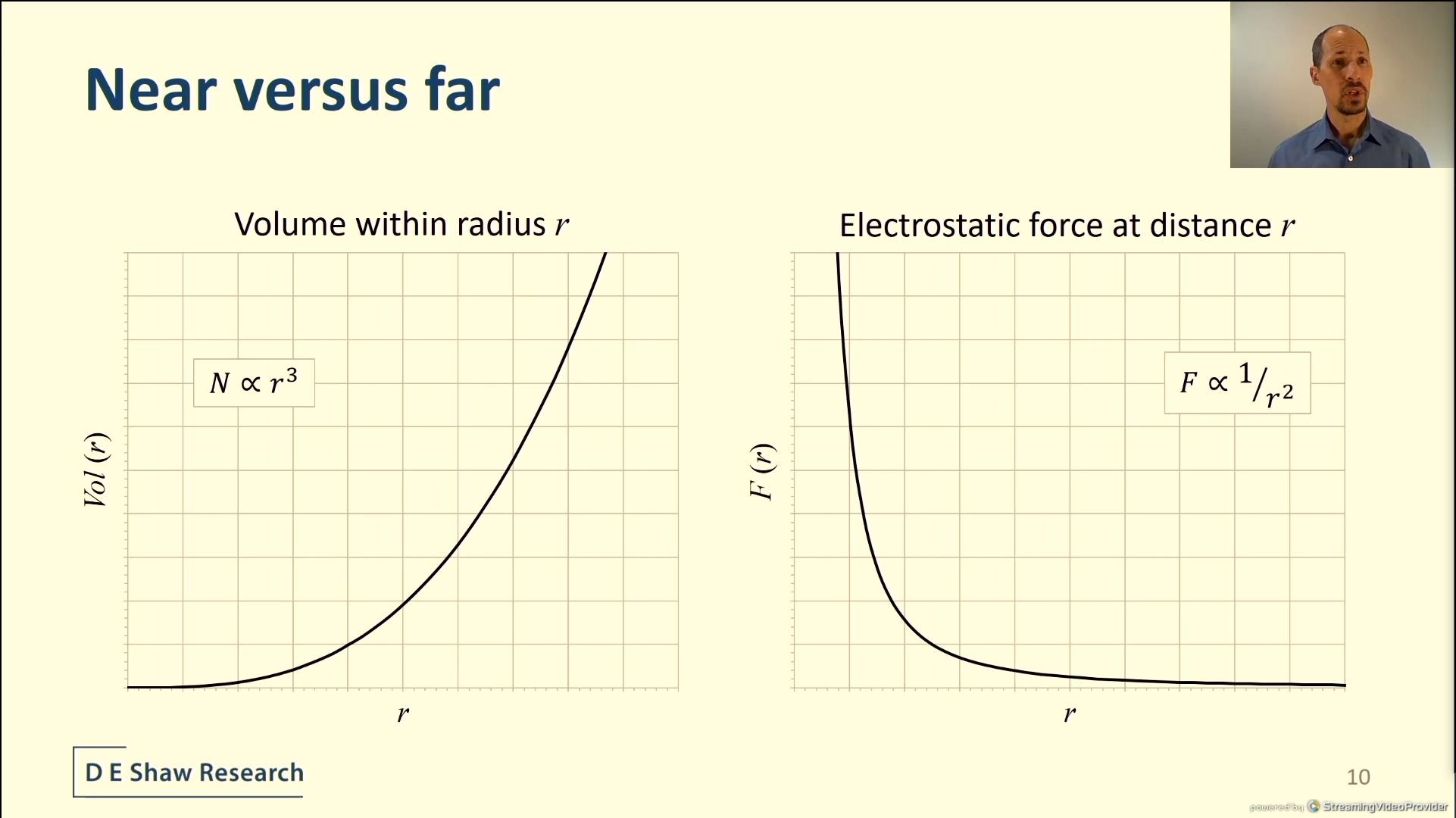
04:20PM EDT - Force calculations get hardware with size
04:21PM EDT - Solution is to partition near and far calculations
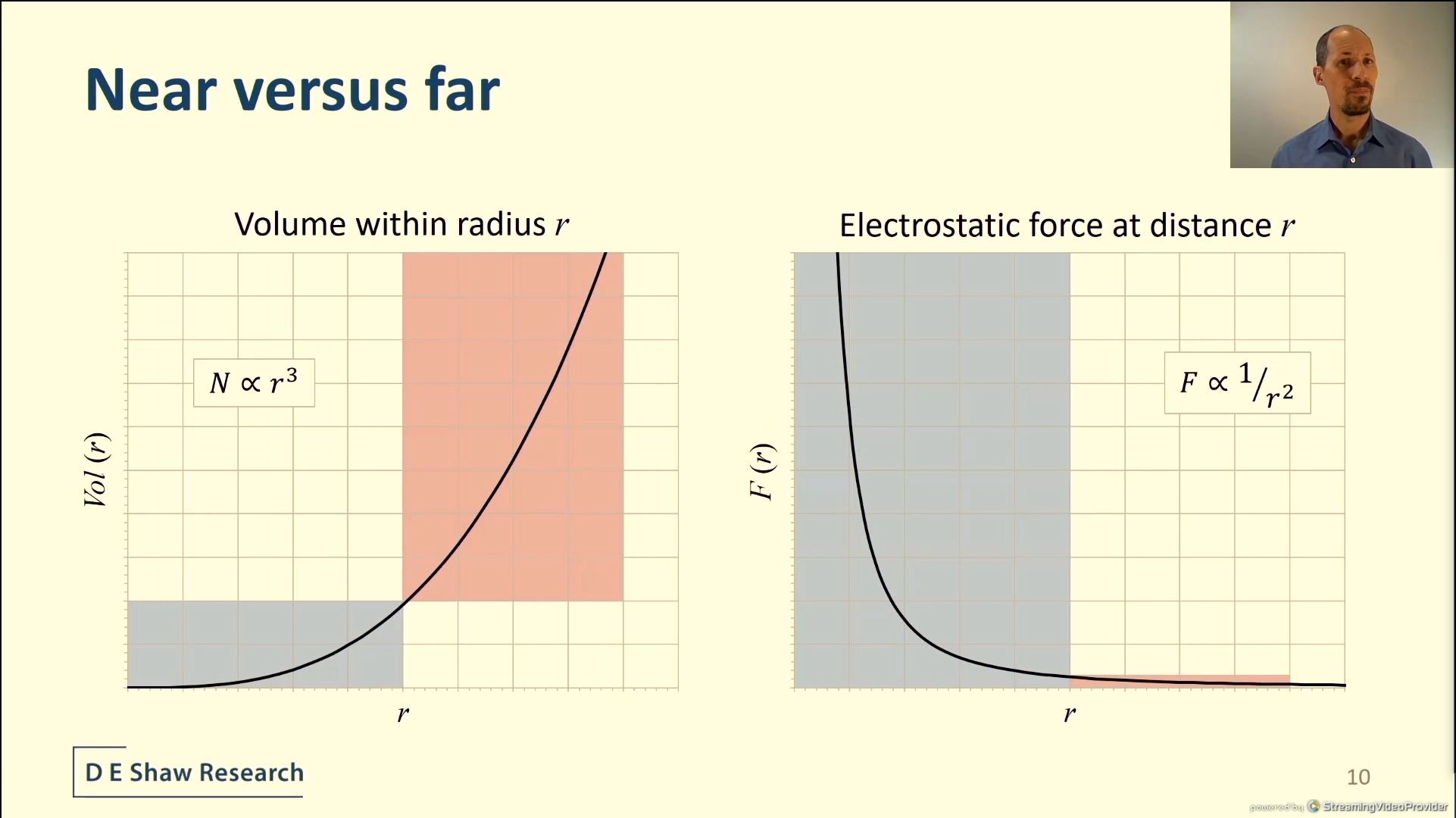
04:21PM EDT - dedicated hardware for both
04:22PM EDT - Also Edge tile
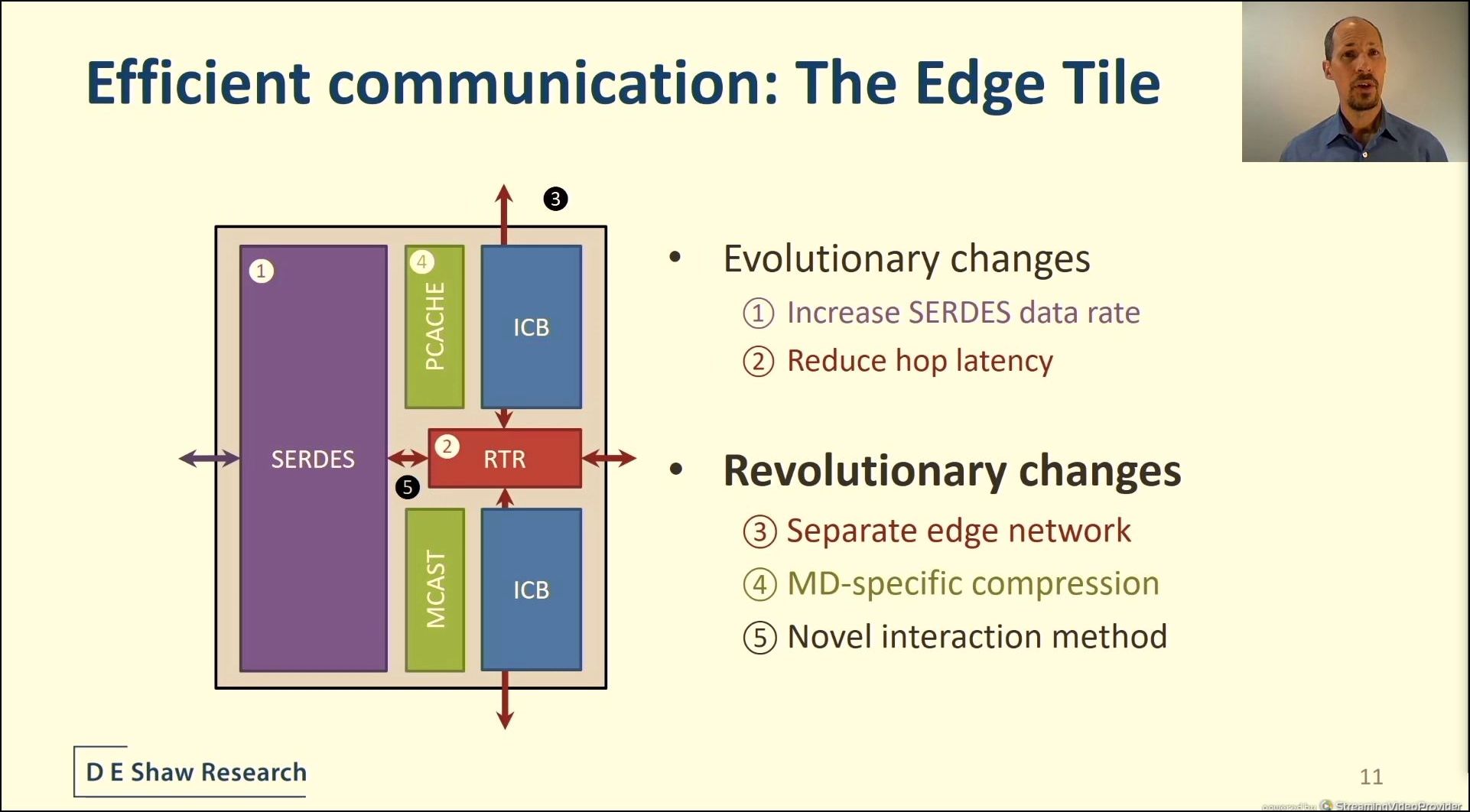
04:22PM EDT - simplifying communications
04:22PM EDT - separate edge network
04:22PM EDT - MD-specific compression
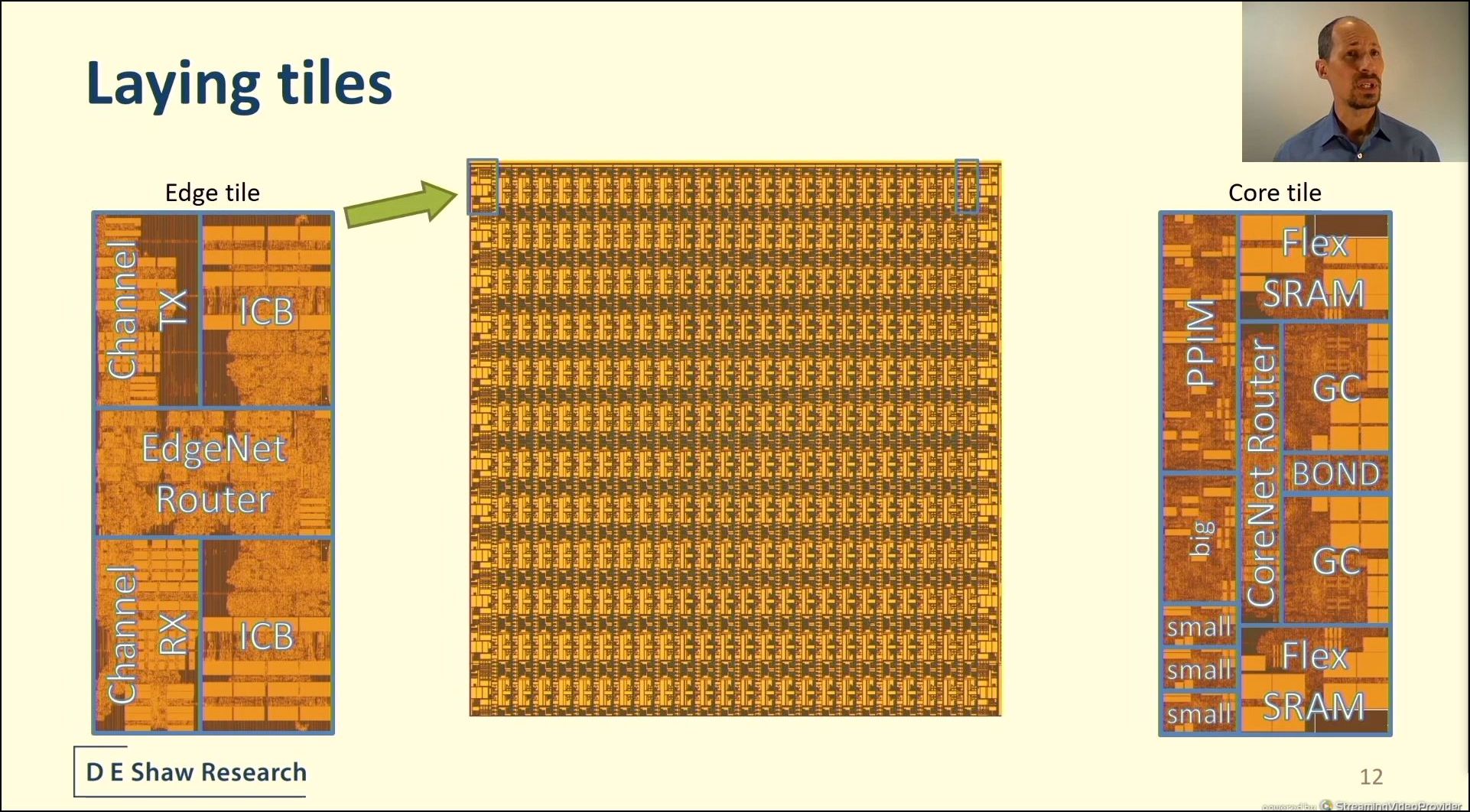
04:25PM EDT - global low skew clock mesh - engineered global routing
04:25PM EDT - Column level redundancy
04:25PM EDT - Robust power delivery
04:25PM EDT - MIMCAP
04:25PM EDT - Top layers almost exclusive for power
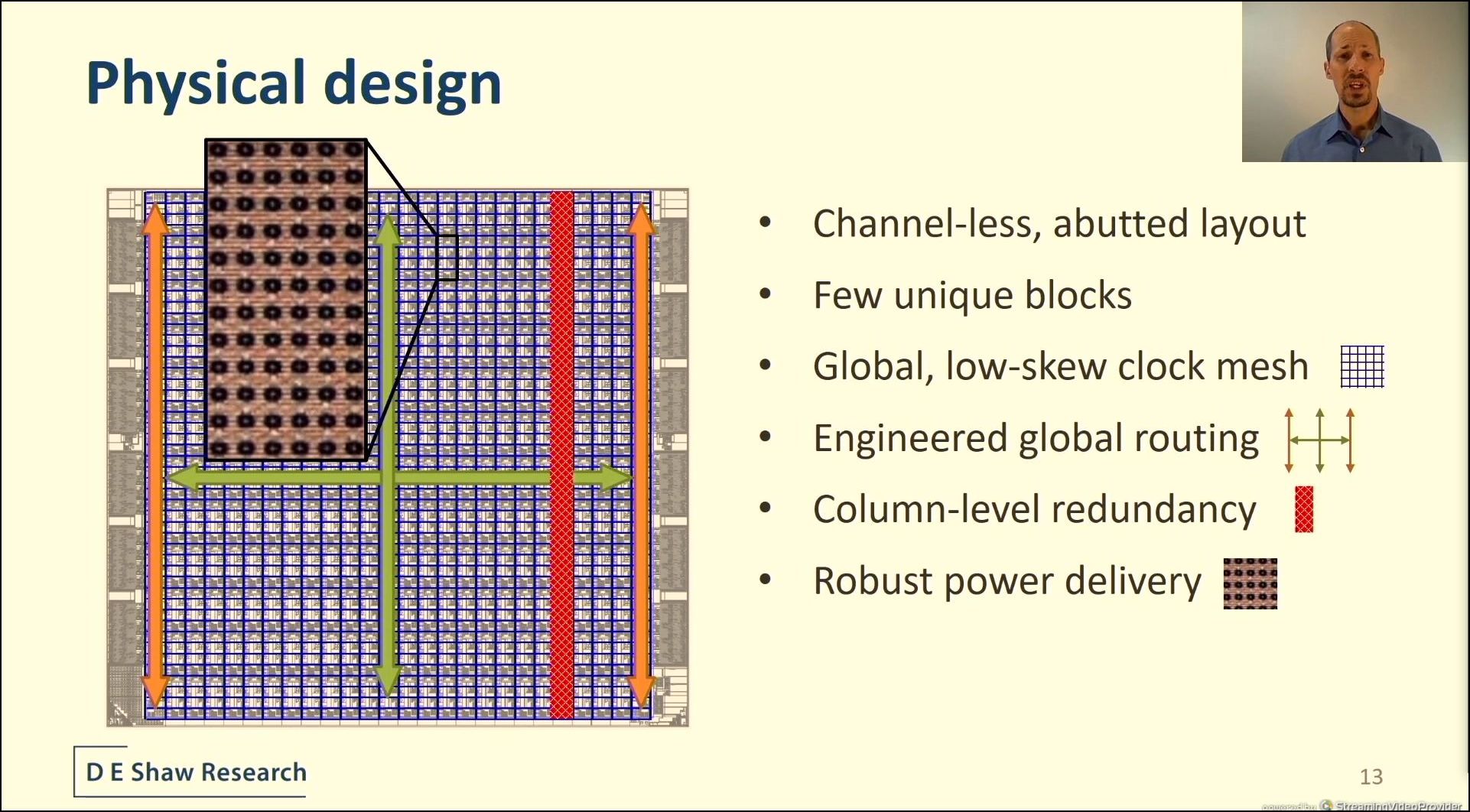
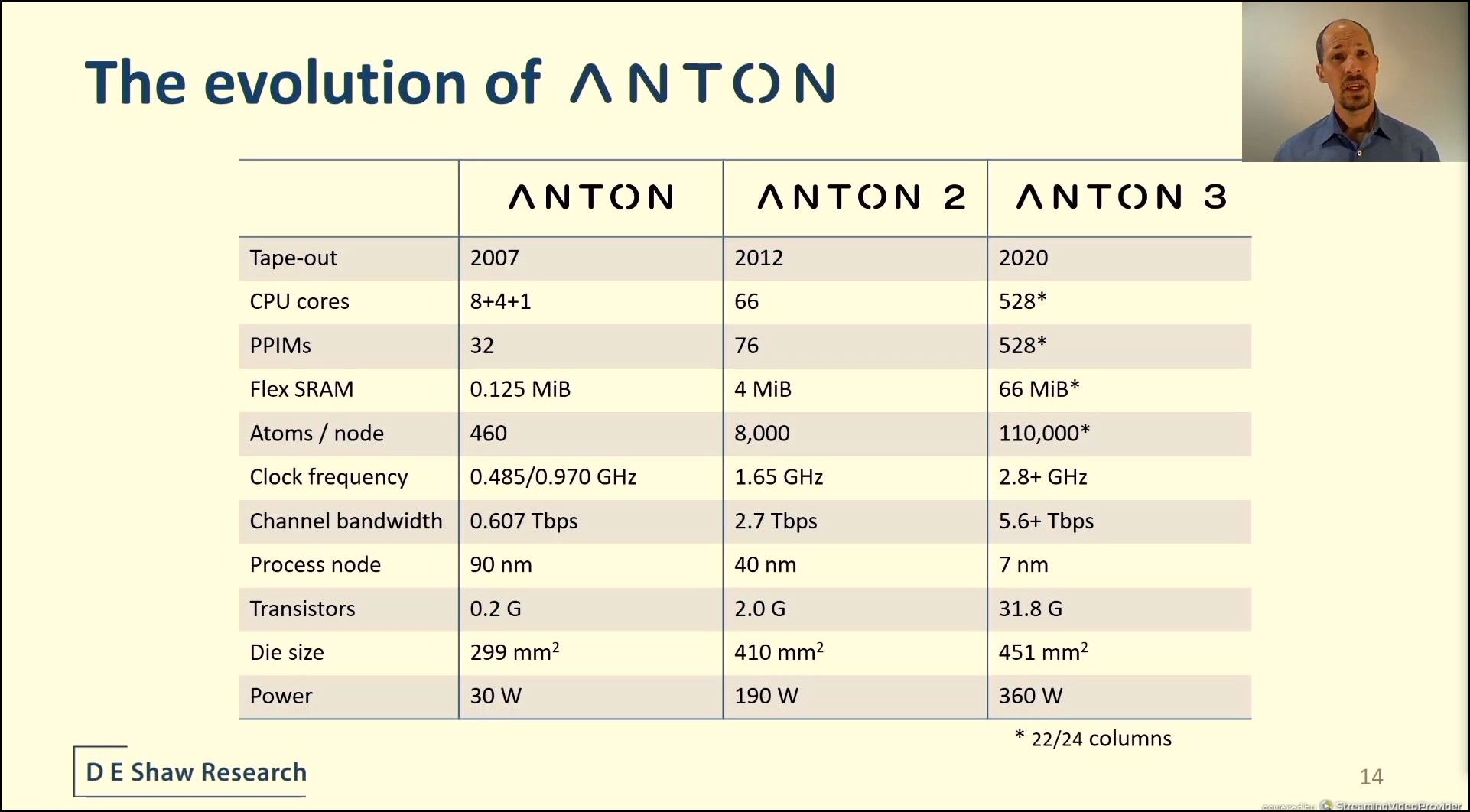
04:26PM EDT - 360 W for 451 mm2 on TSMC 7nm at 2.8 GHz
04:26PM EDT - 110k atoms per node, 528 cores
04:26PM EDT - 31.8 billion transistores

04:27PM EDT - Running simulations within 9 hours of first silicon

04:27PM EDT - Node boards
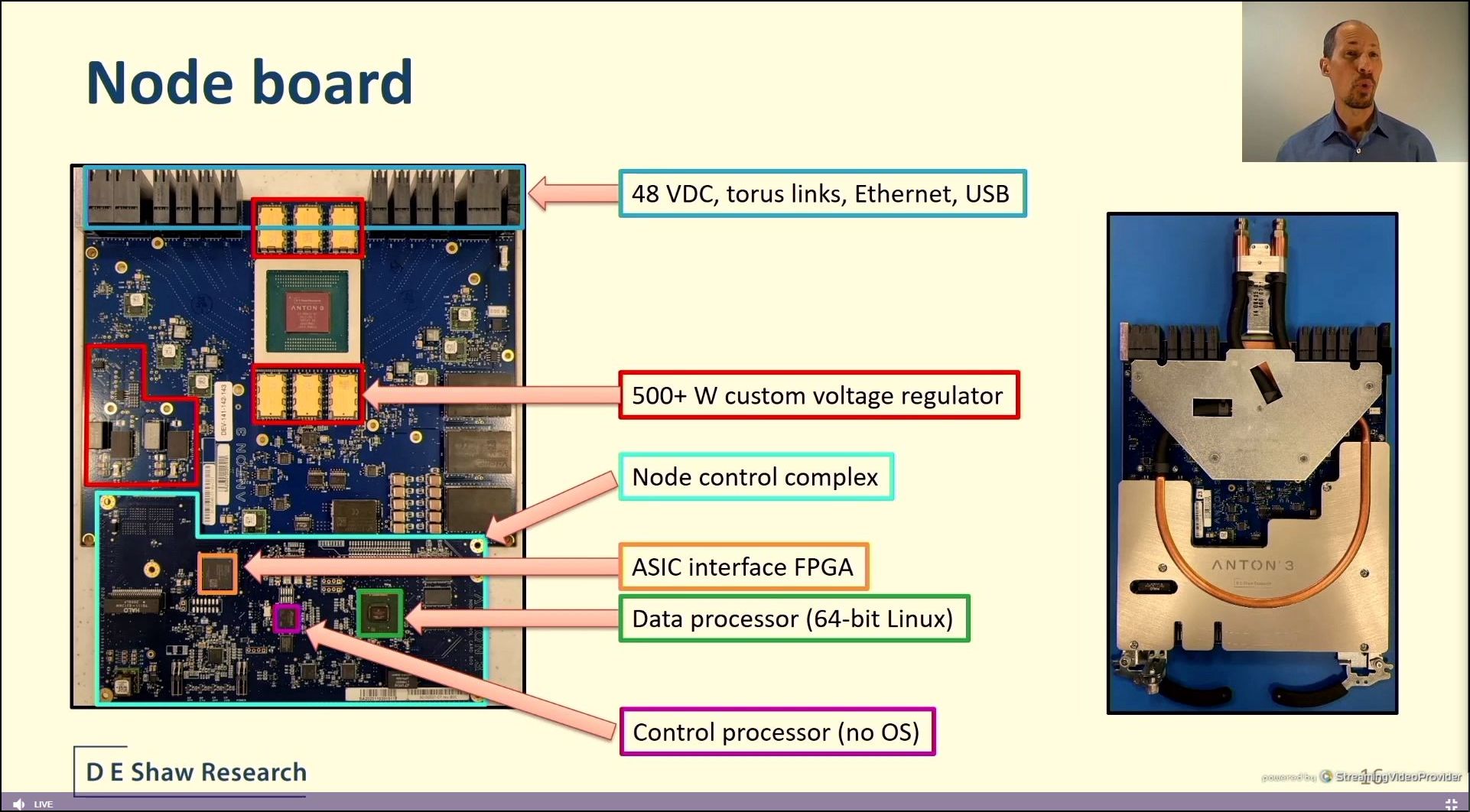
04:28PM EDT - 32 node boards in cages
04:29PM EDT - 128 nodes in a rack
04:29PM EDT - 512 nodes in 4 racks
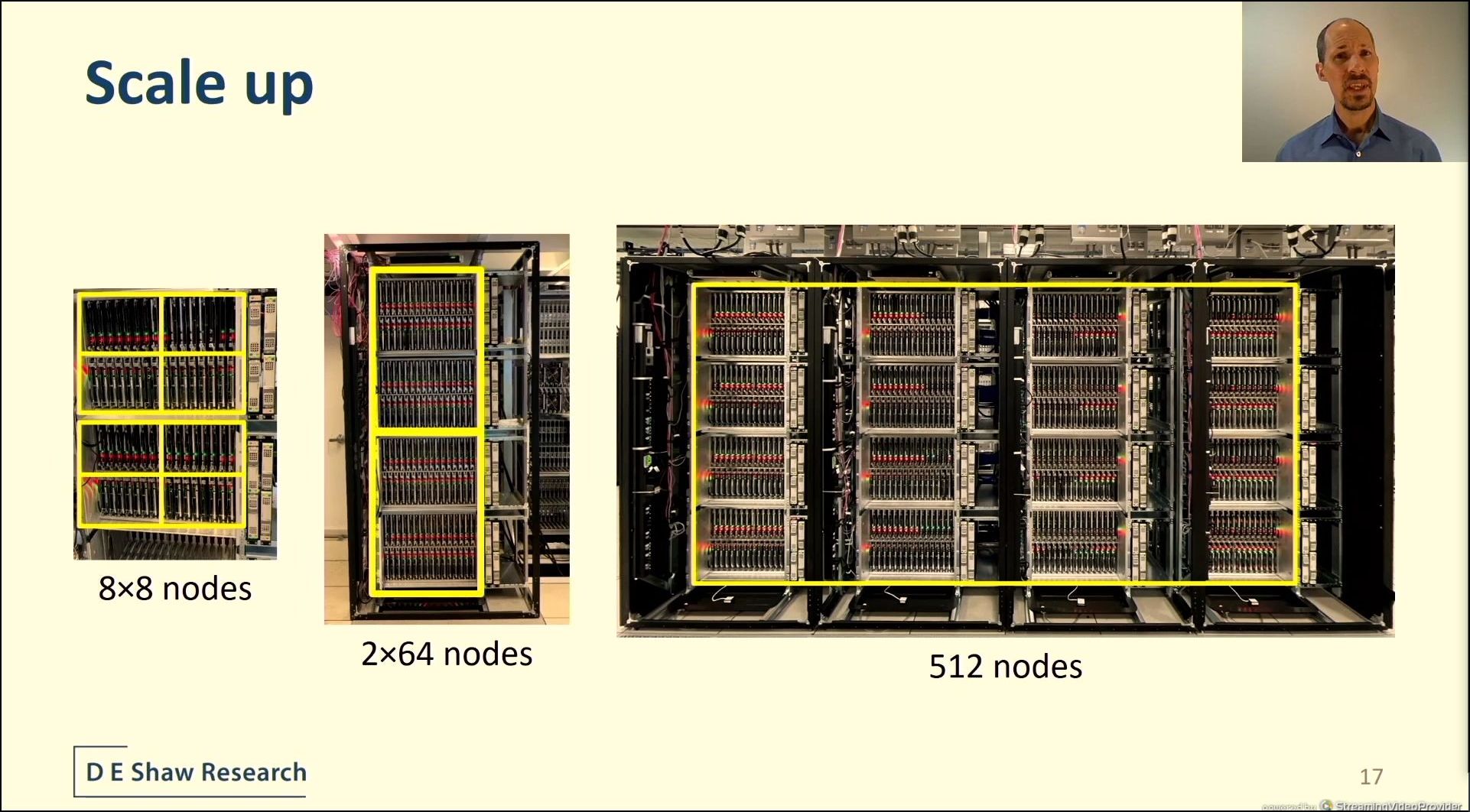
04:29PM EDT - unique backplane
04:29PM EDT - 16 bidirectional links
04:29PM EDT - X dimension in the backplane
04:29PM EDT - 3D torus
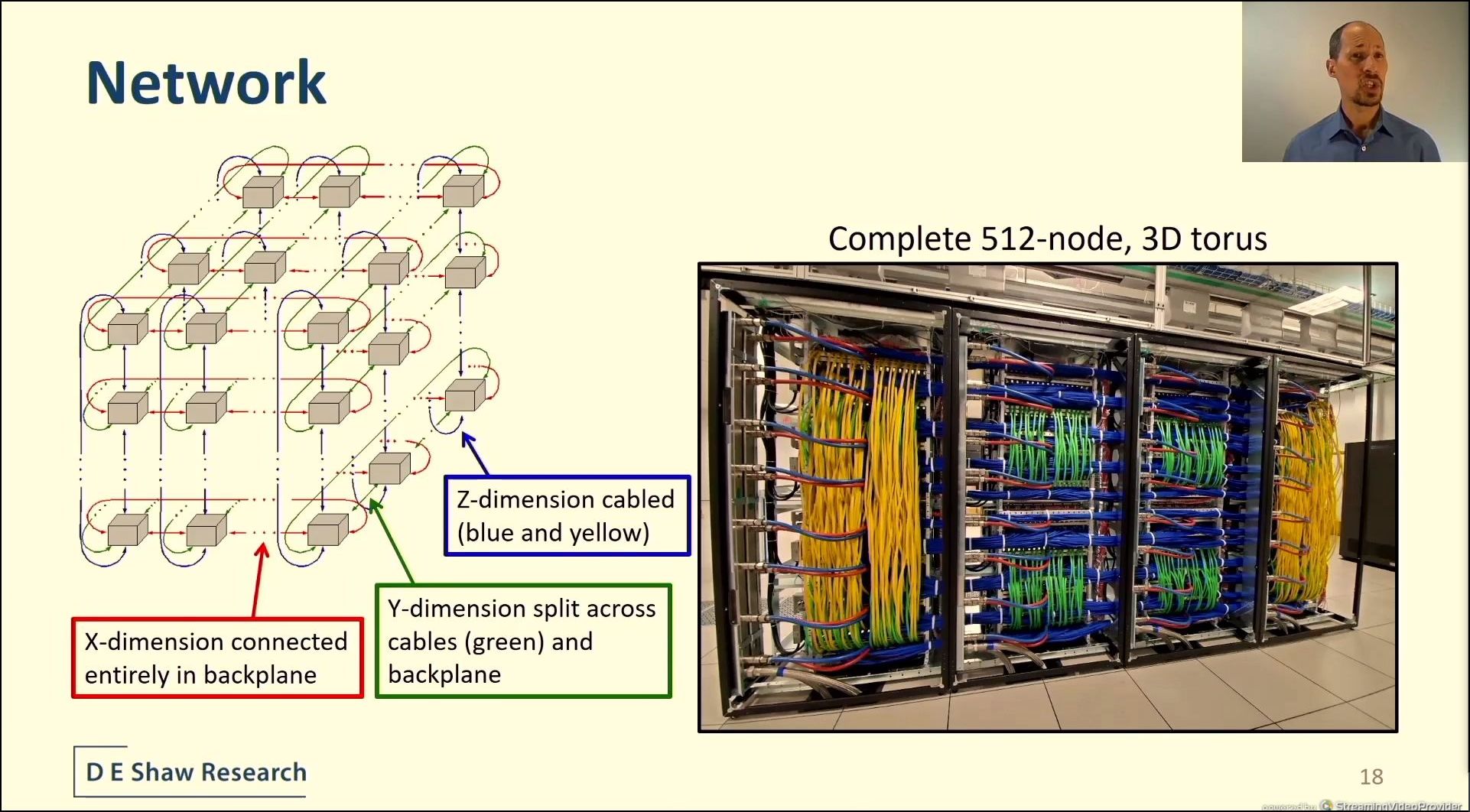
04:30PM EDT - Liquid cooling with CDU and quick release fittings
04:30PM EDT - 100 kW per rack

04:31PM EDT - ASIC power of 500W
04:31PM EDT - Anton 3 is 20x faster than A100 using hand optimized NVIDIA code for the same simulation
04:32PM EDT - one Anton 3 beats a 512-node Anton 1
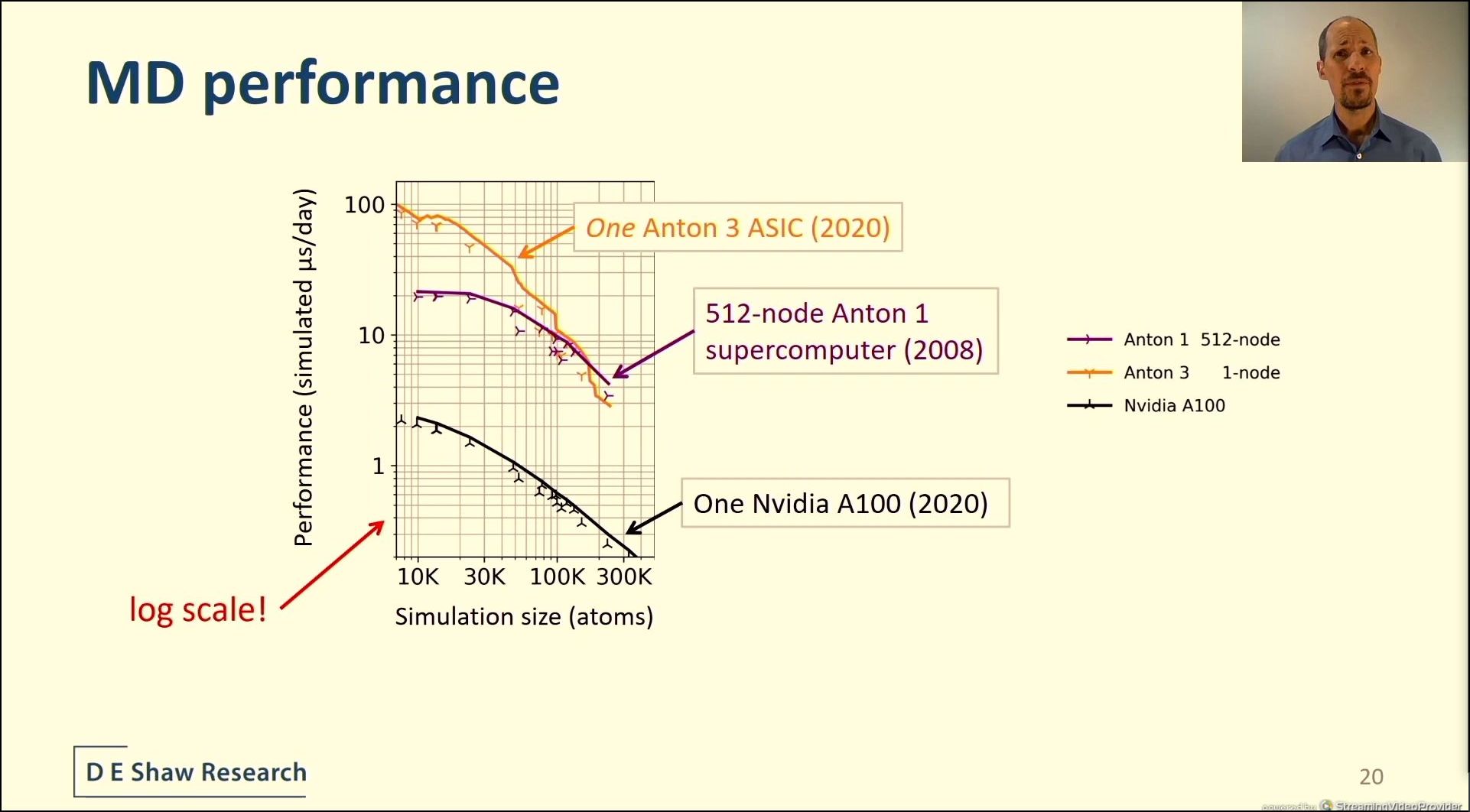
04:32PM EDT - 100 microseconds per day
04:33PM EDT - Multiple GPUs doesn't help, perf is lower!
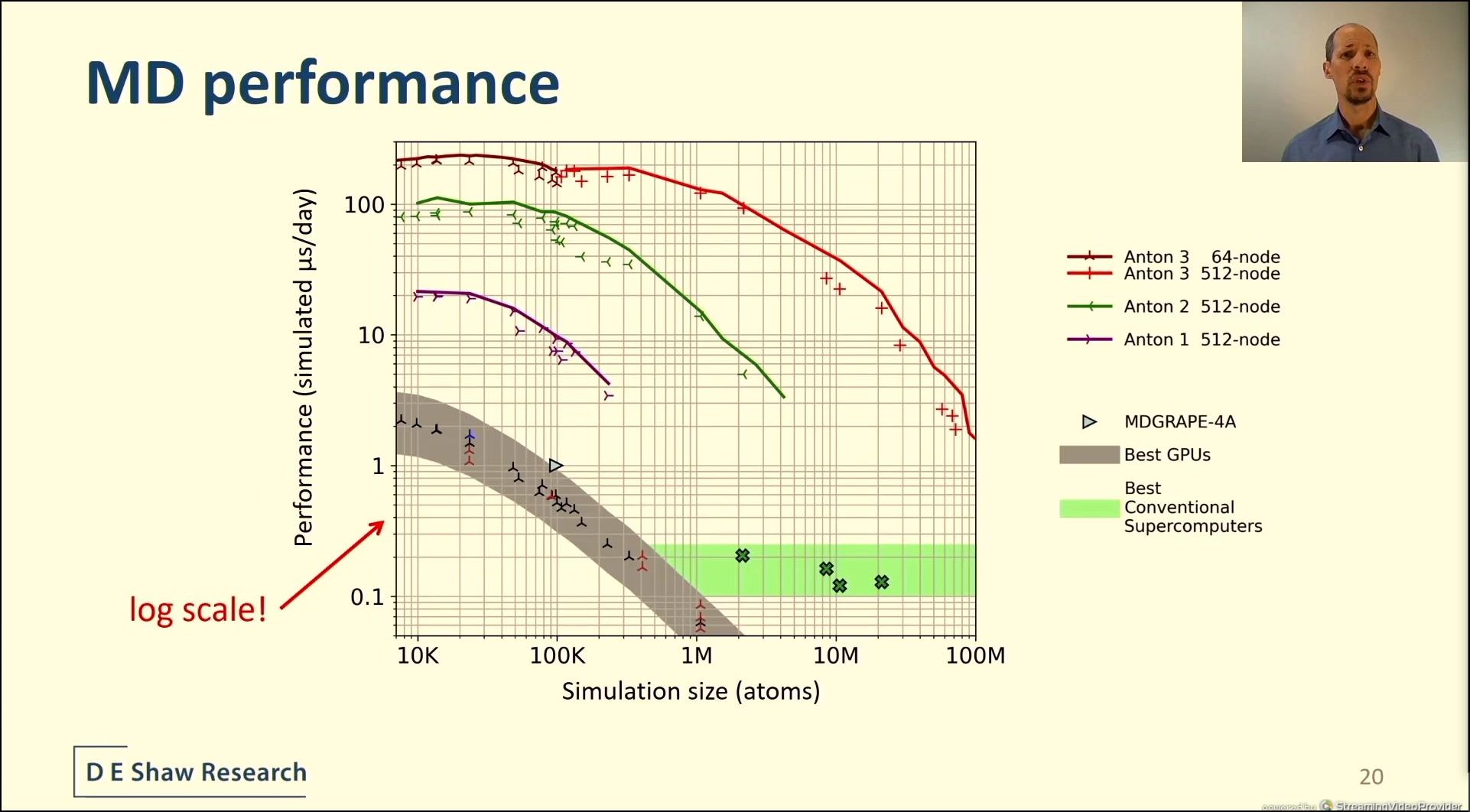
04:33PM EDT - This is insane performance

04:35PM EDT - Q&A
04:36PM EDT - Q: Can you apply the hardware to other workloads? A: Broad set of MD related workloads. Haven't put much energy beyond that, some interesting internal projects though
04:37PM EDT - Q: What numerical formats used in Anton 3? A: 32 fixed point in general pipeline - specialised varies, some areas is 14-bit mantissa/5bit exponents, some is log
04:38PM EDT - Q: Power management. All of the pins are available for power and ground - DVFS control methods? A: No DVFS, do some ad-hoc dynamic frequency scaling through ramp limiters. Haven't needed to use them
04:39PM EDT - Q: is the mesh high power? A: difficult trade off vs mesochronous - we chose to do a unified common predriver clock tree onto a shared message for low latency. Out of 360W chip, 40-50W is mesh power
04:40PM EDT - Q: Advanced packaging? A: Ecosystem wasn't there yet when we were architecting - this took 8 years to build. Next time around, we're looking into it
04:41PM EDT - Q: Can you scale beyond 512 nodes? A: Hardware can scale more than 512 at network and link layer. Machine is designed to run at most 512 nodes. Larger installs could run multiple simulations and shared data.
04:42PM EDT - Q; What interconnect speeds? A: NRZ Serdez - dual unidirectional - 29-30 gigabit/sec, still being tuned. No need for FEC
04:45PM EDT - That's a wrap








3 Comments
View All Comments
WaltC - Tuesday, August 24, 2021 - link
Cerebras WSE-2: I can only wonder about the yields...;) And what you'd plug this behemoth into! 2.6 trillion transistors. Also, I would suggest the CEO might want to give serious thought to doing something about his last name in terms of his company, as "Lie" is not exactly a word which inspires trust, imo.Ian Cutress - Thursday, August 26, 2021 - link
Yield is 100%, they have failover built into the silicon to absorb defects. Also don't be so culturally ignorant on names.Speedfriend - Monday, August 30, 2021 - link
How do these all compare to the Tesla chip.announcement